| 번호 | 청구항 |
|---|---|
| 1 | 제 1항에 있어서, 상기 제 8단계에서, 상기 스코어링은, 최대 8개의 프로세스를 동시에 처리하며, 8개를 초과하는 후순위의 모델ID는 상기 8개의 프로세스 중 먼저 종료된 프로세스가 상기 후순위의 모델ID를 실행하는 것을 특징으로 하는 데이터 처리 방밥. |
| 1 | 제 1항에 있어서, 상기 제 8단계에서, 상기 스코어링 완료파일은 스코어링단계_스코어링대상모델ID_배치파일실행기준날짜_실제로실행된날짜 순으로 파일명을 형성하는 것을 특징으로 하는 데이터 처리 방법. |
| 1 | 제 1항에 있어서, 상기 제 7단계에서, 상기 완료파일은 전처리단계_파일이름_배치파일실행기준날짜_실제로실행한날짜 순으로 파일명을 형성하는 것을 특징으로 하는 데이터 처리 방법. |
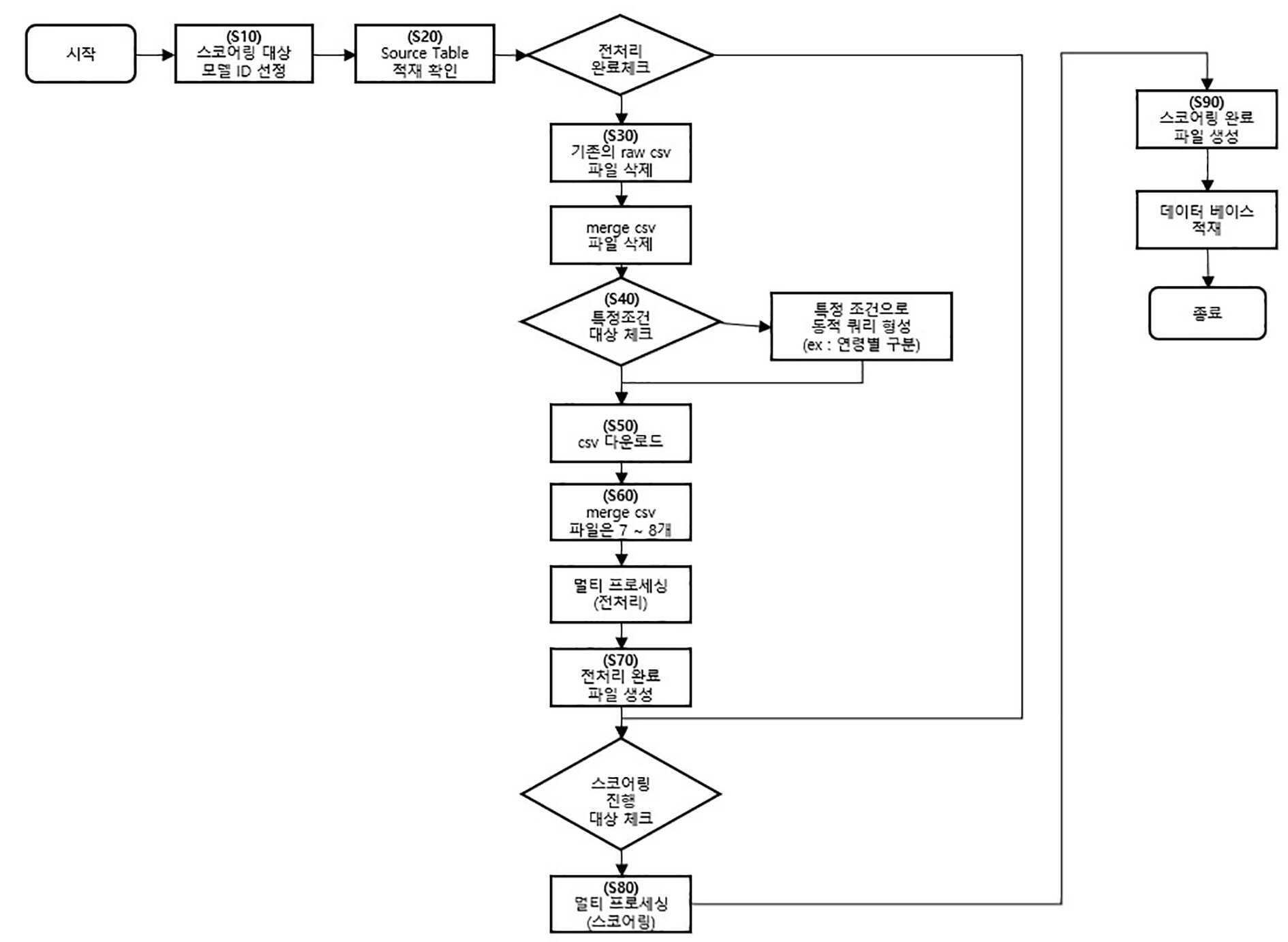
| 1 | 스코어링 대상 모델ID를 선정하는 제 1단계;소스테이블이 적재되어 있는지 확인하는 제 2단계;소스테이블에 기존의 원시데이터(raw csv)와 병합데이터(merge csv)가 있으면 삭제하는 제 3단계;소정의 조건으로 동적쿼리를 형성하는 제 4단계;상기 동적쿼리에 따라 분할해서 하둡(Hadoop)에서 상기 제 2단계의 로딩데이터를 csv 로 다운받는 제 5단계;상기 csv데이터들을 merge csv로 병합데이터를 형성하는 제 6단계;상기 merge csv 데이터들을 멀티프로세싱하여 완료파일을 생성하는 제 7단계;상기 제 7단계의 완료파일에 대하여 스코어링을 진행하여 스코어링 완료파일을 생성하는 제 8단계;상기 8단계의 완료파일을 저장하는 제 9단계;를 포함하는 것을 특징으로 하는 데이터 처리 방법. |
| 1 | 제 1항에 있어서, 상기 제 7단계에서, 상기 csv 데이터 중 50GB 가 넘는 데이터는 7개의 프로세스로 실행하고, 50GB 미만인 데이터는 8개의 프로세스로 멀티프로세싱하는 것을 특징으로 하는 데이터 처리 방법. |