| 번호 | 청구항 |
|---|---|
| 3 | 제2항에 있어서,상기 인코더 프롬프트 풀은 프리픽스 프롬프트 및 포스트픽스 프롬프트를 포함하는 것을 특징으로 하는 SLM을 위한 정책 생성방법. |
| 2 | 제1항에 있어서,상기 계획정책을 학습하는 단계에 있어서,상기 추론된 추론정책의 근거집합은, 상기 추론정책 학습 단계를 수행하면서 인코더 프롬프트 풀에 기초한 인코더의 정책, 디코더 프롬프트 풀에 기초한 디코더의 정책 및 어텐션 모듈에 기초하여 생성되는 것을 특징으로 하는 SLM을 위한 정책 생성방법. |
| 1 | 전문 데이터셋을 수신받는 단계;상기 전문 데이터셋과 미리 저장된 초기 근거집합에 기초하여 근거 데이터셋을 생성하는 단계;상기 근거 데이터셋을 자기 검증 함수를 통해 검증하는 단계;상기 검증된 근거 데이터셋에 기초하여 체화된 지식 그래프를 통해 추론정책을 학습하는 단계;상기 학습된 추론정책의 근거집합 및 계획정책 재구성 손실에 기초하여 계획정책을 학습하는 단계; 및상기 학습된 추론정책 및 계획정책에 기초하여 최종 추론정책 및 계획정책을 포함하는 SLM 정책을 생성하는 단계;를 포함하는 SLM을 위한 정책 생성방법. |
| 4 | 제2항에 있어서,상기 추론된 추론정책의 근거집합은 근거 및 지식 그래프 검색 함수를 통해 추출된 그래프에 기초한 근거 재구성 손실을 통해 생성되는 것을 특징으로 하는 SLM을 위한 정책 생성방법. |
| 5 | 제4항에 있어서,상기 근거 재구성 손실은 수학식(여기서, :근거 재구성 손실, o: 관측, h: 작업 설명, R: 근거집합, : 근거, g: 지식 그래프 검색 함수를 통해 추출된 그래프)인 것을 특징으로 하는 SLM을 위한 정책 생성방법. |
| 6 | 제1항에 있어서,상기 추론정책을 학습하는 단계에 있어서,상기 체화된 지식 그래프는 프롬프트된 지식 그래프인 것을 특징으로 하는 SLM을 위한 정책 생성방법. |
| 7 | 제6항에 있어서,상기 프롬프트된 지식 그래프는 동일한 계획을 실행하는 체화된 지식 그래프인 긍정 페어 및 연속적인 계획 단계인 부정 페어를 포함하는 배치 샘플에 기초한 것을 특징으로 하는 SLM을 위한 정책 생성방법. |
| 8 | 제6항에 있어서,상기 프롬프트된 지식 그래프는 대조 학습 손실에 기초한 것을 특징으로하고, 상기 대조 학습 손실은 수학식(여기서, :대조 학습 손실, : 배치 샘플, : 임베딩 공간, d: 임베딩 공간 ∈Z 내에서 각 근거 임베딩 시퀀스의 요소에 해당하는 거리 메트릭의 합, : 마진 파라미터)인 것을 특징으로 하는 SLM을 위한 정책 생성방법. |
| 9 | 제1항에 있어서,상기 계획정책을 학습하는 단계에 있어서,상기 계획정책은 상기 학습된 추론정책의 근거집합에 기초하여 다음 계획(a)을 예측하여 학습되고, 수학식(여기서, :계획정책, R: 추론정책의 근거집합, : 추론정책, g: 지식 그래프 검색 함수를 통해 추출된 그래프, a: 다음 계획)을 통해 학습되는 것을 특징으로 하는 SLM을 위한 정책 생성방법. |
| 10 | 제1항에 있어서,상기 상기 계획정책 재구성 손실은 수학식(여기서, : 계획정책 재구성 손실, o: 관측, h: 작업 설명, R: 근거집합, :계획정책, a: 다음 계획)인 것을 특징으로 하는 SLM을 위한 정책 생성방법. |
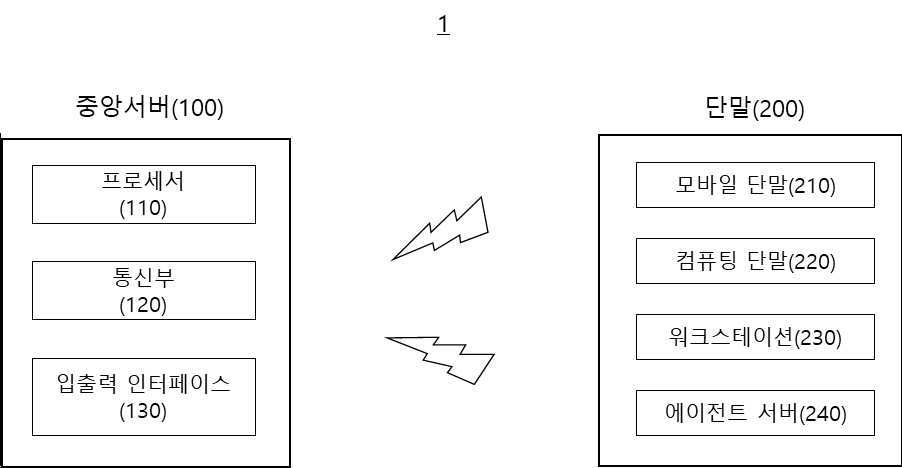
| 11 | 전문 데이터셋을 수신받는 입출력 인터페이스;상기 전문 데이터셋에 기초하여 SLM 정책을 생성하는 프로세서; 및상기 생성된 SLM 정책을 단말로 송신하는 통신부;를 포함하고,상기 프로세서는 상기 전문 데이터셋과 미리 저장된 초기 근거집합에 기초하여 근거 데이터셋을 생성하고, 상기 근거 데이터셋을 자기 검증 함수를 통해 검증하고, 상기 검증된 근거 데이터셋에 기초하여 체화된 지식 그래프를 통해 추론정책을 학습하고, 상기 학습된 추론정책의 근거집합 및 계획정책 재구성 손실에 기초하여 계획정책을 학습하고, 상기 학습된 추론정책 및 계획정책에 기초하여 최종 추론정책 및 계획정책을 포함하는 SLM 정책을 생성하는 것을 특징으로 하는 SLM을 위한 정책 생성장치. |
| 12 | 제11항에 있어서,상기 프로세서는,상기 계획 정책을 학습하는 경우 상기 추론된 추론정책의 근거집합은, 상기 추론정책 학습 단계를 수행하면서 인코더 프롬프트 풀에 기초한 인코더의 정책, 디코더 프롬프트 풀에 기초한 디코더의 정책 및 어텐션 모듈에 기초하여 생성되고,상기 인코더 프롬프트 풀은 프리픽스 프롬프트 및 포스트픽스 프롬프트를 포함하는 것을 특징으로 하는 SLM을 위한 정책 생성장치. |
| 13 | 제12항에 있어서,상기 프로세서는,상기 추론된 정책의 근거집합은, 근거 및 지식 그래프 검색 함수를 통해 추출된 그래프에 기초한 근거 재구성 손실을 통해 생성되는 것을 특징으로 하는 SLM을 위한 정책 생성장치. |
| 14 | 제13항에 있어서,상기 프로세서는,상기 근거 재구성 손실은 수학식(여기서, :근거 재구성 손실, o: 관측, h: 작업 설명, R: 근거집합, : 근거, g: 지식 그래프 검색 함수를 통해 추출된 그래프)인 것을 특징으로 하는 SLM을 위한 정책 생성장치. |
| 15 | 제11항에 있어서,상기 프로세서는,상기 추론정책을 학습하는 경우, 상기 체화된 지식 그래프는 프롬프트된 지식 그래프인 것을 특징으로 하는 SLM을 위한 정책 생성장치. |
| 16 | 제15항에 있어서,상기 프로세서는,상기 프롬프트된 지식 그래프는 동일한 계획을 실행하는 체화된 지식 그래프인 긍정 페어 및 연속적인 계획 단계인 부정 페어를 포함하는 배치 샘플에 기초한 것을 특징으로 하는 SLM을 위한 정책 생성장치. |
| 17 | 제15항에 있어서,상기 프로세서는,상기 프롬프트된 지식 그래프는 대조 학습 손실에 기초한 것을 특징으로하고, 상기 대조 학습 손실은 수학식(여기서, :대조 학습 손실, : 배치 샘플, : 임베딩 공간, d: 임베딩 공간 ∈Z 내에서 각 근거 임베딩 시퀀스의 요소에 해당하는 거리 메트릭의 합, : 마진 파라미터)인 것을 특징으로 하는 SLM을 위한 정책 생성장치. |
| 18 | 제11항에 있어서,상기 프로세서는,상기 계획정책을 학습하는 경우,상기 계획정책은 상기 학습된 추론정책의 근거집합에 기초하여 다음 계획(a)을 예측하여 학습되고, 수학식(여기서, :계획정책, R: 추론정책의 근거집합, : 추론정책, g: 지식 그래프 검색 함수를 통해 추출된 그래프, a: 다음 계획)을 통해 학습되는 것을 특징으로 하는 SLM을 위한 정책 생성장치. |
| 19 | 제11항에 있어서,상기 프로세서는,상기 상기 계획정책 재구성 손실은 수학식(여기서, : 계획정책 재구성 손실, o: 관측, h: 작업 설명, R: 근거집합, :계획정책, a: 다음 계획)인 것을 특징으로 하는 SLM을 위한 정책 생성장치. |
| 20 | 전문 데이터셋을 수신받는 입출력 인터페이스;상기 전문 데이터셋에 기초하여 SLM 정책을 생성하는 프로세서; 및상기 생성된 SLM 정책을 단말로 송신하는 통신부;를 포함하고,상기 프로세서는 상기 전문 데이터셋과 미리 저장된 초기 근거집합에 기초하여 근거 데이터셋을 생성하고, 상기 근거 데이터셋을 자기 검증 함수를 통해 검증하고, 상기 검증된 근거 데이터셋에 기초하여 체화된 지식 그래프를 통해 추론정책을 학습하고, 상기 학습된 추론정책의 근거집합 및 계획정책 재구성 손실에 기초하여 계획정책을 학습하고, 상기 학습된 추론정책 및 계획정책에 기초하여 최종 추론정책 및 계획정책을 포함하는 SLM 정책을 생성하는 것을 특징으로 하는 SLM을 위한 정책을 생성하는 중앙서버. |