| 번호 | 청구항 |
|---|---|
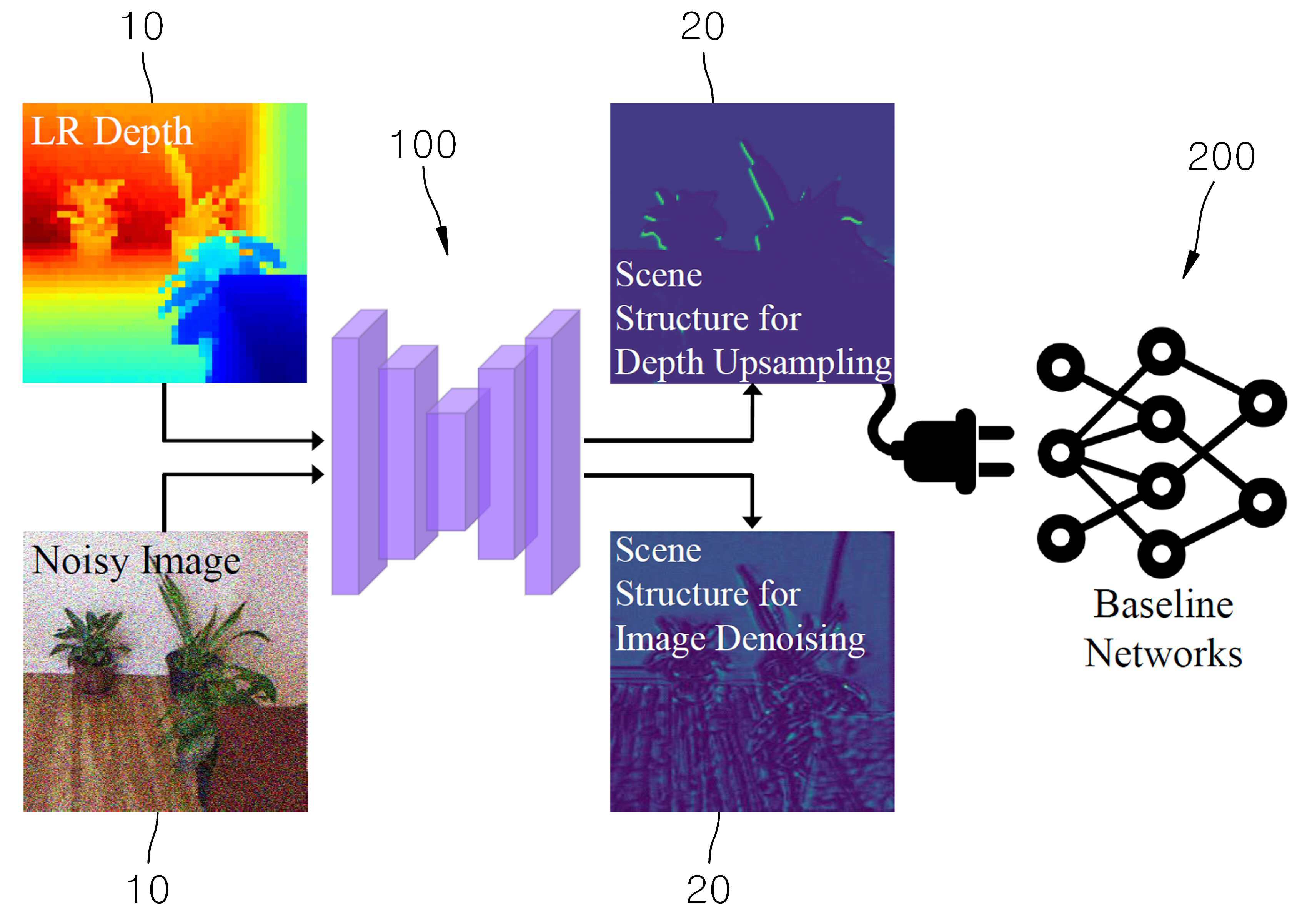
| 1 | 장면 구조(scene structure)를 이용하여 영상 처리 태스크를 수행하는 베이스라인 네트워크에 플러그 앤 플레이(plug-and-play) 방식으로 적용되는 신경망 모델을 이용하여 장면 구조를 생성하는 방법에 있어서,영상의 유사도 행렬(affinity matrix)에 따라 상기 영상에 대한 복수의 고유벡터(eigenvector)를 생성하는 단계; 및상기 복수의 고유벡터를 상기 베이스라인 네트워크의 태스크에 따라 학습되는 단일 컨볼루션 레이어에 입력하여 상기 장면 구조를 생성하고, 상기 장면 구조를 상기 베이스라인 네트워크로 출력하는 단계를 포함하는태스크별 장면 구조 생성 방법. |
| 2 | 제1항에 있어서,상기 베이스라인 네트워크는영상 디노이징(denosing), 영상 디블러링(deblurring), 영상 초해상화(super-resolution), 영상 인페인팅(inpainting), 또는 깊이 업샘플링(depth upsampling), 깊이 완성(depth completion) 중 적어도 하나의 태스크를 수행하는태스크별 장면 구조 생성 방법. |
| 3 | 제1항에 있어서,상기 고유벡터를 생성하는 단계는상기 신경망 모델 내 인코더-디코더를 통해, 상기 유사도 행렬에 따라 클러스터링된 상기 영상의 각 영역별 구조에 대응하는 고유벡터를 생성하는 단계를 포함하는태스크별 장면 구조 생성 방법. |
| 4 | 제1항에 있어서,상기 고유벡터를 생성하는 단계는상기 유사도 행렬을 변환하여 라플라시안(Laplacian) 행렬을 도출하는 단계와,상기 고유벡터에 대한 상기 라플라시안 행렬의 2차 형식(quadratic form)의 값을 최소로 만드는 고유벡터를 생성하는 단계를 포함하는태스크별 장면 구조 생성 방법. |
| 5 | 제4항에 있어서,상기 고유벡터를 생성하는 단계는하기 [수학식 1]로 표현되는 손실함수를 최소로 만드는 고유벡터를 생성하는 단계를 포함하는[수학식 1] ,(여기서 Y는 상기 고유벡터, k는 상기 고유벡터의 채널, L은 상기 라플라시안 행렬)태스크별 장면 구조 생성 방법. |
| 6 | 제5항에 있어서,상기 고유벡터를 생성하는 단계는상기 [수학식 1] 및 하기 [수학식 2]로 표현되는 두 손실함수의 선형 결합(linear combination)을 최소로 만드는 고유벡터를 생성하는 단계를 포함하는[수학식 2] ,(여기서 는 하이퍼파라미터(hyperparameter))태스크별 장면 구조 생성 방법. |
| 7 | 삭제 |
| 8 | 제1항에 있어서,상기 단일 컨볼루션 레이어의 필터는 상기 베이스라인 네트워크의 태스크에 따라 학습되는 가중치를 갖는태스크별 장면 구조 생성 방법. |