| 번호 | 청구항 |
|---|---|
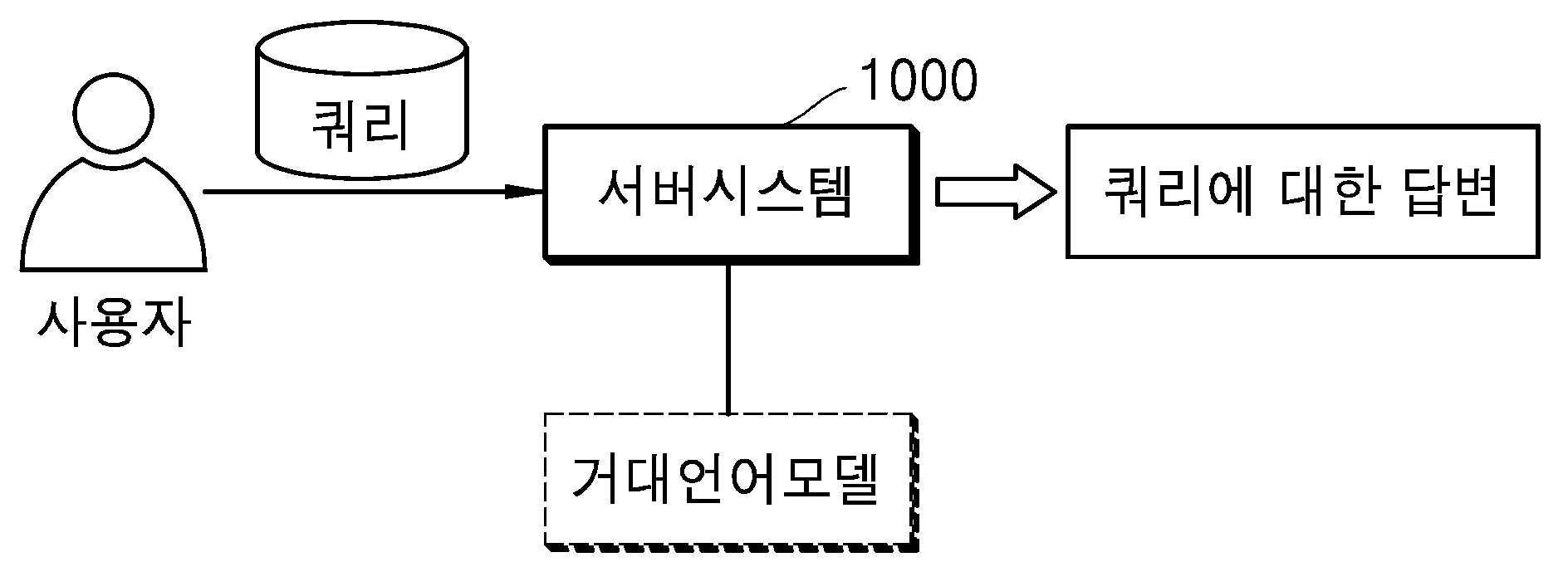
| 1 | 1 이상의 프로세서 및 1 이상의 메모리를 포함하는 서버시스템에서 수행되는, 거대언어모델을 이용한 법안 및 정책에 대한 분석정보를 제공하는 방법으로서,법안 혹은 정책에 대한 쿼리를 사용자단말로부터 수신하여 임베딩하는 쿼리수신단계;상기 쿼리에 대한 임베딩과 데이터베이스에 저장된 복수의 문서 각각에 대한 임베딩간의 제1유사도를 산출하는 제1유사도산출단계;산출된 제1유사도에 기반하여 상기 데이터베이스에 저장된 복수의 문서 중에서 복수의 대상문서를 도출하는 대상문서도출단계;도출된 대상문서에 포함된 1 이상의 부분요소 각각과 상기 쿼리간의 제2유사도를 산출하는 제2유사도산출단계;산출된 제2유사도에 기반하여 상기 1 이상의 부분요소 중에서 제1유효부분요소를 도출하는 제1유효부분요소도출단계;도출된 제1유효부분요소가 포함된 대상문서에 대한 메타정보; 및 해당 제1유효부분요소에 대하여 산출된 제2유사도;에 기초하여 1 이상의 제1유효부분요소 각각에 대한 우선순위를 산정하는 순위산정단계;산정된 우선순위가 기설정된 순위기준 내에 상응하는 제1유효부분요소를 제2유효부분요소로서 도출하는 제2유효부분요소도출단계; 및상기 제2유효부분요소 및 상기 쿼리를 포함하는 프롬프트를 거대언어모델에 입력하고, 상기 거대언어모델로부터 출력되는 법안 혹은 정책에 대한 분석정보를 상기 사용자단말로 제공하는 분석정보제공단계;를 포함하고,상기 제2유사도산출단계는,자연어에 대하여 특화되어 기학습된 BERT모델을 통해 상기 제1유효부분요소와 상기 쿼리의 제1모델유사도를 산출하는 제1모델유사도산출단계;법안 및 정책에 대하여 특화되어 기학습된 Domain-BERT모델을 통해 상기 제1유효부분요소와 상기 쿼리의 제2모델유사도를 산출하는 제2모델유사도산출단계; 및상기 제1모델유사도 및 상기 제2모델유사도 각각에 상이하게 기설정된 가중치를 적용하고, 상기 제1모델유사도 및 상기 제2모델유사도의 가중평균으로 상기 쿼리와 상기 제1유효부분요소간의 제2유사도를 산출하는 가중평균산출단계;를 포함하고,상기 메타정보는 데이터베이스에 저장된 복수의 문서 각각에 대하여 출처를 포함하는 출처정보; 및 발행일자를 포함하는 발행정보;를 포함하고,상기 순위산정단계는,해당 대상문서에 대한 출처별 가점이 일대일 형태로 매칭되어 있는 출처가점테이블에 따라 기설정된 메타점수에 제1가점을 부여하는 제1가점부여단계;해당 대상문서에 대한 발행일자의 최신 정도에 비례하는 제2가점을 해당 메타점수에 부여하는 제2가점부여단계; 및상기 1 이상의 제1유효부분요소 각각에 대하여 최종적으로 산출된 메타점수 및 제2유사도 각각에 상이하게 기설정된 가중치를 적용하여 합산한 값에 따라 상기 우선순위를 산정하는 스코어산출단계;를 포함하고,상기 출처가점테이블은 출처의 공신력 및 신뢰도에 따라 제1가점이 매칭되는, 분석정보를 제공하는 방법. |