| 번호 | 청구항 |
|---|---|
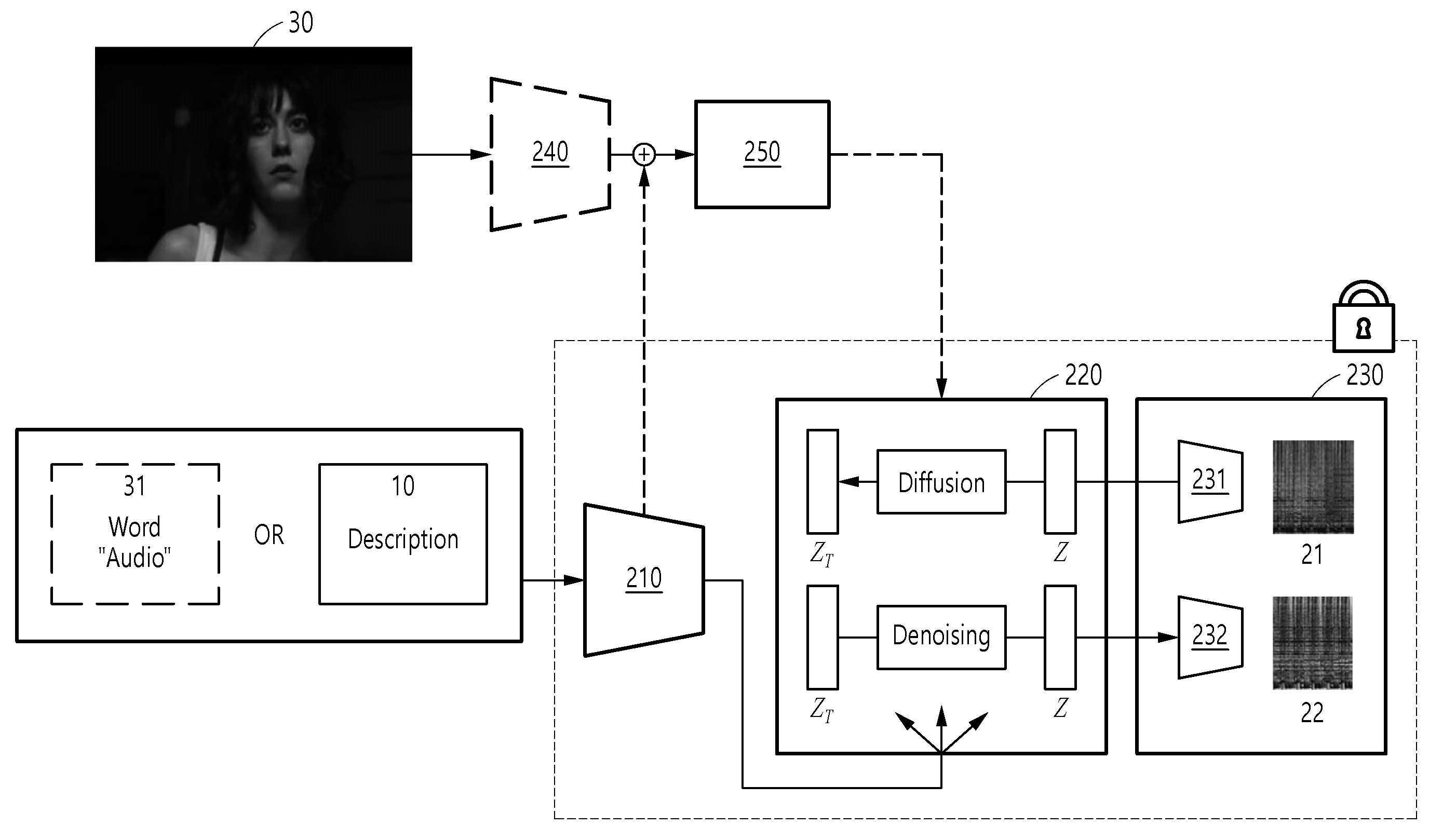
| 1 | 프로세서에 의해 수행되는 오디오 생성 모델을 트레이닝시키는 방법에 있어서,사전-트레이닝된(pre-trained) 텍스트 인코더를 통해 오디오 데이터, 이미지 데이터 및 텍스트 데이터를 포함하는 트레이닝 데이터 세트 중 텍스트 데이터를 상기 오디오 생성 모델의 텍스트 조건 형태로 변환하는 단계;상기 변환된 텍스트 조건 형태 및 상기 트레이닝 데이터 세트 중 오디오 데이터에 기초하여, 상기 오디오 생성 모델의 텍스트 기반 손실(loss)을 산출하는 단계;상기 산출된 텍스트 기반 손실이 최소화되도록 상기 오디오 생성 모델을 트레이닝시켜 텍스트 기반 오디오 생성 파라미터(parameter)를 결정하는 단계;상기 트레이닝 데이터 세트 중 이미지 데이터를 사전-트레이닝된 이미지 인코더를 통해 상기 오디오 생성 모델의 이미지 조건 형태로 변환하는 단계;상기 텍스트 기반 오디오 생성 파라미터, 상기 변환된 이미지 조건 형태 및 상기 트레이닝 데이터 세트 중 오디오 데이터에 기초하여, 상기 오디오 생성 모델의 텍스트 및 이미지 기반 손실을 산출하는 단계; 및상기 산출된 텍스트 및 이미지 기반 손실이 최소화되도록 상기 오디오 생성 모델을 트레이닝시켜 텍스트 및 이미지 기반 오디오 생성 파라미터를 결정하는 단계를 포함하고,상기 방법은,상기 오디오 생성 모델을 트레이닝시키기 이전에, 상기 트레이닝 데이터 세트를 생성하는 단계를 더 포함하며,상기 트레이닝 데이터 세트를 생성하는 단계는,영상 데이터로부터 제1 지속 시간의 복수의 제1 클립 데이터들을 생성하는 단계;상기 영상 데이터로부터 상기 제1 지속 시간보다 짧은 시간 길이인 제2 지속 시간의 복수의 제2 클립 데이터들을 생성하는 단계;상기 제1 지속 시간에 대응되는 시간 길이가 되도록 상기 복수의 제2 클립 데이터들을 연결시키는 단계;상기 복수의 제1 클립 데이터들과 상기 연결된 복수의 제2 클립 데이터들을 병합시켜 복수의 원시 클립 데이터를 생성하는 단계; 및상기 복수의 원시 클립 데이터로부터 추출된 이미지 데이터 및 음성 분리 오디오 데이터와 이에 기반한 텍스트 데이터에 기초하여 복수의 상기 트레이닝 데이터 세트를 생성하는 단계를 포함하는 방법. |
| 2 | 제1항에 있어서,상기 텍스트 조건 형태로 변환하는 단계는,상기 텍스트 인코더에 상기 텍스트 데이터를 입력하여 텍스트 임베딩(embedding)을 추출하는 단계를 포함하는 방법. |
| 3 | 제2항에 있어서,상기 텍스트 기반 손실을 산출하는 단계는,상기 오디오 데이터를 참값(Ground Truth)으로 하여, 상기 오디오 생성 모델의 인코더를 통해 픽셀 공간(pixel space)의 고 차원 참값을 잠재 공간(latent space)의 저 차원 참값으로 변환하는 단계;상기 변환된 저 차원 참값을 상기 오디오 생성 모델을 통해 디퓨전(diffusion)하여 노이즈가 삽입된 저 차원 참값을 생성하는 단계;상기 텍스트 임베딩을 조건으로 상기 오디오 생성 모델을 통해 상기 노이즈가 삽입된 저 차원 참값을 디노이징(denoising)하여 노이즈가 제거된 저 차원 예측값을 생성하는 단계;상기 오디오 생성 모델의 디코더를 통해 저 차원 예측값을 고 차원 예측값으로 변환하는 단계; 및상기 고 차원 참값과 상기 고 차원 예측값 간의 텍스트 기반 손실을 산출하는 단계를 포함하는 방법. |
| 4 | 제1항에 있어서,상기 이미지 조건 형태로 변환하는 단계는,상기 이미지 인코더에 상기 이미지 데이터를 입력하여 이미지 임베딩을 추출하는 단계를 포함하는 방법. |
| 5 | 제4항에 있어서,상기 텍스트 및 이미지 기반 손실을 산출하는 단계는,상기 오디오 데이터를 참값으로 하여, 상기 오디오 생성 모델의 인코더를 통해 픽셀 공간의 고 차원 참값을 잠재 공간의 저 차원 참값으로 변환하는 단계;상기 변환된 저 차원 참값을 상기 오디오 생성 모델을 통해 디퓨전하여 노이즈가 삽입된 저 차원 참값을 생성하는 단계;상기 이미지 임베딩 및 텍스트 임베딩을 조건으로 상기 텍스트 기반 오디오 생성 파라미터가 적용된 상기 오디오 생성 모델을 통해 상기 노이즈가 삽입된 저 차원 참값을 디노이징하여 노이즈가 제거된 저 차원 예측값을 생성하는 단계;상기 오디오 생성 모델의 디코더를 통해 저 차원 예측값을 고 차원 예측값으로 변환하는 단계; 및상기 고 차원 참값과 상기 고 차원 예측값 간의 텍스트 및 이미지 기반 손실을 산출하는 단계를 포함하는 방법. |
| 6 | 제1항에 있어서,상기 텍스트 기반 오디오 생성 파라미터를 결정한 이후, 상기 트레이닝 데이터 세트 중 이미지 데이터로부터 하나 이상의 단어들을 추출하는 단계;사전-트레이닝된 텍스트 인코더를 통해 상기 추출된 하나 이상의 단어들에서 이미지 기반 텍스트 임베딩을 추출하는 단계;상기 추출된 이미지 기반 텍스트 임베딩, 상기 텍스트 기반 오디오 생성 파라미터 및 상기 트레이닝 데이터 세트 중 오디오 데이터에 기초하여, 상기 오디오 생성 모델의 이미지 기반 손실을 산출하는 단계; 및상기 산출된 이미지 기반 손실이 최소화되도록 상기 오디오 생성 모델을 트레이닝시켜 이미지 기반 오디오 생성 파라미터를 결정하는 단계;를 더 포함하는 방법. |
| 7 | 삭제 |
| 8 | 삭제 |
| 9 | 제1항에 있어서,상기 복수의 트레이닝 데이터 세트를 생성하는 단계는,상기 원시 클립 데이터로부터 비디오 프레임들을 추출하고, 상기 추출된 비디오 프레임들을 클러스터링하여 하나 이상의 상기 이미지 데이터를 추출하는 단계;상기 원시 클립 데이터로부터 원시 오디오를 추출하고, 상기 추출된 원시 오디오에서 음성(speech)을 분리(decoupling)하여 상기 음성 분리 오디오 데이터를 생성하는 단계; 및상기 이미지 데이터와 상기 음성 분리 오디오 데이터에 상기 복수의 제1 클립 데이터들 및 상기 복수의 제2 클립 데이터들 생성 시 제공되는 텍스트 데이터를 대응시켜 오디오 데이터, 이미지 데이터 및 텍스트 데이터의 쌍의 상기 트레이닝 데이터 세트를 생성하는 단계를 포함하는 방법. |
| 10 | 제9항에 있어서,상기 이미지 데이터를 추출하는 단계는,상기 비디오 프레임들의 이미지 핑거프린트(fingerprint)의 유사도에 기초하여 이미지를 제거하고 남은 이미지를 클러스터링하여 상기 이미지 데이터로 구성하는 단계를 포함하는 방법. |
| 11 | 제9항에 있어서,상기 트레이닝 데이터를 생성하는 단계는,상기 음성 분리 오디오 데이터를 생성한 이후, 상기 음성 분리 오디오 데이터를 스펙트로그램(Spectrogram) 이미지로 변환하는 단계를 더 포함하는 방법. |
| 12 | 사전-트레이닝된 텍스트 인코더를 통해 오디오 데이터, 이미지 데이터 및 텍스트 데이터를 포함하는 트레이닝 데이터 세트 중 텍스트 데이터를 오디오 생성 모델의 텍스트 조건 형태로 변환하고, 상기 변환된 텍스트 조건 형태 및 상기 트레이닝 데이터 세트 중 오디오 데이터에 기초하여, 상기 오디오 생성 모델의 텍스트 기반 손실을 산출하고, 상기 산출된 텍스트 기반 손실이 최소화되도록 상기 오디오 생성 모델을 트레이닝시켜 텍스트 기반 오디오 생성 파라미터를 결정하며,상기 트레이닝 데이터 세트 중 이미지 데이터를 사전-트레이닝된 이미지 인코더를 통해 상기 오디오 생성 모델의 이미지 조건 형태로 변환하고, 상기 텍스트 기반 오디오 생성 파라미터, 상기 변환된 이미지 조건 형태 및 상기 트레이닝 데이터 세트 중 오디오 데이터에 기초하여, 상기 오디오 생성 모델의 텍스트 및 이미지 기반 손실을 산출하고, 상기 산출된 텍스트 및 이미지 기반 손실이 최소화되도록 상기 오디오 생성 모델을 트레이닝시켜 텍스트 및 이미지 기반 오디오 생성 파라미터를 결정하는 프로세서를 포함하고,상기 프로세서는,상기 오디오 생성 모델을 트레이닝시키기 이전에, 상기 트레이닝 데이터 세트를 생성하며,상기 트레이닝 데이터 세트를 생성함에 있어서, 영상 데이터로부터 제1 지속 시간의 복수의 제1 클립 데이터들을 생성하고, 상기 영상 데이터로부터 상기 제1 지속 시간보다 짧은 시간 길이인 제2 지속 시간의 복수의 제2 클립 데이터들을 생성하고, 상기 제1 지속 시간에 대응되는 시간 길이가 되도록 상기 복수의 제2 클립 데이터들을 연결시키고, 상기 복수의 제1 클립 데이터들과 상기 연결된 복수의 제2 클립 데이터들을 병합시켜 복수의 원시 클립 데이터를 생성하며, 상기 복수의 원시 클립 데이터로부터 추출된 이미지 데이터 및 음성 분리 오디오 데이터와 이에 기반한 텍스트 데이터에 기초하여 복수의 상기 트레이닝 데이터 세트를 생성하는, 장치. |
| 13 | 제12항에 있어서,상기 프로세서는,상기 텍스트 인코더에 상기 텍스트 데이터를 입력하여 텍스트 임베딩을 추출하는,장치. |
| 14 | 제13항에 있어서,상기 프로세서는,상기 오디오 데이터를 참값으로 하여, 상기 오디오 생성 모델의 인코더를 통해 픽셀 공간의 고 차원 참값을 잠재 공간의 저 차원 참값으로 변환하고, 상기 변환된 저 차원 참값을 상기 오디오 생성 모델을 통해 디퓨전하여 노이즈가 삽입된 저 차원 참값을 생성하고, 상기 텍스트 임베딩을 조건으로 상기 오디오 생성 모델을 통해 상기 노이즈가 삽입된 저 차원 참값을 디노이징하여 노이즈가 제거된 저 차원 예측값을 생성하고, 상기 오디오 생성 모델의 디코더를 통해 저 차원 예측값을 고 차원 예측값으로 변환하며, 상기 고 차원 참값과 상기 고 차원 예측값 간의 텍스트 기반 손실을 산출하는,장치. |
| 15 | 제12항에 있어서,상기 프로세서는,상기 이미지 인코더에 상기 이미지 데이터를 입력하여 이미지 임베딩을 추출하는,장치. |
| 16 | 제15항에 있어서,상기 프로세서는,상기 오디오 데이터를 참값으로 하여, 상기 오디오 생성 모델의 인코더를 통해 픽셀 공간의 고 차원 참값을 잠재 공간의 저 차원 참값으로 변환하고, 상기 변환된 저 차원 참값을 상기 오디오 생성 모델을 통해 디퓨전하여 노이즈가 삽입된 저 차원 참값을 생성하고, 상기 이미지 임베딩 및 텍스트 임베딩을 조건으로 상기 텍스트 기반 오디오 생성 파라미터가 적용된 상기 오디오 생성 모델을 통해 상기 노이즈가 삽입된 저 차원 참값을 디노이징하여 노이즈가 제거된 저 차원 예측값을 생성하고, 상기 오디오 생성 모델의 디코더를 통해 저 차원 예측값을 고 차원 예측값으로 변환하며, 상기 고 차원 참값과 상기 고 차원 예측값 간의 텍스트 및 이미지 기반 손실을 산출하는,장치. |
| 17 | 제12항에 있어서,상기 프로세서는,상기 텍스트 기반 오디오 생성 파라미터를 결정한 이후, 상기 트레이닝 데이터 세트 중 이미지 데이터로부터 하나 이상의 단어들을 추출하고, 사전-트레이닝된 텍스트 인코더를 통해 상기 추출된 하나 이상의 단어들에서 이미지 기반 텍스트 임베딩을 추출하고, 상기 추출된 이미지 기반 텍스트 임베딩, 상기 텍스트 기반 오디오 생성 파라미터 및 상기 트레이닝 데이터 세트 중 오디오 데이터에 기초하여, 상기 오디오 생성 모델의 이미지 기반 손실을 산출하며, 상기 산출된 이미지 기반 손실이 최소화되도록 상기 오디오 생성 모델을 트레이닝시켜 이미지 기반 오디오 생성 파라미터를 결정하는,장치. |
| 18 | 삭제 |
| 19 | 삭제 |
| 20 | 제12항에 있어서,상기 프로세서는,상기 원시 클립 데이터로부터 비디오 프레임들을 추출하고, 상기 추출된 비디오 프레임들을 클러스터링하여 하나 이상의 상기 이미지 데이터를 추출하고, 상기 원시 클립 데이터로부터 원시 오디오를 추출하고, 상기 추출된 원시 오디오에서 음성을 분리하여 상기 음성 분리 오디오 데이터를 생성하고, 상기 이미지 데이터와 상기 음성 분리 오디오 데이터에 상기 복수의 제1 클립 데이터들 및 상기 복수의 제2 클립 데이터들 생성 시 제공되는 텍스트 데이터를 대응시켜 오디오 데이터, 이미지 데이터 및 텍스트 데이터의 쌍의 상기 트레이닝 데이터 세트를 생성하는,장치. |
| 21 | 제20항에 있어서,상기 프로세서는,상기 비디오 프레임들의 이미지 핑거프린트의 유사도에 기초하여 이미지를 제거하고 남은 이미지를 클러스터링하여 상기 이미지 데이터로 구성하는,장치. |
| 22 | 제20항에 있어서,상기 프로세서는,상기 음성 분리 오디오 데이터를 생성한 이후, 상기 음성 분리 오디오 데이터를 스펙트로그램 이미지로 변환하는,장치. |