| 번호 | 청구항 |
|---|---|
| 4 | 제1항에 있어서,상기 모방정책은 제1모방정책 및 제2모방정책을 포함하고,상기 모방정책의 보상함수는 제1모방정책의 보상함수 및 제2모방정책의 보상함수를 포함하고,상기 타겟정책을 미세조정하는 단계는,상기 제2모방정책의 보상함수와 상기 타겟정책의 보상함수 사이의 거리에 기초하여 상기 타겟정책을 미세조정하는 것을 특징으로 하는파레토 정책 집합 생성방법. |
| 5 | 제1항에 있어서,상기 모방정책은 제1모방정책 및 제2모방정책을 포함하고,상기 모방정책의 보상함수는 제1모방정책의 보상함수 및 제2모방정책의 보상함수를 포함하고,상기 타겟정책을 미세조정하는 단계는,상기 제1모방정책의 보상함수와 상기 제2모방정책의 사이의 거리에 기초하여 상기 타겟정책을 미세조정하는 것을 특징으로 하는파레토 정책 집합 생성방법. |
| 6 | 제1항에 있어서,상기 타겟정책을 미세조정하는 단계는,상기 모방정책의 보상함수와 상기 타겟정책의 보상함수 사이의 거리 및 상기 모방정책의 보상함수 간의 거리에 기초하여 정규화항을 생성하고, 생성된 정규화항을 포함하는 보상함수 정규화식을 최대화하도록 학습하여 상기 타겟정책을 미세조정하는 것을 특징으로 하는파레토 정책 집합 생성방법. |
| 7 | 제1항에 있어서,상기 타겟정책을 설정하는 단계는,상기 미리 결정된 위치는 상기 모방정책 사이에 연장된 미리 결정된 파레토 전선상에 위치하는 것을 특징으로 하는파레토 정책 집합 생성방법. |
| 8 | 제1항에 있어서,상기 미세조정된 타겟정책의 보상함수 간의 거리가 미리 결정된 거리를 초과하는 경우, 상기 미세조정된 타겟정책을 상기 모방정책으로 업데이트하는 단계;를 더 포함하는 파레토 정책 집합 생성방법. |
| 9 | 제1항에 있어서,상기 파레토 정책 집합을 생성하는 단계는,상기 미세조정된 타겟정책의 보상함수 간의 거리가 미리 결정된 거리 이하인 경우, 상기 파레토 정책 집합을 생성하는 것을 특징으로 하는 파레토 정책 집합 생성방법. |
| 10 | 제1항에 있어서,상기 모방정책 및 상기 모방정책의 보상함수를 생성하는 단계 및 상기 타겟정책을 미세조정하는 단계는,역강화학습에 기초하여 수행되는 것을 특징으로 하는파레토 정책 집합 생성방법. |
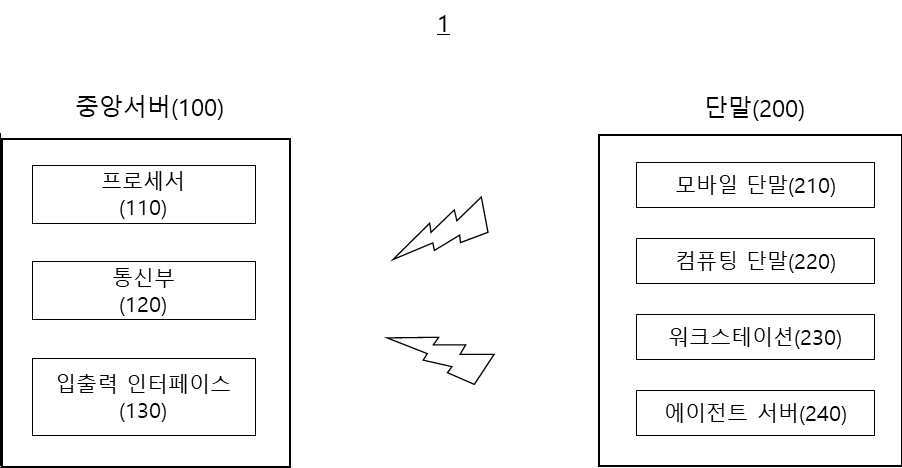
| 11 | 샘플 데이터셋을 수신받는 입출력 인터페이스; 및상기 샘플 데이터셋에 기초하여 파레토 정책 집합을 생성하는 프로세서;를 포함하고,상기 프로세서는 상기 샘플 데이터셋으로부터 모방정책 및 상기 모방정책의 보상함수를 생성하여, 상기 모방정책 인근의 미리 결정된 위치에 타겟정책을 설정하고, 상기 모방정책의 보상함수와 상기 타겟정책의 보상함수 사이의 거리에 기초하여 상기 타겟정책을 미세조정하고, 상기 모방정책 및 상기 미세조정된 타겟정책을 포함하는 파레토 정책 집합을 생성하는 것을 특징으로 하는파레토 정책 집합 생성장치. |
| 12 | 제11항에 있어서,상기 프로세서는,상기 모방정책은 제1모방정책 및 제2모방정책을 포함하고,상기 모방정책의 보상함수는 제1모방정책의 보상함수 및 제2모방정책의 보상함수를 포함하고,상기 타겟정책을 미세조정하는 것은,상기 제1모방정책의 보상함수와 상기 타겟정책의 보상함수 사이의 거리에 기초하여 상기 타겟정책을 미세조정하는 것을 특징으로 하는파레토 정책 집합 생성장치. |
| 13 | 제11항에 있어서,상기 프로세서는,상기 모방정책은 제1모방정책 및 제2모방정책을 포함하고,상기 모방정책의 보상함수는 제1모방정책의 보상함수 및 제2모방정책의 보상함수를 포함하고,상기 타겟정책을 미세조정하는 것은,상기 제2모방정책의 보상함수와 상기 타겟정책의 보상함수 사이의 거리에 기초하여 상기 타겟정책을 미세조정하는 것을 특징으로 하는파레토 정책 집합 생성장치. |
| 14 | 제11항에 있어서,상기 프로세서는,상기 모방정책은 제1모방정책 및 제2모방정책을 포함하고,상기 모방정책의 보상함수는 제1모방정책의 보상함수 및 제2모방정책의 보상함수를 포함하고,상기 타겟정책을 미세조정하는 것은,상기 제1모방정책의 보상함수와 상기 제2모방정책의 사이의 거리에 기초하여 상기 타겟정책을 미세조정하는 것을 특징으로 하는파레토 정책 집합 생성장치. |
| 15 | 제11항에 있어서,상기 프로세서는,상기 모방정책의 보상함수와 상기 타겟정책의 보상함수 사이의 거리 및 상기 모방정책의 보상함수 간의 거리에 기초하여 정규화항을 생성하고, 생성된 정규화항을 포함하는 보상함수 정규화식을 최대화하도록 학습하여 상기 타겟정책을 미세조정하는 것을 특징으로 하는파레토 정책 집합 생성장치. |
| 16 | 제11항에 있어서,상기 프로세서는,상기 미리 결정된 위치는 상기 모방정책 사이에 연장된 미리 결정된 파레토 전선상에 위치하는 것을 특징으로 하는파레토 정책 집합 생성장치. |
| 17 | 제11항에 있어서,상기 프로세서는,상기 미세조정된 타겟정책의 보상함수 간의 거리가 미리 결정된 거리를 초과하는 경우, 상기 미세조정된 타겟정책을 상기 모방정책으로 업데이트하는 것을 특징으로 하는파레토 정책 집합 생성장치. |
| 18 | 제11항에 있어서,상기 프로세서는,파레토 정책 집합을 생성 시 상기 미세조정된 타겟정책의 보상함수 간의 거리가 미리 결정된 거리 이하인 경우, 상기 파레토 정책 집합을 생성하는 것을 특징으로 하는파레토 정책 집합 생성장치. |
| 19 | 제11항에 있어서,상기 프로세서는,상기 모방정책 및 상기 모방정책의 보상함수를 생성하고 상기 타겟정책을 미세조정하는 경우, 역강화학습에 기초하여 수행되는 것을 특징으로 하는파레토 정책 집합 생성장치. |
| 20 | 샘플 데이터셋을 수신받는 입출력 인터페이스; 및상기 샘플 데이터셋에 기초하여 파레토 정책 집합을 생성하는 프로세서;를 포함하고,상기 프로세서는 상기 샘플 데이터셋으로부터 모방정책 및 상기 모방정책의 보상함수를 생성하여, 상기 모방정책 인근의 미리 결정된 위치에 타겟정책을 설정하고, 상기 모방정책의 보상함수와 상기 타겟정책의 보상함수 사이의 거리에 기초하여 상기 타겟정책을 미세조정하고, 상기 모방정책 및 상기 미세조정된 타겟정책을 포함하는 파레토 정책 집합을 생성하는 것을 특징으로 하는파레토 정책 집합을 생성하는 중앙서버. |
| 1 | 샘플 데이터셋을 수신받는 단계;상기 샘플 데이터셋으로부터 모방정책 및 상기 모방정책의 보상함수를 생성하는 단계;상기 모방정책 인근의 미리 결정된 위치에 타겟정책을 설정하는 단계;상기 모방정책의 보상함수와 상기 타겟정책의 보상함수 사이의 거리에 기초하여 상기 타겟정책을 미세조정하는 단계; 및상기 모방정책 및 상기 미세조정된 타겟정책을 포함하는 파레토 정책 집합을 생성하는 단계;을 포함하는 파레토 정책 집합 생성방법. |
| 2 | 제1항에 있어서,상기 모방정책 및 상기 모방정책의 보상함수를 생성하는 단계는,상기 2개의 샘플 데이터셋 각각으로부터 상기 모방정책 2개 및 상기 모방정책의 보상함수를 2개를 생성하고,상기 타겟정책을 설정하는 단계는,상기 타갯정책 2개를 생성하는 것을 특징으로 하는파레토 정책 집합 생성방법. |
| 3 | 제1항에 있어서,상기 모방정책은 제1모방정책 및 제2모방정책을 포함하고,상기 모방정책의 보상함수는 제1모방정책의 보상함수 및 제2모방정책의 보상함수를 포함하고,상기 타겟정책을 미세조정하는 단계는,상기 제1모방정책의 보상함수와 상기 타겟정책의 보상함수 사이의 거리에 기초하여 상기 타겟정책을 미세조정하는 것을 특징으로 하는파레토 정책 집합 생성방법. |