| 번호 | 청구항 |
|---|---|
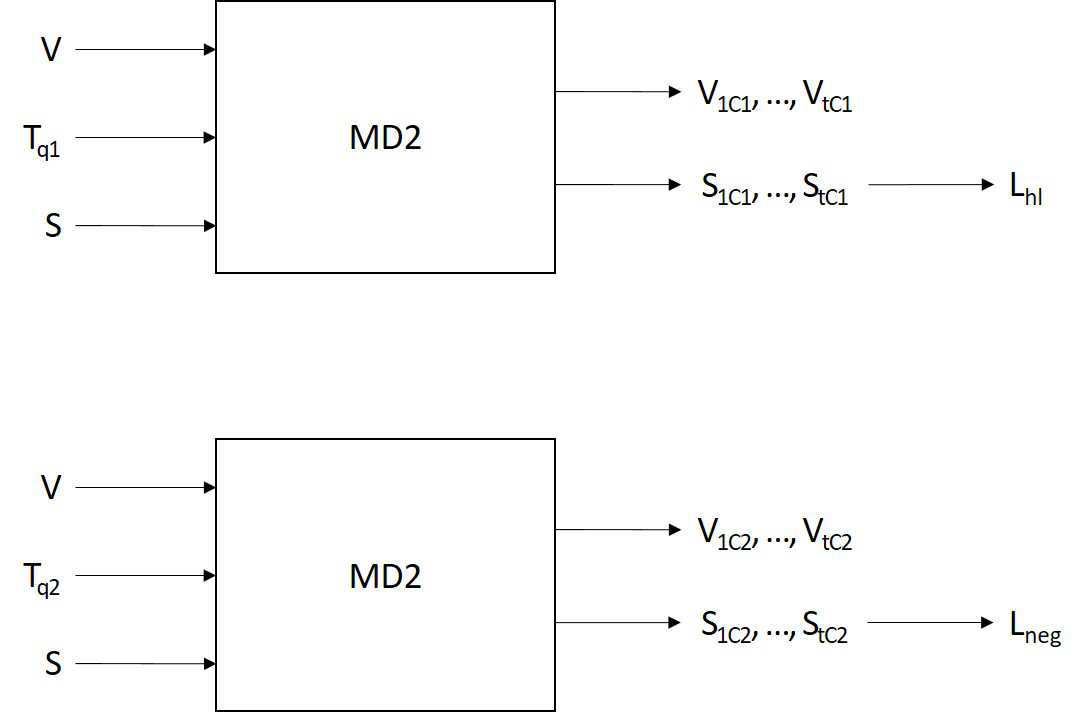
| 1 | 저장부; 및프로세서;를 포함하고,상기 프로세서는,크로스-어텐션 모델을 이용해, 복수의 동영상 클립 및 제1 텍스트 쿼리로부터 복수의 제1 동영상 특징을 획득하고,트랜스포머 인코더를 이용해, 상기 복수의 제1 동영상 특징 및 제1 중요도 토큰(Saliency Token)으로부터 복수의 제2 동영상 특징, 제2 중요도 토큰 및 상기 제1 텍스트 쿼리에 대한 상기 복수의 동영상 클립 중 적어도 하나의 동영상 클립의 적어도 하나의 제1 중요도(Saliency Score)를 획득하고,상기 크로스-어텐션 모델을 이용해, 상기 복수의 동영상 클립 및 제2 텍스트 쿼리로부터 복수의 제3 동영상 특징을 획득하고,상기 트랜스포머 인코더를 이용해, 상기 복수의 제3 동영상 특징 및 상기 제1 중요도 토큰으로부터 복수의 제4 동영상 특징, 제3 중요도 토큰 및 상기 제2 텍스트 쿼리에 대한 상기 적어도 하나의 동영상 클립의 적어도 하나의 제2 중요도를 획득하고,상기 제1 중요도는 상기 제2 중요도보다 크고, 상기 제1 중요도가 증가하고 상기 제2 중요도는 감소하도록 상기 크로스-어텐션 모델, 상기 트랜스포머 인코더 및 상기 제1 중요도 토큰을 수정하며,상기 제1 텍스트 쿼리는 상기 적어도 하나의 동영상 클립과 양의 쌍이며,상기 제2 텍스트 쿼리는 상기 적어도 하나의 동영상 클립과 음의 쌍인, 동영상 장면 검색 및 하이라이트 검출 중 적어도 하나를 학습하기 위한 전자 장치. |
| 2 | 제1 항에 있어서,상기 프로세서는, 상기 크로스-어텐션 모델을 이용해,상기 복수의 동영상 클립에 대한 복수의 동영상 특징으로부터 복수의 동영상 쿼리를 획득하고,상기 제1 텍스트 쿼리에 대한 제1 텍스트 쿼리 특징으로부터 제1 텍스트 키를 획득하고,상기 제1 텍스트 쿼리 특징으로부터 제1 텍스트 벨류를 획득하고,상기 복수의 동영상 쿼리, 상기 제1 텍스트 키 및 상기 제1 텍스트 벨류를 이용해 복수의 제1 어텐션 점수를 획득하고, 상기 복수의 제1 어텐션 점수로부터 복수의 제1 가중치를 획득하고, 상기 복수의 제1 가중치 및 상기 복수의 동영상 특징을 각각 곱함으로써 상기 복수의 제1 동영상 특징을 획득하는, 동영상 장면 검색 및 하이라이트 검출 중 적어도 하나를 학습하기 위한 전자 장치. |
| 3 | 제1 항에 있어서,상기 프로세서는, 상기 크로스-어텐션 모델을 이용해,상기 복수의 동영상 클립에 대한 복수의 동영상 특징으로부터 복수의 동영상 쿼리를 획득하고,상기 제2 텍스트 쿼리에 대한 제2 텍스트 쿼리 특징으로부터 제2 텍스트 키를 획득하고,상기 제2 텍스트 쿼리 특징으로부터 제2 텍스트 벨류를 획득하고,상기 복수의 동영상 쿼리, 상기 제2 텍스트 키 및 상기 제2 텍스트 벨류를 이용해 복수의 제2 어텐션 점수를 획득하고,상기 복수의 제2 어텐션 점수로부터 복수의 제2 가중치를 획득하고, 상기 복수의 제2 가중치 및 상기 복수의 동영상 특징을 각각 곱함으로써 상기 복수의 제3 동영상 특징을 획득하는, 동영상 장면 검색 및 하이라이트 검출 중 적어도 하나를 학습하기 위한 전자 장치. |
| 4 | 제1 항에 있어서,상기 프로세서는,제1 완전 연결 층을 통해, 상기 복수의 제2 동영상 특징 중 상기 적어도 하나의 동영상 클립과 대응하는 적어도 하나의 동영상 특징으로부터 적어도 하나의 제1 출력값을 획득하고,제2 완전 연결 층을 통해, 상기 제2 중요도 토큰으로부터 제2 출력값을 획득하고,상기 적어도 하나의 제1 출력값과 상기 제2 출력값을 내적하여 상기 적어도 하나의 제1 중요도를 획득하는, 동영상 장면 검색 및 하이라이트 검출 중 적어도 하나를 학습하기 위한 전자 장치. |
| 5 | 제1 항에 있어서,상기 프로세서는,제1 완전 연결 층을 통해, 상기 복수의 제4 동영상 특징 중 상기 적어도 하나의 동영상 클립과 대응하는 적어도 하나의 동영상 특징으로부터 적어도 하나의 제1 출력값을 획득하고,제2 완전 연결 층을 통해, 상기 제3 중요도 토큰으로부터 제2 출력값을 획득하고, 상기 적어도 하나의 제1 출력값과 상기 제2 출력값을 내적하여 상기 적어도 하나의 제2 중요도를 획득하는, 동영상 장면 검색 및 하이라이트 검출 중 적어도 하나를 학습하기 위한 전자 장치. |
| 6 | (a) 크로스-어텐션 모델을 이용해, 복수의 동영상 클립 및 제1 텍스트 쿼리로부터 복수의 제1 동영상 특징을 획득하는 단계;(b) 트랜스포머 인코더를 이용해, 상기 복수의 제1 동영상 특징 및 제1 중요도 토큰(Saliency Token)으로부터 복수의 제2 동영상 특징, 제2 중요도 토큰 및 상기 제1 텍스트 쿼리에 대한 상기 복수의 동영상 클립 중 적어도 하나의 동영상 클립의 적어도 하나의 제1 중요도(Saliency Score)를 획득하는 단계;(c) 상기 크로스-어텐션 모델을 이용해, 상기 복수의 동영상 클립 및 제2 텍스트 쿼리로부터 복수의 제3 동영상 특징을 획득하는 단계;(d) 상기 트랜스포머 인코더를 이용해, 상기 복수의 제3 동영상 특징 및 상기 제1 중요도 토큰으로부터 복수의 제4 동영상 특징, 제3 중요도 토큰 및 상기 제2 텍스트 쿼리에 대한 상기 적어도 하나의 동영상 클립의 적어도 하나의 제2 중요도를 획득하는 단계; 및(e) 상기 제1 중요도는 상기 제2 중요도보다 크고, 상기 제1 중요도가 증가하고 상기 제2 중요도는 감소하도록 상기 크로스-어텐션 모델, 상기 트랜스포머 인코더 및 상기 제1 중요도 토큰을 수정하는 단계를 포함하며,상기 제1 텍스트 쿼리는 상기 적어도 하나의 동영상 클립과 양의 쌍이며,상기 제2 텍스트 쿼리는 상기 적어도 하나의 동영상 클립과 음의 쌍인, 동영상 장면 검색 및 하이라이트 검출 중 적어도 하나를 학습하기 위한 전자 장치의 동작 방법. |
| 7 | 제6 항에 있어서,상기 (a) 단계는,(a1) 상기 복수의 동영상 클립에 대한 복수의 동영상 특징으로부터 복수의 동영상 쿼리를 획득하는 단계;(a2) 상기 제1 텍스트 쿼리에 대한 제1 텍스트 쿼리 특징으로부터 제1 텍스트 키를 획득하는 단계;(a3) 상기 제1 텍스트 쿼리 특징으로부터 제1 텍스트 벨류를 획득하는 단계;(a4) 상기 복수의 동영상 쿼리, 상기 제1 텍스트 키 및 상기 제1 텍스트 벨류를 이용해 복수의 제1 어텐션 점수를 획득하는 단계;(a5) 상기 복수의 제1 어텐션 점수로부터 복수의 제1 가중치를 획득하는 단계; 및(a6) 상기 복수의 제1 가중치 및 상기 복수의 동영상 특징을 각각 곱함으로써 상기 복수의 제1 동영상 특징을 획득하는 단계를 포함하는, 동영상 장면 검색 및 하이라이트 검출 중 적어도 하나를 학습하기 위한 전자 장치의 동작 방법. |
| 8 | 제6 항에 있어서,상기 (c) 단계는,(c1) 상기 복수의 동영상 클립에 대한 복수의 동영상 특징으로부터 복수의 동영상 쿼리를 획득하는 단계;(c2) 상기 제2 텍스트 쿼리에 대한 제2 텍스트 쿼리 특징으로부터 제2 텍스트 키를 획득하는 단계;(c3) 상기 제2 텍스트 쿼리 특징으로부터 제2 텍스트 벨류를 획득하는 단계;(c4) 상기 복수의 동영상 쿼리, 상기 제2 텍스트 키 및 상기 제2 텍스트 벨류를 이용해 복수의 제2 어텐션 점수를 획득하는 단계;(c5) 상기 복수의 제2 어텐션 점수로부터 복수의 제2 가중치를 획득하는 단계; 및(c6) 상기 복수의 제2 가중치 및 상기 복수의 동영상 특징을 각각 곱함으로써 상기 복수의 제3 동영상 특징을 획득하는 단계를 포함하는, 동영상 장면 검색 및 하이라이트 검출 중 적어도 하나를 학습하기 위한 전자 장치의 동작 방법. |
| 9 | 제6 항에 있어서,상기 (b) 단계는,(b1) 제1 완전 연결 층을 통해, 상기 복수의 제2 동영상 특징 중 상기 적어도 하나의 동영상 클립과 대응하는 적어도 하나의 동영상 특징으로부터 적어도 하나의 제1 출력값을 획득하는 단계;(b2) 제2 완전 연결 층을 통해, 상기 제2 중요도 토큰으로부터 제2 출력값을 획득하는 단계; 및(b3) 상기 적어도 하나의 제1 출력값과 상기 제2 출력값을 내적하여 상기 적어도 하나의 제1 중요도를 획득하는 단계를 포함하는, 동영상 장면 검색 및 하이라이트 검출 중 적어도 하나를 학습하기 위한 전자 장치의 동작 방법. |
| 10 | 제6 항에 있어서,상기 (d) 단계는,(d1) 제1 완전 연결 층을 통해, 상기 복수의 제4 동영상 특징 중 상기 적어도 하나의 동영상 클립과 대응하는 적어도 하나의 동영상 특징으로부터 적어도 하나의 제1 출력값을 획득하는 단계;(d2) 제2 완전 연결 층을 통해, 상기 제3 중요도 토큰으로부터 제2 출력값을 획득하는 단계; 및(d3) 상기 적어도 하나의 제1 출력값과 상기 제2 출력값을 내적하여 상기 적어도 하나의 제2 중요도를 획득하는 단계를 포함하는, 동영상 장면 검색 및 하이라이트 검출 중 적어도 하나를 학습하기 위한 전자 장치의 동작 방법. |