| 번호 | 청구항 |
|---|---|
| 5 | 제1항에 있어서,상기 프로세서는, 현재 상황 및 스킬을 조합하여 다음 상황을 추론하기 위한 스킬 스텝 동역학 모델을 훈련시키되, 상기 스킬 스텝 역동역학 모델은 상기 스킬 스텝 동역학 모델의 역변환인 목적 지향 정책 학습 장치. |
| 3 | 제2항에 있어서,상기 적어도 하나의 동역학 모델은, 단일 타임스텝 하에서 스킬을 실행하여 현재의 상태에서 다음의 상태에 대한 상태 임베딩을 예측하기 위한 평탄 동역학 모델을 포함하고,상기 프로세서는, 상태 임베딩과, 상기 평탄 동역학 모델과, 상기 스킬 스텝 동역학 모델을 함께 최적화하여 모델 정제를 수행하는 목적 지향 정책 학습 장치. |
| 4 | 제1항에 있어서,상기 프로세서는, 상기 저장부에 저장된 시퀀스의 전부 또는 일부를 스킬로 인코딩하고, 상기 스킬 사전분포를 획득하는 스킬 인코더; 및상기 스킬을 디코딩하여 행동을 추론하는 스킬 디코더;를 포함하는 목적 지향 정책 학습 장치. |
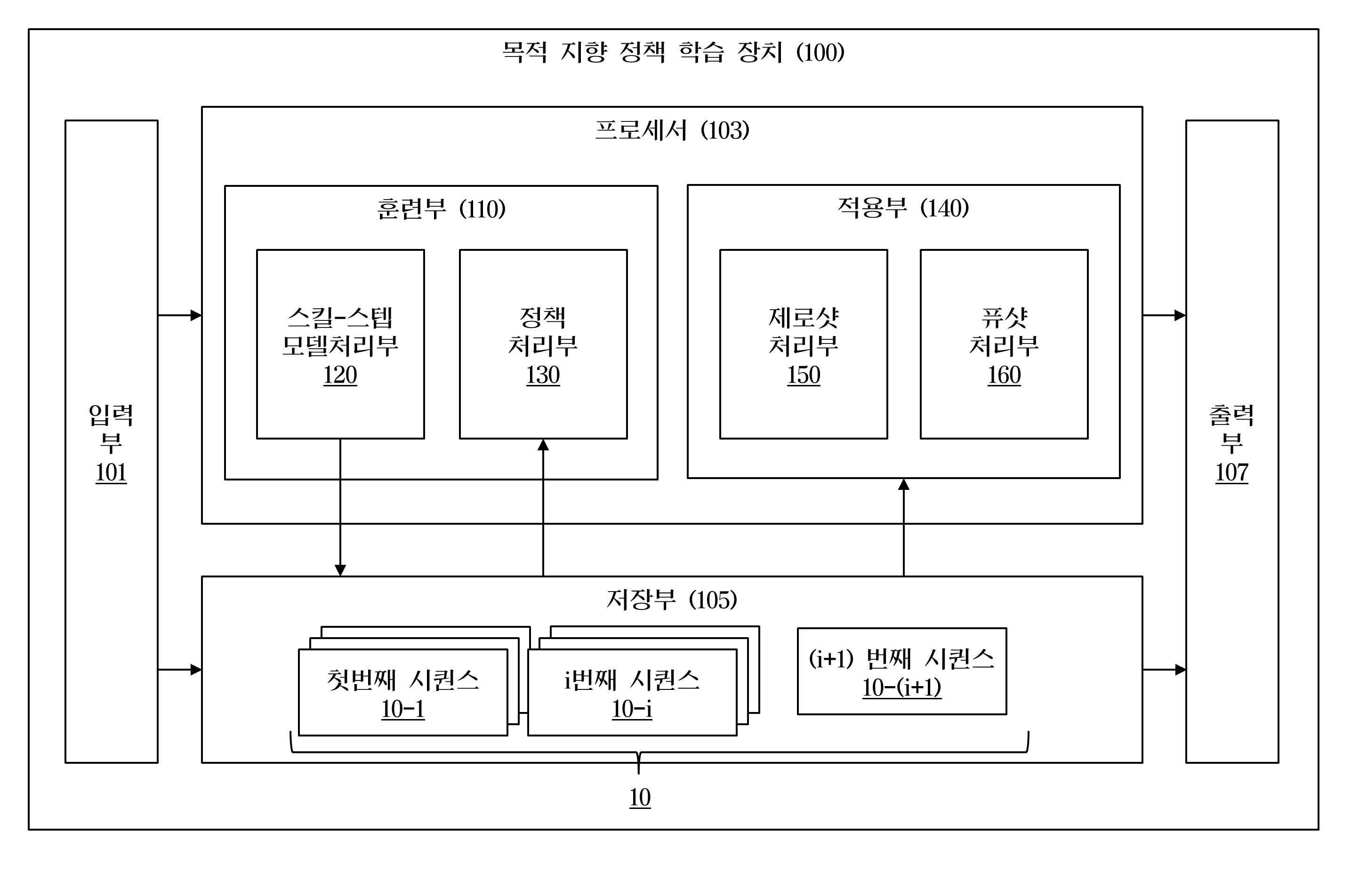
| 1 | 시퀀스를 저장하는 저장부; 및상기 시퀀스를 기초로 최종 목적에 상응하는 적어도 하나의 서브 목적을 결정하고, 스킬 스텝 역동역학 모델을 이용하여 상기 서브 목적에 대응하는 적어도 하나의 스킬을 획득하고, 상기 적어도 하나의 스킬을 디코딩하여 행동을 결정하되, 상기 스킬 스텝 역동역학 모델은 현재 상황 및 다음 상황을 기초로 스킬을 추론하기 위한 모델을 포함하는 프로세서;를 포함하는 목적 지향 정책 학습 장치. |
| 2 | 제1항에 있어서,상기 프로세서는, 상기 저장부에 저장된 시퀀스를 기초로 새로운 시퀀스를 생성하되,상기 저장부로부터 적어도 하나의 시퀀스를 샘플링하여 획득하고,샘플링된 시퀀스로부터 적어도 하나의 분기 상태를 선택하고,스킬 사전분포를 이용하여 상기 적어도 하나의 분기 상태 각각에 대응하는 스킬을 획득하고,적어도 하나의 동역학 모델을 기반으로 잠재 공간 및 스킬 임베딩을 획득하고,상기 잠재 공간 및 스킬 임베딩을 기초로 디코딩을 수행하여 적어도 하나의 새로운 시퀀스를 획득하는 목적 지향 정책 학습 장치. |
| 6 | 제1항에 있어서,시퀀스를 저장하는 저장부; 및상기 저장부로부터 적어도 하나의 시퀀스를 샘플링하여 획득하고, 샘플링된 시퀀스로부터 적어도 하나의 분기 상태를 선택하고, 스킬 사전분포를 이용하여 상기 적어도 하나의 분기 상태 각각에 대응하는 스킬을 획득하고, 적어도 하나의 동역학 모델을 기반으로 잠재 공간 및 스킬 임베딩을 획득하고, 상기 잠재 공간 및 스킬 임베딩을 기초로 디코딩을 수행하여 적어도 하나의 새로운 시퀀스를 획득하는 프로세서;를 포함하는 목적 지향 정책 학습 장치. |
| 7 | 시퀀스를 기초로 최종 목적에 상응하는 적어도 하나의 서브 목적을 결정하는 단계;스킬 스텝 역동역학 모델을 이용하여 상기 서브 목적에 대응하는 적어도 하나의 스킬을 획득 하는 단계; 및상기 적어도 하나의 스킬을 디코딩하여 행동을 결정하되, 상기 스킬 스텝 역동역학 모델은 현재 상황 및 다음 상황을 기초로 스킬을 추론하기 위한 모델을 포함하는 하는 단계;를 포함하는 목적 지향 정책 학습 방법. |
| 8 | 제7항에 있어서,상기 시퀀스를 기초로 새로운 시퀀스를 생성하는 단계;를 더 포함하고,상기 시퀀스를 기초로 새로운 시퀀스를 생성하는 단계는,적어도 하나의 시퀀스를 샘플링하여 획득하는 단계;샘플링된 시퀀스로부터 적어도 하나의 분기 상태를 선택하는 단계;스킬 사전분포를 이용하여 상기 적어도 하나의 분기 상태 각각에 대응하는 스킬을 획득하는 단계;적어도 하나의 동역학 모델을 기반으로 잠재 공간 및 스킬 임베딩을 획득하는 단계; 및상기 잠재 공간 및 스킬 임베딩을 기초로 디코딩을 수행하여 적어도 하나의 새로운 시퀀스를 획득하는 단계;를 포함하는 목적 지향 정책 학습 방법. |
| 9 | 제8항에 있어서,상태 임베딩, 평탄 동역학 모델 및 상기 스킬 스텝 동역학 모델을 함께 최적화하여 모델 정제를 수행하는 단계;를 더 포함하고,상기 평탄 동역학 모델은, 단일 타임스텝 하에서 스킬을 실행하여 현재의 상태에서 다음의 상태에 대한 상태 임베딩을 예측하기 위한 동역학 모델을 포함하는 목적 지향 정책 학습 방법. |
| 10 | 제7항에 있어서,스킬 인코더가 상기 시퀀스의 전부 또는 일부를 스킬로 인코딩하고, 상기 스킬 사전분포를 획득하는 단계; 및스킬 디코더가 상기 스킬을 디코딩하여 행동을 추론하는 단계;를 포함하는 목적 지향 정책 학습 방법. |
| 11 | 제7항에 있어서,현재 상황 및 스킬을 조합하여 다음 상황을 추론하기 위한 스킬 스텝 동역학 모델을 훈련시키는 단계;를 더 포함하고,상기 스킬 스텝 역동역학 모델은 상기 스킬 스텝 동역학 모델의 역변환인 목적 지향 정책 학습 방법. |
| 12 | 적어도 하나의 시퀀스를 샘플링하여 획득하는 단계;샘플링된 시퀀스로부터 적어도 하나의 분기 상태를 선택하는 단계;스킬 사전분포를 이용하여 상기 적어도 하나의 분기 상태 각각에 대응하는 스킬을 획득하는 단계;적어도 하나의 동역학 모델을 기반으로 잠재 공간 및 스킬 임베딩을 획득하는 단계; 및상기 잠재 공간 및 스킬 임베딩을 기초로 디코딩을 수행하여 적어도 하나의 새로운 시퀀스를 획득하는 단계;를 포함하는 목적 지향 정책 학습 방법. |