| 번호 | 청구항 |
|---|---|
| 2 | 인공지능 모델의 학습 방법에 있어서,상기 헥사값을 각각 추출하는 단계에서,1 바이트(byte)씩 이동(shift)하면서 상기 제1 파일 및 상기 제2 파일의 파일 구조 전체에 대한 복수의 헥사값을 각각 추출하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
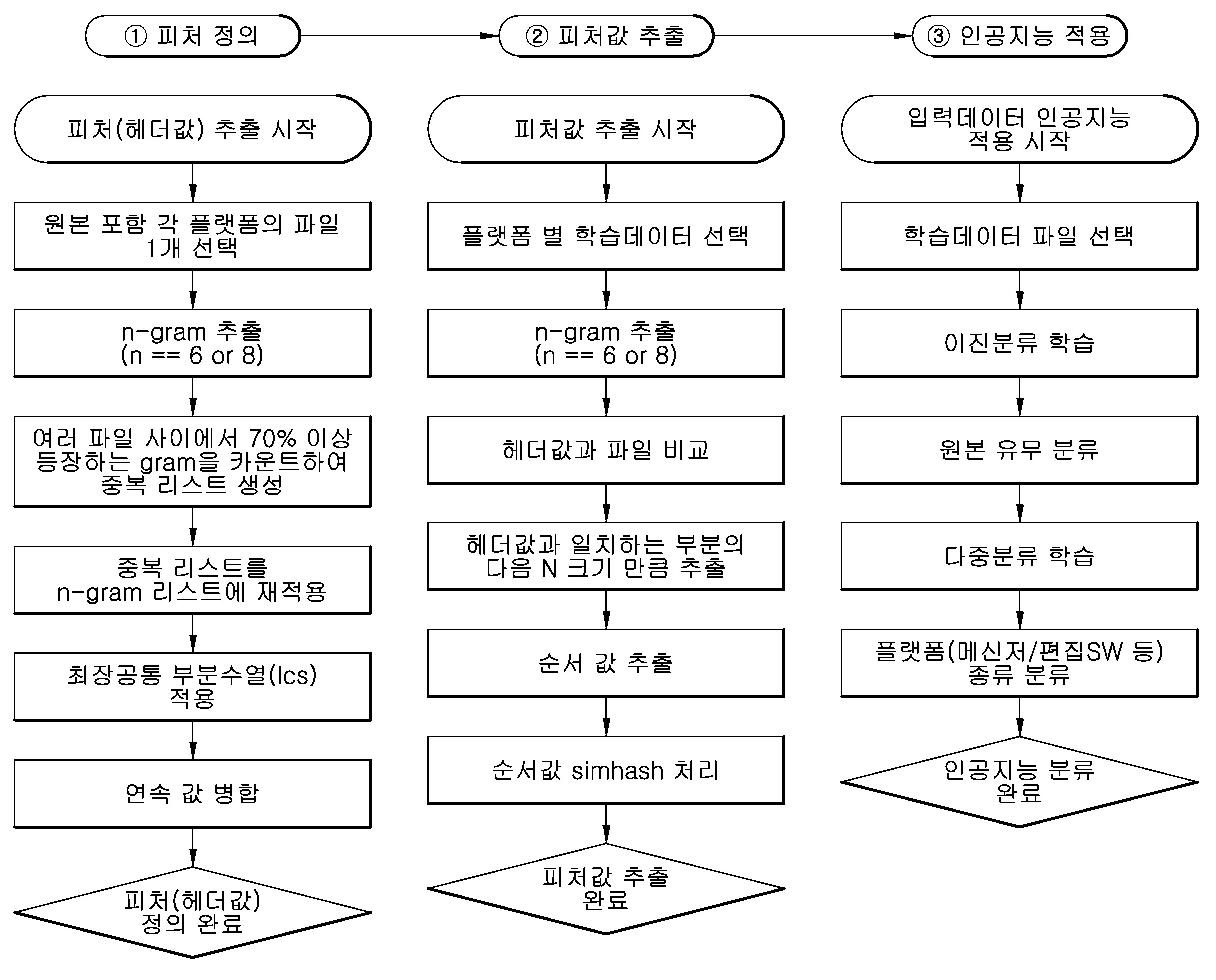
| 1 | 학습 데이터 생성 장치에 의해 수행되는 인공지능 모델을 위한 학습 데이터 생성 방법에 있어서,제1 파일 및 상기 제1 파일을 소프트웨어를 이용하여 편집한 제2 파일의 파일 구조로부터 기 결정된 길이의 헥사(hexadecimal)값을 각각 추출하는 단계;상기 추출한 상기 제1 파일의 헥사값 및 상기 제2 파일의 헥사값을 기초로 피처(feature)를 결정하는 단계; 및상기 피처를 기초로 상기 소프트웨어에 의한 파일 편집에 관한 정보를 식별하는 인공지능 모델을 위한 학습 데이터를 생성하는 단계를 포함하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 3 | 제1항에 있어서,상기 제1 파일을 복수의 소프트웨어를 이용하여 각각 편집한 제1 복수의 수정 파일을 입력받는 단계; 및각 수정 파일의 파일 구조로부터 상기 기 결정된 길이의 헥사값을 각각 추출하는 단계를 더 포함하고,상기 피처를 결정하는 단계는,상기 제1 파일의 헥사값 및 상기 제2 파일의 헥사값을 비교하여 후보 피처를 선정하는 단계; 및상기 후보 피처 및 상기 각 수정 파일의 헥사값을 비교하여 최종 피처를 선택하는 단계를 포함하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 4 | 제3항에 있어서,상기 후보 피처를 선정하는 단계에서,상기 제1 파일의 헥사값 및 상기 제2 파일의 헥사값을 비교하여 동일하면 상기 제2 파일의 헥사값을 후보 피처로서 선정하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 5 | 제3항에 있어서,상기 후보 피처를 선정하는 단계는,상기 후보 피처 및 각 수정 파일의 헥사값을 비교하여 동일하면 상기 후보 피처에 대한 카운트 수를 1 증가시키는 단계; 및상기 후보 피처 및 상기 후보 피처에 대한 카운트 수를 기초로 상기 피처를 결정하는 단계를 포함하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 6 | 제5항에 있어서,상기 피처를 결정하는 단계에서,상기 후보 피처에 대한 상기 카운트 수가 상기 제1 복수의 수정 파일의 개수에 대한 기 설정된 비율 이상인 경우, 상기 후보 피처를 상기 피처로서 결정하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 7 | 제5항에 있어서,상기 피처를 결정하는 단계는,상기 제1 복수의 수정 파일에 대해, 상기 피처 및 상기 각 수정 파일의 헥사값을 비교하여 상기 피처에 포함된 헥사값과 동일한 헥사값을 제외한 나머지 헥사값을 제거하는 단계를 포함하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 8 | 제7항에 있어서,상기 피처를 결정하는 단계는,상기 제거하는 단계 이후, 상기 제1 복수의 수정 파일에 대해 최장 공통 부분 수열(LCS, longest common subsequence)을 이용하여 추출한 LCS 공통 구조를 상기 피처로서 결정하는 단계를 포함하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 9 | 제3항에 있어서,상기 입력받는 단계는,음성 파일, 이미지 파일 및 동영상 파일을 포함하는 제2 복수의 파일 및 상기 제2 복수의 파일을 복수의 소프트웨어를 이용하여 각각 편집한 제2 복수의 수정 파일을 입력받는 단계를 포함하고,상기 학습 데이터를 생성하는 단계에서,소프트웨어에 의한 상기 음성 파일, 상기 이미지 파일 및 상기 동영상 파일을 포함하는 파일의 편집에 관한 정보를 식별하는 인공지능 모델을 위한 학습 데이터를 생성하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 10 | 제1항에 있어서,제3 파일을 입력받고, 상기 제3 파일의 파일 구조로부터 상기 기 결정된 길이의 헥사값을 추출하는 단계;상기 제3 파일의 헥사값에서 상기 피처를 검색하는 단계; 및상기 제3 파일 내 검색된 상기 피처를 기초로, 상기 피처에 대응하는 피처값을 추출하는 단계를 더 포함하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 11 | 제10항에 있어서,상기 피처값을 추출하는 단계에서,상기 피처에 대응하는 헥사값의 다음 헥사값부터 기 설정된 길이까지의 헥사값을 상기 피처값으로서 추출하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 12 | 제11항에 있어서,상기 피처값의 길이는 상기 피처의 길이의 2배인,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 13 | 제10항에 있어서,상기 피처 및 상기 피처값은 복수이고,상기 피처값을 추출하는 단계는,각 피처에 순서 번호를 할당하는 단계; 및상기 피처값에 대해, 상기 각 피처에 대한 순서 번호에 대응되도록 순서 번호를 할당하는 단계를 포함하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 14 | 제1항에 있어서,상기 편집에 관한 정보는 상기 소프트웨어에 의한 파일의 편집 여부 및 전송 여부 중 적어도 하나를 포함하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 15 | 제1항에 있어서,상기 학습 데이터는 상기 소프트웨어에 대한 정보 및 편집 여부에 대한 정보를 포함하는 레이블(label) 데이터를 포함하는,인공지능 모델을 위한 학습 데이터 생성 방법. |
| 16 | 컴퓨팅 장치에 의해 수행되는 인공지능 모델의 학습 방법에 있어서,제1 파일 및 상기 제1 파일을 소프트웨어를 이용하여 편집한 제2 파일의 파일 구조로부터 기 결정된 길이의 헥사(hexadecimal)값을 각각 추출하는 단계;상기 추출한 상기 제1 파일의 헥사값 및 상기 제2 파일의 헥사값을 기초로 피처(feature)를 결정하는 단계;상기 피처를 기초로 상기 소프트웨어에 의한 파일 편집에 관한 정보를 식별하는 인공지능 모델을 위한 학습 데이터를 생성하는 단계; 및상기 생성된 학습 데이터를 기초로 상기 인공지능 모델을 학습시키는 단계를 포함하는,인공지능 모델의 학습 방법. |
| 17 | 인공지능 모델에 의해 수행되는 파일 편집 여부 식별 방법에 있어서,소프트웨어에 의한 파일 편집에 관한 정보를 식별하는 인공지능 모델에 파일을 입력하는 단계; 및상기 인공지능 모델을 이용하여 상기 소프트웨어에 의한 파일의 편집 여부 및 전송 여부 중 적어도 하나를 식별하는 단계를 포함하는,파일 편집 여부 식별 방법. |
| 18 | 제17항에 있어서,상기 인공지능 모델은,기 결정된 길이의 헥사값을 기초로 결정된 피처를 포함하는 학습 데이터를 생성하는 단계; 및소프트웨어에 의한 파일 편집에 관한 정보를 식별하도록 인공지능 모델을 학습시키는 단계를 통해 기 학습된 것인,파일 편집 여부 식별 방법. |
| 19 | 제18항에 있어서,상기 학습 데이터를 생성하는 단계는,제1 파일 및 상기 제1 파일을 소프트웨어를 이용하여 편집한 제2 파일의 파일 구조로부터 기 결정된 길이의 헥사(hexadecimal)값을 각각 추출하는 단계;상기 추출한 상기 제1 파일의 헥사값 및 상기 제2 파일의 헥사값을 기초로 피처(feature)를 결정하는 단계; 및상기 피처를 기초로 상기 인공지능 모델을 위한 학습 데이터를 생성하는 단계를 포함하는,파일 편집 여부 식별 방법. |
| 20 | 제17항에 있어서,상기 인공지능 모델을 이용하여 파일 편집 또는 전송을 수행한 소프트웨어를 식별하는 단계를 더 포함하는,파일 편집 여부 식별 방법. |
| 21 | 컴퓨터 실행 가능한 명령어를 저장할 수 있는 메모리; 및상기 명령어를 실행함으로써,제1 파일 및 상기 제1 파일을 소프트웨어를 이용하여 편집한 제2 파일의 파일 구조로부터 기 결정된 길이의 헥사(hexadecimal)값을 각각 추출하는 단계;상기 추출한 상기 제1 파일의 헥사값 및 상기 제2 파일의 헥사값을 기초로 피처(feature)를 결정하는 단계; 및상기 피처를 기초로 상기 소프트웨어에 의한 파일 편집에 관한 정보를 식별하는 인공지능 모델을 위한 학습 데이터를 생성하는 단계를 포함하는 방법을 수행하는 프로세서를 포함하는,인공지능 모델을 위한 학습 데이터 생성 장치. |
| 22 | 컴퓨터 실행 가능한 명령어를 저장하고 있는 컴퓨터 판독 가능 기록매체로서, 상기 컴퓨터 실행 가능한 명령어는, 프로세서에 의해 실행되면,제1 파일 및 상기 제1 파일을 소프트웨어를 이용하여 편집한 제2 파일의 파일 구조로부터 기 결정된 길이의 헥사(hexadecimal)값을 각각 추출하는 단계;상기 추출한 상기 제1 파일의 헥사값 및 상기 제2 파일의 헥사값을 기초로 피처(feature)를 결정하는 단계; 및상기 피처를 기초로 상기 소프트웨어에 의한 파일 편집에 관한 정보를 식별하는 인공지능 모델을 위한 학습 데이터를 생성하는 단계를 포함하는 방법을 상기 프로세서가 수행하도록 하는,컴퓨터 판독 가능한 기록매체. |
| 23 | 컴퓨터 판독 가능한 기록매체에 저장되어 있는 컴퓨터 프로그램으로서,상기 컴퓨터 프로그램은, 프로세서에 의해 실행되면,제1 파일 및 상기 제1 파일을 소프트웨어를 이용하여 편집한 제2 파일의 파일 구조로부터 기 결정된 길이의 헥사(hexadecimal)값을 각각 추출하는 단계;상기 추출한 상기 제1 파일의 헥사값 및 상기 제2 파일의 헥사값을 기초로 피처(feature)를 결정하는 단계; 및상기 피처를 기초로 상기 소프트웨어에 의한 파일 편집에 관한 정보를 식별하는 인공지능 모델을 위한 학습 데이터를 생성하는 단계를 포함하는 방법을 상기 프로세서가 수행하도록 하기 위한 명령어를 포함하는,컴퓨터 판독 가능한 기록매체에 저장되어 있는 컴퓨터 프로그램. |