| 번호 | 청구항 |
|---|---|
| 1 |
|
| 2 | 제 1항에 있어서, 상기 단계 1)의 특징 벡터는 단백질 및 DNA 서열 데이터만 주어졌을 때, 결합부위 예측에 효과적인 특징을 표현하는 것을 특징으로 하는 DNA 서열에서 단백질과 결합하는 염기 예측 방법. |
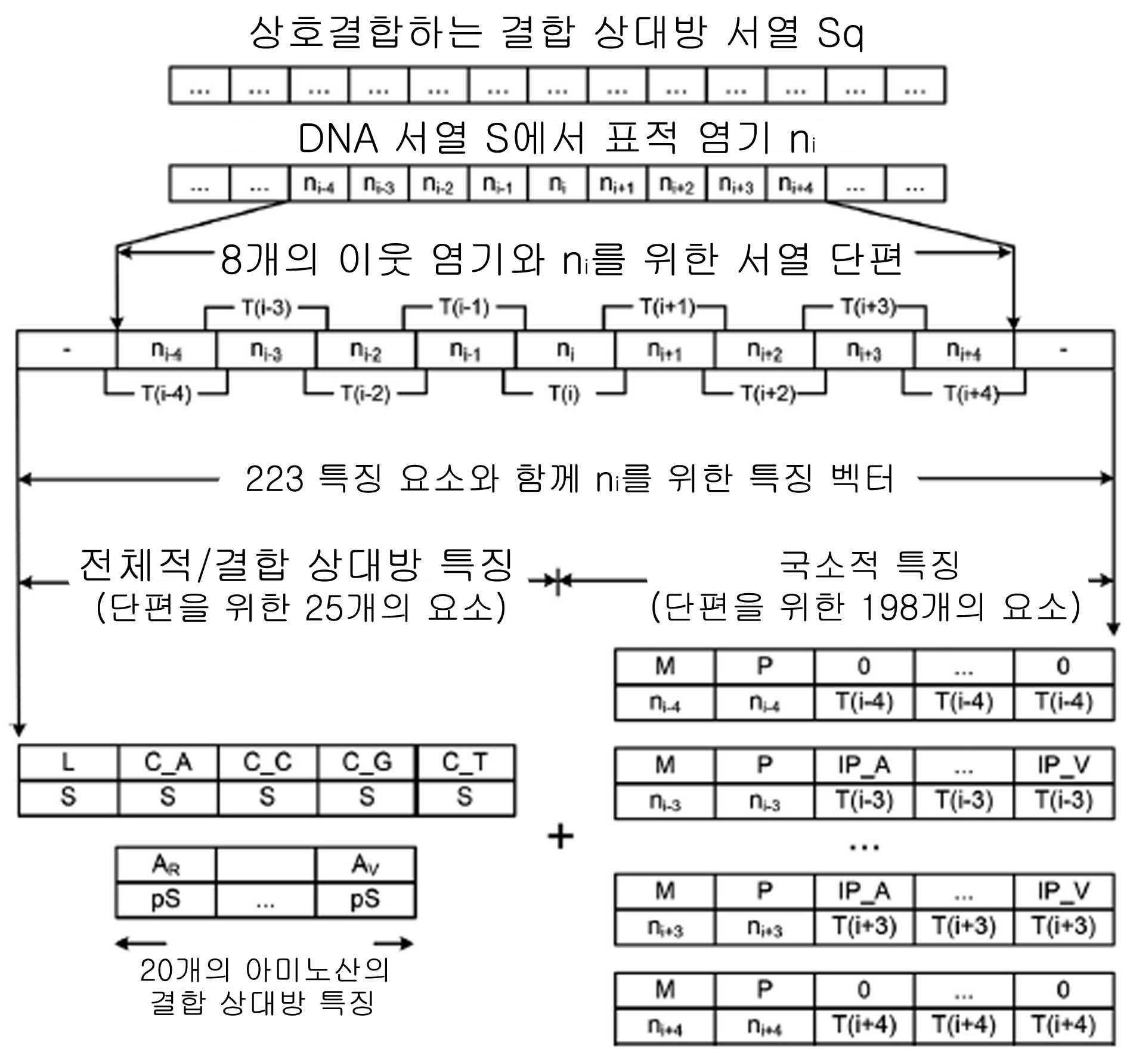
| 3 | 제 1항에 있어서, 상기 단계 1)의 특징 벡터의 구성요소로서 표현되는 단백질 및 DNA 서열의 특징은,전체 DNA 서열에 대한 정보를 표현하는 DNA 전체적 특징(global features);DNA 개별 염기 또는 DNA 염기 트리플렛(nucleotide triplets)에 대한 정보를 표현하는 DNA 국소적 특징(local features); 및DNA에 결합하는 단백질의 특징을 표현하는 결합 상대방 특징(partner features)을 포함하는 것을 특징으로 하는 DNA 서열에서 단백질과 결합하는 염기 예측 방법. |
| 4 | 제 3항에 있어서, DNA 전체적 특징은 서열 길이 및 서열 구성요소(composition)를 포함하는 전체 DNA 서열 정보(information)를 특징 벡터 표현에 구성요소로 사용하는 것을 특징으로 하는 DNA 서열에서 단백질과 결합하는 염기 예측 방법. |
| 5 | 제 3항에 있어서, 상기 DNA 국소적 특징은 염기 분자량(molecular mass, M), 염기 pKa(P), 및 염기 트리플렛의 결합성향(IP)을 특징 벡터 표현에 구성요소로 사용하는 것을 특징으로 하는 DNA 서열에서 단백질과 결합하는 염기 예측 방법. |
| 6 | 제 5항에 있어서, 상기 염기 트리플렛의 결합성향(interaction propensity, IP)은 하기 수학식 1로 계산되는 것을 특징으로 하는 DNA 서열에서 단백질과 결합하는 염기 예측 방법:[수학식 1].(상기 식에서, ∠DAH는 DNA 염기와 아미노산의 수소결합에서 공여체-수용체-수소(donor-acceptor-hydrogen, D-A-H)의 각도이고, HAcos(∠DAH)는 수소-수용체(H-A)의 길이를 공여체-수용체(D-A) 방향으로 투영한 길이이며, ∑Nij는 어떠한 아미노산에 결합하는 염기 트리플렛의 총 합이고, ∑Ni는 염기 트리플렛의 총 합이며, ∑Nj는 아미노산의 총합이다). |
| 7 | 제 3항에 있어서, 상기 결합 상대방 특징 Pb는 하기 수학식 2 및 3으로 계산되는 DNA와 결합하는 단백질 서열의 정보를 포함하는 것을 특징으로 하는 DNA 서열에서 단백질과 결합하는 염기 예측 방법:[수학식 2], 및[수학식 3](상기 식에서, i는 단백질 서열에서 아미노산의 위치번호, b는 20개 아미노산 중 하나, bi는 단백질의 i번째 아미노산 b를 나타낸다.). |
| 8 | 제 1항에 있어서, 상기 단계 2)는,1) 단백질-DNA 상호작용 쌍들에 존재하는 모든 DNA 및 단백질 서열에서 슬라이딩 윈도우(silding window) 기법을 이용한 서열 조각을 생성하는 공정;2) 생성된 서열 조각을 DNA 서열의 전체적 특징, DNA 염기의 국소적 특징 및 결합 상대방의 특징을 이용하여 특징 벡터에 표현하는 공정; 및3) 표현된 특징 벡터에서 특징 벡터 기반의 중복 제거 기법을 통한 학습 데이터를 구축하는 것을 특징으로 하는 DNA 서열에서 단백질과 결합하는 염기 예측 방법. |
| 9 | 제 1항에 있어서, 상기 방법은,1) DNA의 결합 상대방인 단백질 서열을 지정하지 않은 경우, 상대방을 고려하지 않은 모델로 단백질 결합 DNA 염기 예측; 및2) DNA의 결합 상대방인 단백질 서열이 주어지는 경우, 상대방을 고려한 모델로 단백질 결합 DNA 염기를 예측하는 것을 특징으로 하는 DNA 서열에서 단백질과 결합하는 염기 예측방법. |
| 10 |
|
| 11 | 제 10항에 있어서, 상기 단계 3)의 복수의 척도는 민감도(sensitivity, Sn), 특이도(specificity, Sp), 정확도(accuracy, Acc), 양성예측도(positive predictive value, PPV), 음성예측도(negative predictive value, NPV), F-측정(F-measure) 및 매튜 상관관계 계수(matthews correlation coefficient, MCC)인 것을 특징으로 하는 DNA 서열에서 단백질과 결합하는 DNA 염기 예측 평가 방법. |