| 번호 | 청구항 |
|---|---|
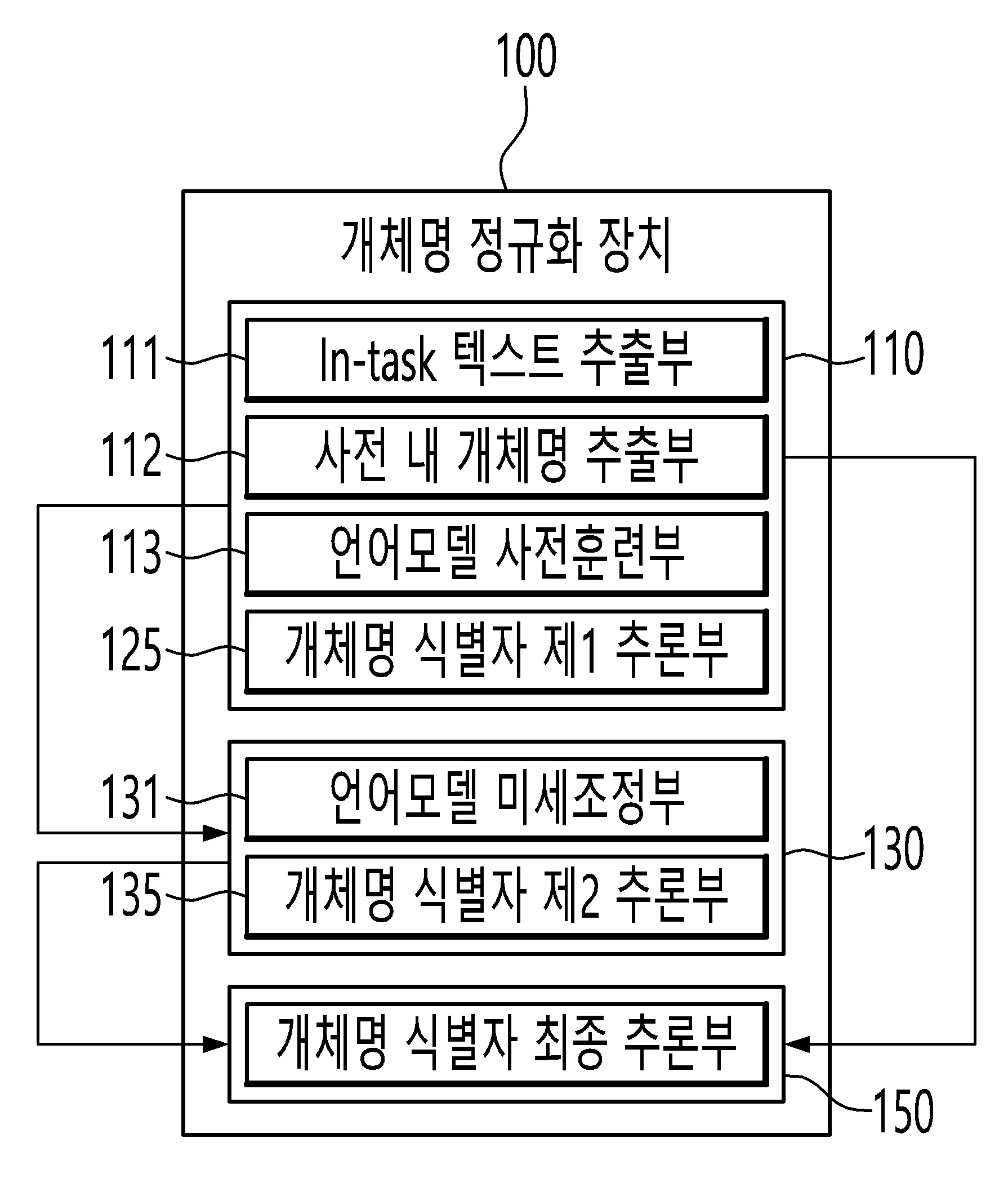
| 1 | 어느 멘션(mention)에 대한 다수의 후보명 중 상기 다수의 후보명에 대한 각각의 제 1 선별값에 기초하여 적어도 한 개의 후보명을 제 1 단계로 선별하는 제 1 선별부;상기 제 1 선별부의 선별결과를 이용하여 선별된 후보명에 대한 제 2 선별값을 구하고, 상기 제 2 선별값에 기초하여 후보명을 제 2 단계로 선별하는 제 2 선별부; 및 상기 제 1 선별부의 선별결과와 상기 제 2 선별부의 선별결과를 이용하여 선별된 후보명에 대한 제 3 선별값을 구하고, 상기 제 3 선별값에 기초하여 후보명을 제 3 단계로 선별하고, 상기 멘션에 대한 표준화 식별자를 선별하는 제 3 선별부를 포함하는 개체명 정규화 장치. |
| 2 | 제 1 항에 있어서, 상기 제 1 선별부 및 상기 제 2 선별부는, 버트(BERT)에 기반하는 모델인 개체명 정규화 장치. |
| 3 | 제 1 항에 있어서, 상기 제 1 선별값 및 상기 제 2 선별값은, 상기 후보명이 상기 멘션에 대한 상기 표준화 식별자가 될 가능성을 나타내는 개체명 정규화 장치. |
| 4 | 제 1 항에 있어서, 상기 제 1 선별부에는 제 1 언어모델이 포함되고, 상기 제 2 선별부에는 제 2 언어모델이 포함되는 개체명 정규화 장치. |
| 5 | 제 4 항에 있어서, 상기 제 1 선별값은, 상기 멘션과 상기 후보명을 임베딩한, 임베딩 벡터 간의 유사도와 비례하는 개체명 정규화 장치. |
| 6 | 제 1 항에 있어서, 상기 제 2 선별부에는, 상기 제 1 선별부에 의해서 상기 표준화 식별자가 될 가능성이 높은 일부의 상기 후보명만이 입력되는 개체명 정규화 장치. |
| 7 | 제 6 항에 있어서, 상기 제 2 선별부로는, 상기 멘션과 상기 후보명이 K개의 '[CLS], 멘션(m), [SEP], 후보명(n)'의 형식으로 입력되는 개체명 정규화 장치. |
| 8 | 제 1 항에 있어서, 상기 제 3 선별부는, 상기 제 1 선별값 및 상기 제 2 선별값을 더한 상기 제 3 선별값이 가장 큰 후보명을 상기 표준화 식별자로 선정하는 개체명 정규화 장치. |
| 9 | 적어도 한 개의 후보명을 선별하는 제 1 선별부와, 상기 제 1 선별부의 선별결과를 이용하여 후보명을 선별하는 제 2 선별부와, 상기 제 1 선별부와 상기 제 2 선별부의 선별결과를 이용하여 후보명을 선발하는 제 3 선별부를 포함하는 개체명 정규화 장치의 개체명 정규화 방법에 있어서,어느 멘션(m)의 표준화 식별자가 될 수 있는 각 후보명 모두(N)에 대한 제 1 선별값을 산출하는 제 1 단계(S1);상기 제 1 선별값이 큰 일부분(K, 여기서, K는 N보다 작다)의 후보명에 대한 제 2 선별값을 산출하는 제 2 단계(S2); 및상기 제 1 선별값과 상기 제 2 선별값을 이용하여 제 3 선별값을 구하고, 상기 제 3 선별값을 이용하여 상기 표준화 식별자를 정하는 제 3 단계(S3)를 포함하는 개체명 정규화 방법. |
| 10 | 제 9 항에 있어서, 상기 제 3 선별값이 클수록 표준화 식별자가 될 가능성이 높은 개체명 정규화 방법. |