| 번호 | 청구항 |
|---|---|
| 5 | 제4항에 있어서,상기 토픽 키워드 추출부는 상기 콘텐츠들 중 상기 태그 정보가 텍스트 태그, 테이블 태그, 헤더 태그 및 목록 태그 중 어느 하나의 태그 정보를 가지는 콘텐츠를 텍스트 콘텐츠로 추출하는웹 페이지 분류 장치. |
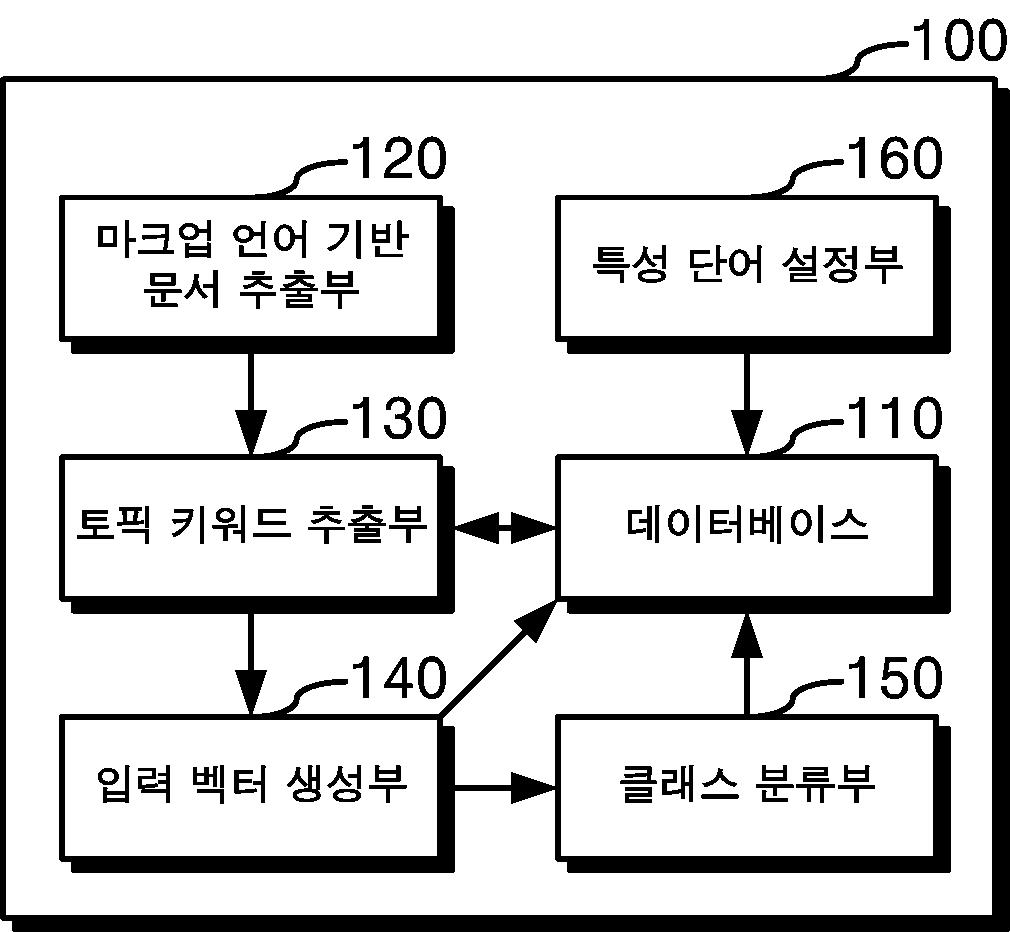
| 1 | 사전 설정된 L - 상기 L은 2 이상의 정수임 - 개의 클래스들 중에서 웹 페이지의 클래스를 분류하기 위한 분류 기준 벡터들 - 상기 분류 기준 벡터들 각각의 원소들의 개수는 i개이고, 상기 i는 사전 설정된 특성 단어들의 개수임 - 이 저장되어 있는 데이터베이스;상기 웹 페이지의 마크업 언어 기반 문서에 포함된 콘텐츠들에서 텍스트 콘텐츠들을 추출한 후 상기 텍스트 콘텐츠들에 포함된 워드들 중 토픽 키워드를 추출하는 토픽 키워드 추출부;상기 워드들을 이용하여 상기 웹 페이지에 대한 입력 벡터 - 상기 입력 벡터의 원소들의 개수는 i개임 - 를 생성하되, 상기 워드들 중 상기 토픽 키워드에 포함되는 워드들과 상기 토픽 키워드에 포함되지 않는 워드들에 서로 다른 강화 계수들을 적용하여 i개의 원소들의 값을 연산하고, 상기 연산된 i개의 원소들의 값을 이용하여 상기 입력 벡터를 생성하는 입력 벡터 생성부; 및상기 분류 기준 벡터들과 상기 입력 벡터 간의 내적 곱을 수행함으로써 분류 값들을 연산하고, 상기 분류 값들에 기초하여 상기 사전 설정된 클래스들 중에서 상기 웹 페이지의 클래스를 분류하는 클래스 분류부를 포함하는 웹 페이지 분류 장치. |
| 2 | 제1항에 있어서,상기 토픽 키워드 추출부는 상기 콘텐츠들의 태그 정보에 기초하여 상기 콘텐츠들에서 상기 텍스트 콘텐츠들을 추출하는웹 페이지 분류 장치. |
| 3 | 제2항에 있어서,상기 토픽 키워드 추출부는 상기 텍스트 콘텐츠들에 포함된 워드들 간의 유사도 점수를 연산한 후 워드들 각각에 대하여 해당 워드와 다른 워드들 간에 연산된 유사도 점수들 중 가장 높은 유사도 점수를 해당 워드의 최종 유사도 점수로 할당하고, 최종 유사도 점수가 높은 j - 상기 j는 1 이상의 정수임 - 개의 워드를 토픽 키워드로 추출하는웹 페이지 분류 장치. |
| 4 | 제3항에 있어서,상기 토픽 키워드 추출부는 상기 텍스트 콘텐츠들을 제1 텍스트 콘텐츠들과 제2 텍스트 콘텐츠들로 분류하고, 상기 제1 텍스트 콘텐츠들에 포함된 제1 워드들과 상기 제1 텍스트 콘텐츠들에 포함된 제2 워드들 간의 유사도 점수를 연산하며,상기 제1 텍스트 콘텐츠들은 상기 웹 페이지의 타이틀 콘텐츠들이고, 상기 제2 텍스트 콘텐츠들은 상기 웹 페이지의 타이틀 콘텐츠들 이외의 콘텐츠들인웹 페이지 분류 장치. |
| 6 | 제1항에 있어서,상기 데이터베이스는 제1 내지 제i 강화 계수를 저장하고 있고,상기 입력 벡터 생성부는 상기 워드들 중 제k - 상기 k는 1 이상 상기 i 이하의 정수임 - 워드가 상기 토픽 키워드에 포함되면, 제k 강화 계수를 이용하여 상기 제k 워드에 대한 원소 값을 연산하고, 상기 제k 워드가 상기 토픽 키워드에 포함되지 않으면, 1의 강화 계수를 이용하여 상기 제k 워드에 대한 원소 값을 연산하는웹 페이지 분류 장치. |
| 7 | 제6항에 있어서,상기 입력 벡터 생성부는 상기 워드들 중 상기 제k 워드의 출현 빈도, 상기 제k 워드의 역문서 빈도 및 상기 제k 워드가 상기 토픽 키워드에 포함되는지 여부에 따라 결정되는 강화 계수를 곱함으로써 상기 제k 워드에 대한 원소 값을 연산하는웹 페이지 분류 장치. |
| 8 | 제1항에 있어서, 상기 클래스 분류부는 상기 연산된 분류 값들 중 제s - 상기 s는 1 이상 상기 L 이하의 정수임 - 클래스와 상기 제s 클래스 이외의 클래스들 각각을 분류하기 위한 분류 기준 벡터들과 상기 입력 벡터 간의 내적 곱을 수행함으로써 연산된 제s 분류 값들을 합산하여 제s 합산 값을 연산함으로써 제1 내지 제L 합산 값들을 생성하며, 상기 제1 내지 제L 합산 값들 중 가장 큰 값을 가지는 합산 값에 상응하는 클래스를 상기 웹 페이지의 클래스로 분류하는웹 페이지 분류 장치. |
| 9 | 제8항에 있어서, 상기 데이터베이스는 상기 분류 기준 벡터들 각각에 매칭되어 있는 분류 기준 조절 값들을 더 저장하고 있고,상기 클래스 분류부는 상기 분류 기준 벡터들 각각과 상기 입력 벡터 간의 내적 곱을 수행한 후 상기 분류 기준 조절 값들 중 상기 분류 기준 벡터들 각각에 매칭되어 있는 분류 기준 조절 값을 가산함으로써 분류 값들을 연산하는웹 페이지 분류 장치. |
| 10 | 사전 설정된 L - 상기 L은 2 이상의 정수임 - 개의 클래스들 중에서 웹 페이지의 클래스를 분류하기 위한 분류 기준 벡터들 - 상기 분류 기준 벡터들 각각의 원소들의 개수는 i개이고, 상기 i는 사전 설정된 특성 단어들의 개수임 - 이 저장되어 있는 데이터베이스를 유지하는 단계;상기 웹 페이지의 마크업 언어 기반 문서에 포함된 콘텐츠들에서 텍스트 콘텐츠들을 추출한 후 상기 텍스트 콘텐츠들에 포함된 워드들 중 토픽 키워드를 추출하는 단계;상기 워드들을 이용하여 상기 웹 페이지에 대한 입력 벡터 - 상기 입력 벡터의 원소들의 개수는 i개임 - 를 생성하되, 상기 워드들 중 상기 토픽 키워드에 포함되는 워드들과 상기 토픽 키워드에 포함되지 않는 워드들에 서로 다른 강화 계수들을 적용하여 i개의 원소들의 값을 연산하고, 상기 연산된 i개의 원소들의 값을 이용하여 상기 입력 벡터를 생성하는 단계; 및상기 분류 기준 벡터들과 상기 입력 벡터 간의 내적 곱을 수행함으로써 분류 값들을 연산하고, 상기 분류 값들에 기초하여 상기 사전 설정된 클래스들 중에서 상기 웹 페이지의 클래스를 분류하는 단계를 포함하는 웹 페이지 분류 장치의 동작 방법. |
| 11 | 제10항에 있어서,상기 토픽 키워드를 추출하는 단계는 상기 콘텐츠들의 태그 정보에 기초하여 상기 콘텐츠들에서 상기 텍스트 콘텐츠들을 추출하는웹 페이지 분류 장치의 동작 방법. |
| 12 | 제11항에 있어서,상기 토픽 키워드를 추출하는 단계는 상기 텍스트 콘텐츠들에 포함된 워드들 간의 유사도 점수를 연산한 후 워드들 각각에 대하여 해당 워드와 다른 워드들 간에 연산된 유사도 점수들 중 가장 높은 유사도 점수를 해당 워드의 최종 유사도 점수로 할당하고, 최종 유사도 점수가 높은 j - 상기 j는 1 이상의 정수임 - 개의 워드를 토픽 키워드로 추출하는웹 페이지 분류 장치의 동작 방법. |
| 13 | 제12항에 있어서,상기 토픽 키워드를 추출하는 단계는 상기 텍스트 콘텐츠들을 제1 텍스트 콘텐츠들과 제2 텍스트 콘텐츠들로 분류하고, 상기 제1 텍스트 콘텐츠들에 포함된 제1 워드들과 상기 제1 텍스트 콘텐츠들에 포함된 제2 워드들 간의 유사도 점수를 연산하며,상기 제1 텍스트 콘텐츠들은 상기 웹 페이지의 타이틀 콘텐츠들이고, 상기 제2 텍스트 콘텐츠들은 상기 웹 페이지의 타이틀 콘텐츠들 이외의 콘텐츠들인웹 페이지 분류 장치의 동작 방법. |
| 14 | 제13항에 있어서,상기 토픽 키워드를 추출하는 단계는 상기 콘텐츠들 중 상기 태그 정보가 텍스트 태그, 테이블 태그, 헤더 태그 및 목록 태그 중 어느 하나의 태그 정보를 가지는 콘텐츠를 텍스트 콘텐츠로 추출하는웹 페이지 분류 장치의 동작 방법. |
| 15 | 제10항에 있어서,상기 데이터베이스를 유지하는 단계는 제1 내지 제i 강화 계수를 저장하고 있는 상기 데이터베이스를 유지하고,상기 입력 벡터를 생성하는 단계는 상기 워드들 중 제k - 상기 k는 1 이상 상기 i 이하의 정수임 - 워드가 상기 토픽 키워드에 포함되면, 제k 강화 계수를 이용하여 상기 제k 워드에 대한 원소 값을 연산하고, 상기 제k 워드가 상기 토픽 키워드에 포함되지 않으면, 1의 강화 계수를 이용하여 상기 제k 워드에 대한 원소 값을 연산하는웹 페이지 분류 장치의 동작 방법. |
| 16 | 제15항에 있어서,상기 입력 벡터를 생성하는 단계는 상기 워드들 중 상기 제k 워드의 출현 빈도, 상기 제k 워드의 역문서 빈도 및 상기 제k 워드가 상기 토픽 키워드에 포함되는지 여부에 따라 결정되는 강화 계수를 곱함으로써 상기 제k 워드에 대한 원소 값을 연산하는웹 페이지 분류 장치의 동작 방법. |
| 17 | 제10항에 있어서,상기 웹 페이지의 클래스를 분류하는 단계는 상기 연산된 분류 값들 중 제s - 상기 s는 1 이상 상기 L 이하의 정수임 - 클래스와 상기 제s 클래스 이외의 클래스들 각각을 분류하기 위한 분류 기준 벡터들과 상기 입력 벡터 간의 내적 곱을 수행함으로써 연산된 제s 분류 값들을 합산하여 제s 합산 값을 연산함으로써 제1 내지 제L 합산 값들을 생성하며, 상기 제1 내지 제L 합산 값들 중 가장 큰 값을 가지는 합산 값에 상응하는 클래스를 상기 웹 페이지의 클래스로 분류하는웹 페이지 분류 장치의 동작 방법. |
| 18 | 제17항에 있어서,상기 데이터베이스를 유지하는 단계는 상기 분류 기준 벡터들 각각에 매칭되어 있는 분류 기준 조절 값들을 더 저장하고 있는 상기 데이터베이스를 유지하고,상기 웹 페이지의 클래스를 분류하는 단계는 상기 분류 기준 벡터들 각각과 상기 입력 벡터 간의 내적 곱을 수행한 후 상기 분류 기준 조절 값들 중 상기 분류 기준 벡터들 각각에 매칭되어 있는 분류 기준 조절 값을 가산함으로써 분류 값들을 연산하는웹 페이지 분류 장치의 동작 방법. |
| 19 | 제10항 내지 제18항 중 어느 한 항의 방법을 컴퓨터로 하여금 수행하도록 하는 프로그램을 기록한 컴퓨터 판독 가능 기록 매체. |
| 20 | 제10항 내지 제18항 중 어느 한 항의 방법을 컴퓨터와의 결합을 통해 실행시키기 위한 저장매체에 저장된 컴퓨터 프로그램. |