| 번호 | 청구항 |
|---|---|
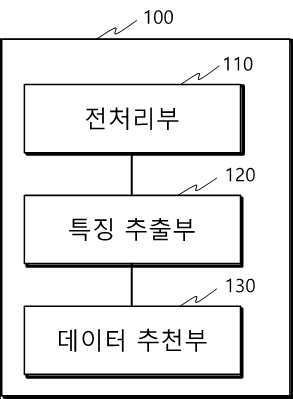
| 1 | 임상 시험 데이터에 포함된 메타 데이터 및 자연어 데이터를 분류하며, 자연어 데이터에 대한 토큰을 생성하는 전처리부;상기 메타 데이터 및 상기 토큰에 기초하여 임베딩 벡터를 생성하는 특징 추출부; 및사용자가 검색 요청한 입력 임상 시험 데이터로부터 생성한 임베딩 벡터와 하나 이상의 기 저장된 임상 시험 데이터로부터 생성한 임베딩 벡터 간 거리에 기초하여 상기 하나 이상의 기 저장된 임상 시험 데이터 중 소정 거리 이내에 해당하는 하나 이상의 유사 임상 시험 데이터를 추출하는 데이터 추천부를 포함하는, 유사 임상 시험 데이터 추천 장치. |
| 1 | 제 1 항에 있어서, 상기 전처리부는상기 메타 데이터에 대한 원-핫 인코딩(one-hot encoding) 벡터를 생성하며,상기 자연어 데이터에 포함된 특수 문자 및 불용어 중 적어도 하나를 제거한 토큰을 생성하는, 유사 임상 시험 데이터 추천 장치. |
| 1 | 제 2 항에 있어서, 상기 특징 추출부는상기 원-핫 인코딩 벡터를 기초로 메타 데이터에 대한 임베딩 벡터를 생성하는 제 1 임베딩 모델; 및상기 토큰을 기초로 자연어 데이터에 대한 임베딩 벡터를 생성하는 제 2 임베딩 모델을 포함하는, 유사 임상 시험 데이터 추천 장치. |
| 1 | 제 3 항에 있어서, 상기 특징 추출부는상기 제 1 임베딩 모델에서 출력한 임베딩 벡터 및 상기 제 2 임베딩 모델에서 출력한 임베딩 벡터를 입력 받아 임상 시험 데이터에 대한 임베딩 벡터를 생성하는 앙상블(ensemble) 모델을 더 포함하는, 유사 임상 시험 데이터 추천 장치. |
| 1 | 제 3 항에 있어서, 상기 특징 추출부는상기 토큰에 대한 문서 단어 행렬(document term matrix)을 생성하는, 유사 임상 시험 데이터 추천 장치. |
| 1 | 제 5 항에 있어서, 상기 제 2 임베딩 모델은 상기 문서 단어 행렬을 입력 받아 행렬 분해(matrix factorization)을 수행하여 임상 시험 데이터 잠재 행렬(latent matrix) 및 단어 잠재 행렬을 생성하는, 유사 임상 시험 데이터 추천 장치. |
| 1 | 제 6 항에 있어서, 상기 임상 시험 데이터 잠재 행렬은 '임상시험 수 x K' 크기의 행렬로 구성되며, 상기 단어 잠재 행렬은 'K x 단어 수' 크기의 행렬로 구성되는, 유사 임상 시험 데이터 추천 장치. |
| 1 | 제 7 항에 있어서, 상기 데이터 추천부는상기 임상 시험 데이터 잠재 행렬을 구성하는 각각의 행을 임상 시험 데이터의 임베딩 벡터로 결정하여 거리를 계산하는, 유사 임상 시험 데이터 추천 장치. |
| 1 | 제 3 항에 있어서, 상기 데이터 추천부는상기 제 1 임베딩 모델에서 출력한 임베딩 벡터에 기초한 거리 및 상기 제 2 임베딩 모델에서 출력한 임베딩 벡터에 기초한 거리의 가중합을 이용하여 임상 시험 데이터 간 거리를 계산하는, 유사 임상 시험 데이터 추천 장치. |
| 1 | 하나 이상의 프로세서, 및상기 하나 이상의 프로세서에 의해 실행되는 하나 이상의 프로그램을 저장하는 메모리를 구비한 컴퓨팅 장치에서 수행되는 방법으로서,임상 시험 데이터에 포함된 메타 데이터 및 자연어 데이터를 분류하며, 자연어 데이터에 대한 토큰을 생성하는 전처리 단계;상기 메타 데이터 및 상기 토큰에 기초하여 임베딩 벡터를 생성하는 특징 추출 단계; 및사용자가 검색 요청한 입력 임상 시험 데이터로부터 생성한 임베딩 벡터와 하나 이상의 기 저장된 임상 시험 데이터로부터 생성한 임베딩 벡터 간 거리에 기초하여 상기 하나 이상의 기 저장된 임상 시험 데이터 중 소정 거리 이내에 해당하는 하나 이상의 유사 임상 시험 데이터를 추출하는 데이터 추천 단계를 포함하는, 유사 임상 시험 데이터 추천 방법. |
| 1 | 제 10 항에 있어서, 상기 전처리 단계는상기 메타 데이터에 대한 원-핫 인코딩(one-hot encoding) 벡터를 생성하며,상기 자연어 데이터에 포함된 특수 문자 및 불용어 중 적어도 하나를 제거한 토큰을 생성하는, 유사 임상 시험 데이터 추천 방법. |
| 1 | 제 11 항에 있어서, 상기 특징 추출 단계는상기 원-핫 인코딩 벡터를 기초로 메타 데이터에 대한 임베딩 벡터를 생성하는 제 1 임베딩 모델; 및상기 토큰을 기초로 자연어 데이터에 대한 임베딩 벡터를 생성하는 제 2 임베딩 모델을 포함하는, 유사 임상 시험 데이터 추천 방법. |
| 1 | 제 12 항에 있어서, 상기 특징 추출 단계는상기 제 1 임베딩 모델에서 출력한 임베딩 벡터 및 상기 제 2 임베딩 모델에서 출력한 임베딩 벡터를 입력 받아 임상 시험 데이터에 대한 임베딩 벡터를 생성하는 앙상블(ensemble) 모델을 더 포함하는, 유사 임상 시험 데이터 추천 방법. |
| 1 | 제 12 항에 있어서, 상기 특징 추출 단계는상기 토큰에 대한 문서 단어 행렬(document term matrix)을 생성하는, 유사 임상 시험 데이터 추천 방법. |
| 1 | 제 14 항에 있어서, 상기 제 2 임베딩 모델은 상기 문서 단어 행렬을 입력 받아 행렬 분해(matrix factorization)을 수행하여 임상 시험 데이터 잠재 행렬(latent matrix) 및 단어 잠재 행렬을 생성하는, 유사 임상 시험 데이터 추천 방법. |
| 1 | 제 15 항에 있어서, 상기 임상 시험 데이터 잠재 행렬은 '임상시험 수 x K' 크기의 행렬로 구성되며, 상기 단어 잠재 행렬은 'K x 단어 수' 크기의 행렬로 구성되는, 유사 임상 시험 데이터 추천 방법. |
| 1 | 제 16 항에 있어서, 상기 데이터 추천 단계는상기 임상 시험 데이터 잠재 행렬을 구성하는 각각의 행을 임상 시험 데이터의 임베딩 벡터로 결정하여 거리를 계산하는, 유사 임상 시험 데이터 추천 방법. |
| 1 | 제 12 항에 있어서, 상기 데이터 추천 단계는상기 제 1 임베딩 모델에서 출력한 임베딩 벡터에 기초한 거리 및 상기 제 2 임베딩 모델에서 출력한 임베딩 벡터에 기초한 거리의 가중합을 이용하여 임상 시험 데이터 간 거리를 계산하는, 유사 임상 시험 데이터 추천 방법. |