| 번호 | 청구항 |
|---|---|
| 1 | 서브 그래프 탐색 장치에 의해 구현되는 서브 그래프 탐색 방법에 있어서,질의 그래프의 입력에 따라,상기 서브 그래프 탐색 장치 내 계산부에서, 상기 질의 그래프에 포함되는 정점 각각에 대해, 데이터 그래프에서의, 이웃하는 정점의 수와 간선의 수를 고려하여 필터링 스코어를 계산하는 단계;상기 서브 그래프 탐색 장치 내 결정부에서, 상기 질의 그래프 내 정점들 중에서, 상기 필터링 스코어가 가장 높게 계산되는 기준 정점을 결정하는 단계;상기 서브 그래프 탐색 장치 내 분리부에서, 상기 기준 정점을 이용하여, 상기 질의 그래프 내 정점들을, 복수의 정점그룹으로 분리하는 단계; 및상기 서브 그래프 탐색 장치 내 검색부에서, 상기 데이터 그래프로부터 상기 복수의 정점그룹에 대응하는 복수의 서브그룹으로 연결되는 서브 그래프를 검색하는 단계를 포함하고,상기 필터링 스코어를 계산하는 단계는,상기 정점과, 상기 정점 각각이 갖는 간선 수가 분포되는 정도에 따라, 상기 데이터 그래프를 정규분포로 구분하는 단계; 및상기 정규분포와 관련되는 확률밀도함수 1 을 통해, 상기 정점 각각에 대해 상기 필터링 스코어 normalFS를 계산하는 단계-상기 μ는 상기 정점에 대한 평균 차수이고, 상기 σ은 상기 정점에 대한 표준편차임--상기 정규분포의 필터링 확률 FPND(Vi)가 일 경우, 상기 normalFS는 를 만족함--상기 QL(υi)는 레이블 L를 갖는 질의 그래프 정점의 차수이고, 상기 GL(υi)는 레이블 L를 갖는 데이터 그래프 정점의 차수이며, 상기 GL은 레이블 L을 갖는 데이터의 정점이고, 상기 Gall은 데이터 그래프 전체 정점임-를 포함하는 서브 그래프 탐색 방법. |
| 2 | 제1항에 있어서,상기 분리하는 단계는,상기 기준 정점을 기준으로, 적어도 하나의 간선으로 연결되는 정점의 쌍 각각을 상기 복수의 정점그룹으로 분리하는 단계를 포함하는 서브 그래프 탐색 방법. |
| 3 | 제1항에 있어서,상기 서브 그래프를 검색하는 단계는,상기 기준 정점과 연관되는 제1 정점그룹에 대응하는, 상기 데이터 그래프 내 제1 서브그룹을 식별하는 단계;상기 제1 정점그룹을 구성하는 제1 이웃 정점과 연관되는 제2 정점그룹에 대응하는, 상기 데이터 그래프 내 제2 서브그룹을 식별하는 식별단계; 및상기 제2 정점그룹을 구성하는 제2 이웃 정점과 연관되는 정점그룹이 존재하지 않을 때까지 상기 제2 이웃 정점에 대해 상기 식별단계를 반복한 후, 식별되는 상기 제1 서브그룹 및 상기 제2 서브그룹을 연결하여 상기 서브 그래프로서 검색하는 단계를 포함하는 서브 그래프 탐색 방법. |
| 4 | 제3항에 있어서,상기 서브 그래프를 검색하는 단계는,상기 기준 정점, 상기 제1 이웃 정점, 및 상기 제2 이웃 정점 중 어느 하나가 갖는 간선의 선(차수) 보다 적은 간선 수(차수)의 정점을 포함하는, 상기 데이터 그래프 내 서브그룹을 배제하여 상기 제2 서브그룹을 식별하는 단계를 더 포함하는 서브 그래프 탐색 방법. |
| 5 | 삭제 |
| 6 | 제1항에 있어서,상기 필터링 스코어를 계산하는 단계는,상기 정점과, 상기 정점 각각이 갖는 간선 수가 분포되는 정도에 따라, 상기 데이터 그래프를 power-law 분포로 구분하는 단계; 및상기 power-law 분포와 관련되는 확률밀도함수 2 를 통해, 상기 정점 각각에 대해 상기 필터링 스코어 powerFS를 계산하는 단계-상기 power-law 분포의 필터링 확률 FPPD(Vi)가 일 경우, 상기 powerFS는 를 만족함-를 더 포함하는 서브 그래프 탐색 방법. |
| 7 | 제1항에 있어서,상기 필터링 스코어를 계산하는 단계는,상기 정점에 대한 평균 차수 를 통해, 상기 정점 각각에 대해 상기 필터링 스코어 avgDgFS를 계산하는 단계-상기 avgDgFS은 을 만족함-를 포함하는 서브 그래프 탐색 방법. |
| 8 | 제1항에 있어서,상기 서브 그래프를 검색하는 단계는,상기 질의 그래프 내 정점 사이에 간선의 연결 방향과, 상기 정점 사이의 거리에 대해, 유사성이 있는, 상기 서브 그래프 내 정점을 검색하는 단계를 포함하는 서브 그래프 탐색 방법. |
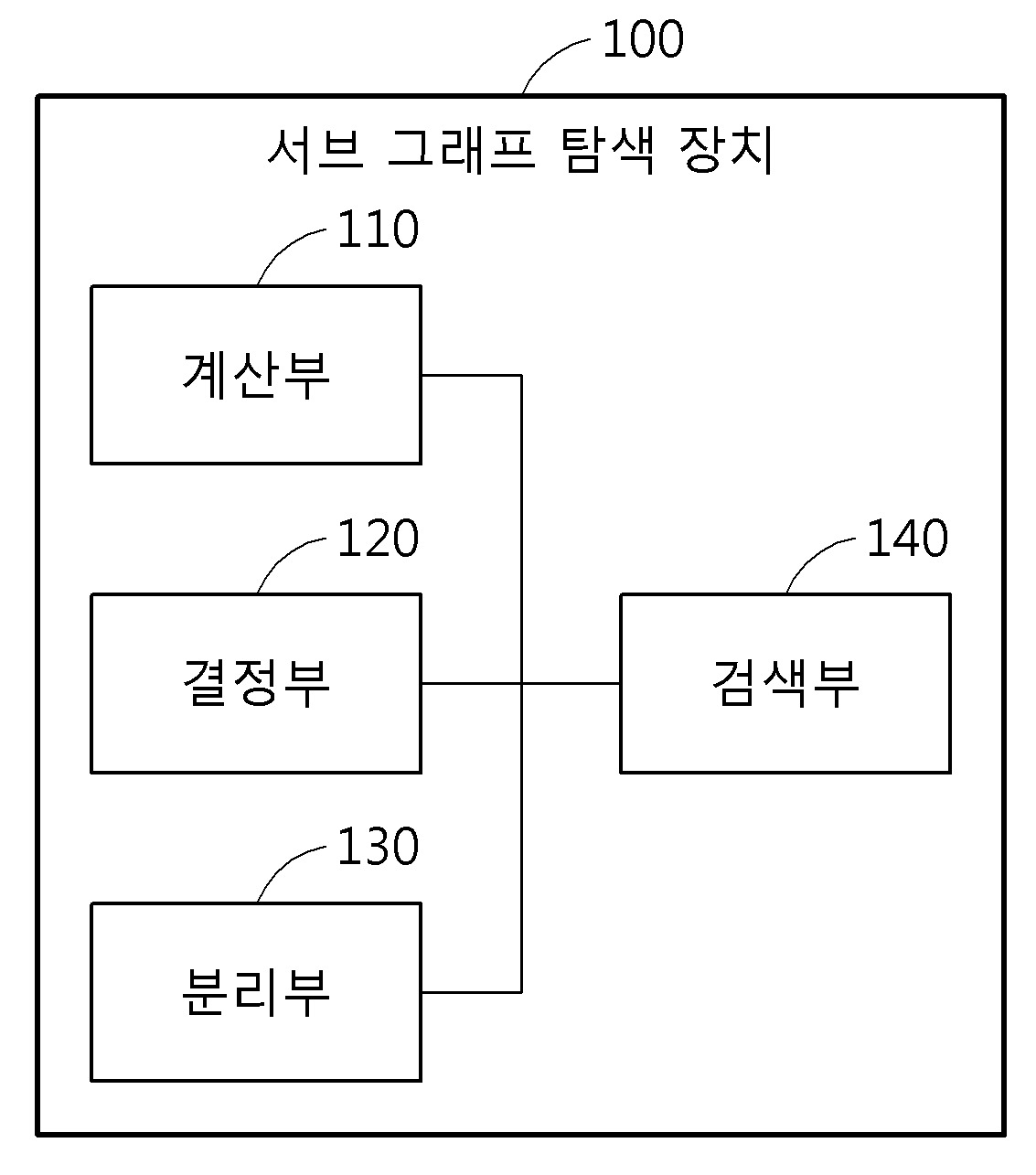
| 9 | 질의 그래프의 입력에 따라,상기 질의 그래프에 포함되는 정점 각각에 대해, 데이터 그래프에서의, 이웃하는 정점의 수와 간선의 수를 고려하여 필터링 스코어를 계산하는 계산부;상기 질의 그래프 내 정점들 중에서, 상기 필터링 스코어가 가장 높게 계산되는 기준 정점을 결정하는 결정부;상기 기준 정점을 이용하여, 상기 질의 그래프 내 정점들을, 복수의 정점그룹으로 분리하는 분리부; 및상기 데이터 그래프로부터 상기 복수의 정점그룹에 대응하는 복수의 서브그룹으로 연결되는 서브 그래프를 검색하는 검색부를 포함하고,상기 계산부는,상기 정점과, 상기 정점 각각이 갖는 간선 수가 분포되는 정도에 따라, 상기 데이터 그래프를 정규분포로 구분하고,상기 정규분포와 관련되는 확률밀도함수 1 을 통해, 상기 정점 각각에 대해 상기 필터링 스코어 normalFS를 계산하는-상기 u는 상기 정점에 대한 평균 차수이고, 상기 σ은 상기 정점에 대한 표준편차임--상기 정규분포의 필터링 확률 FPND(Vi)가 일 경우, 상기 normalFS는 를 만족함--상기 QL(υi)는 레이블 L을 갖는 질의 그래프 정점에 대한 차수이고, 상기 GL(υi)는 레이블 L을 갖는 데이터 그래프 정점에 대한 차수이며, 상기 GL은 레이블 L을 갖는 데이터 그래프의 정점이고, 상기 Gall은 데이터 그래프의 전체 정점임-서브 그래프 탐색 장치. |
| 10 | 제9항에 있어서,상기 분리부는,상기 기준 정점을 기준으로, 적어도 하나의 간선으로 연결되는 정점의 쌍 각각을 상기 복수의 정점그룹으로 분리하는서브 그래프 탐색 장치. |
| 11 | 제9항에 있어서,상기 검색부는,상기 기준 정점과 연관되는 제1 정점그룹에 대응하는, 상기 데이터 그래프 내 제1 서브그룹을 식별하고,상기 제1 정점그룹을 구성하는 제1 이웃 정점과 연관되는 제2 정점그룹에 대응하는, 상기 데이터 그래프 내 제2 서브그룹을 식별하는 식별단계를 수행하며,상기 제2 정점그룹을 구성하는 제2 이웃 정점과 연관되는 정점그룹이 존재하지 않을 때까지 상기 제2 이웃 정점에 대해 상기 식별단계를 반복한 후, 식별되는 상기 제1 서브그룹 및 상기 제2 서브그룹을 연결하여 상기 서브 그래프로서 검색하는서브 그래프 탐색 장치. |
| 12 | 제11항에 있어서,상기 검색부는,상기 기준 정점, 상기 제1 이웃 정점, 및 상기 제2 이웃 정점 중 어느 하나가 갖는 간선의 선(차수) 보다 적은 간선 수(차수)의 정점을 포함하는, 상기 데이터 그래프 내 서브그룹을 배제하여 상기 제2 서브그룹을 식별하는서브 그래프 탐색 장치. |
| 13 | 삭제 |
| 14 | 제9항에 있어서,상기 계산부는,상기 정점과, 상기 정점 각각이 갖는 간선 수가 분포되는 정도에 따라, 상기 데이터 그래프를 power-law 분포로 구분하고,상기 power-law 분포와 관련되는 확률밀도함수 2 를 통해, 상기 정점 각각에 대해 상기 필터링 스코어 powerFS를 계산하는-상기 power-law 분포의 필터링 확률 FPPD(Vi)가 일 경우, 상기 powerFS는 를 만족함-서브 그래프 탐색 장치. |
| 15 | 제9항에 있어서,상기 계산부는,상기 정점에 대한 평균 차수 를 통해, 상기 정점 각각에 대해 상기 필터링 스코어 avgDgFS를 계산하는-상기 avgDgFS은 을 만족함-서브 그래프 탐색 장치. |
| 16 | 제9항에 있어서,상기 검색부는,상기 질의 그래프 내 정점 사이에 간선의 연결 방향과, 상기 정점 사이의 거리에 대해, 유사성이 있는, 상기 서브 그래프 내 정점을 검색하는서브 그래프 탐색 장치. |