| 번호 | 청구항 |
|---|---|
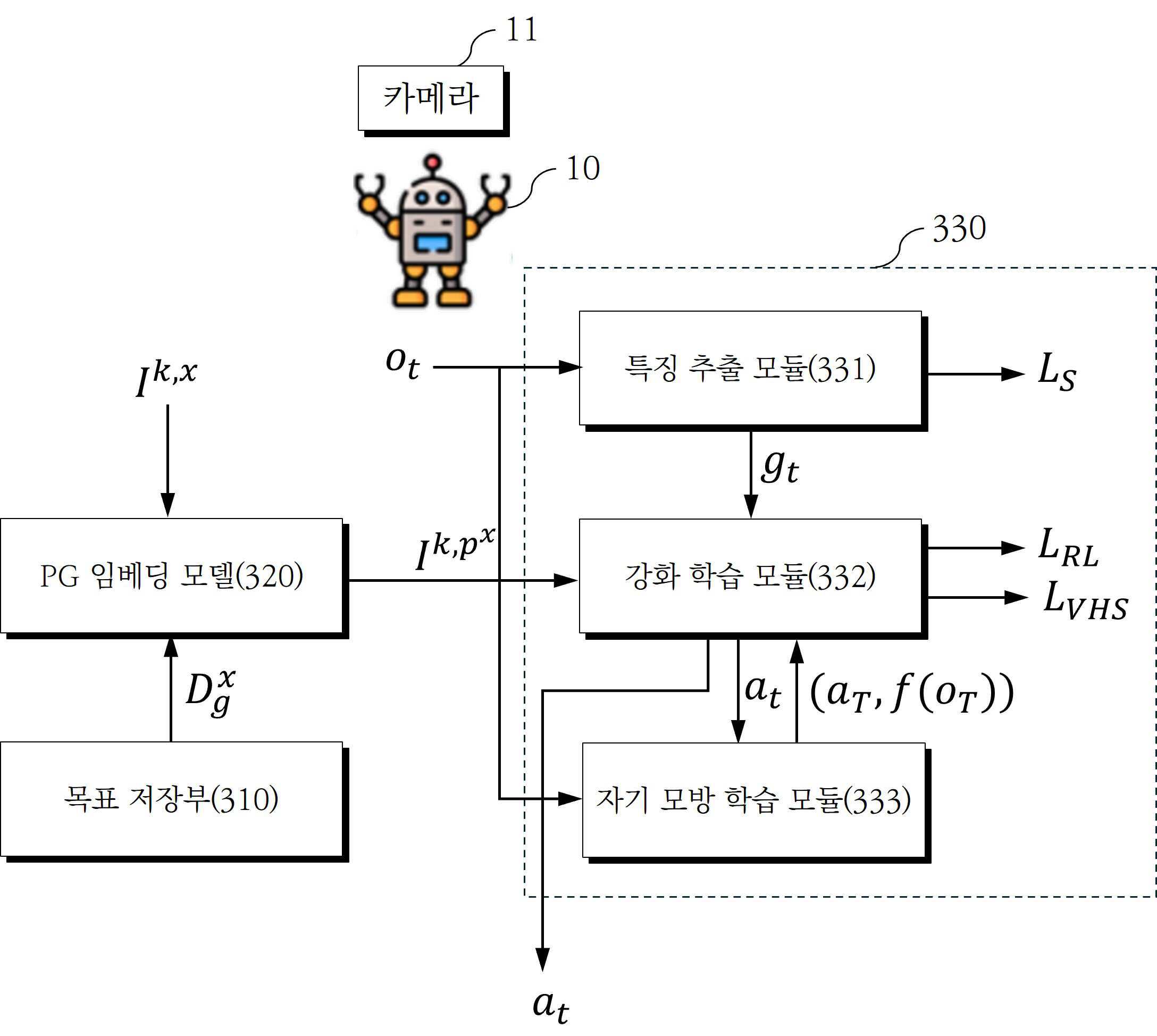
| 6 | 제 4 항에 있어서,상기 학습 모델은,상기 시각적 입력으로부터 상기 상태 특징 정보에 관한 특징을 추출하는 특징 추출 모듈;상기 상태 특징 정보에 관한 특징 및 상기 제 2 작업 지시에 기반하여, 정책에 따른 상기 행동 정보를 출력하는 강화 학습 모듈; 및상기 목표 작업이 실패로 평가되는 경우, 최종 관찰 상태의 상기 시각적 입력 및 상기 행동 정보를 기초로 새로운 제 2 목표 객체 및 상기 상호 작용을 재지정하는 자기 모방 학습 모듈을 포함하는, 방법. |
| 7 | 제 1 항 내지 제 6 항 중 어느 한 항에 따른 방법을 실행하기 위하여 기록 매체에 저장된 컴퓨터 프로그램. |
| 1 | 시각적 목표 재지정을 통한 강화 학습 방법으로서, 제 1 목표 객체 및 상호 작용에 대한 정보를 포함하는 목표 작업에 대한 제 1 작업 지시(instruction)와 관찰 상태에 대한 시각적 입력을 획득하는 단계;PG(Prototype Goal) 임베딩 모듈을 통해 목표 저장부에 저장된 상기 제 1 목표 객체의 시각적 표현을 포함하는 복수의 목표 이미지를 소정의 임베딩 공간(embedding space)에 임베딩하여, 상기 제 1 목표 객체의 제 1 프로토 타입 특징을 산출하는 단계;제 1 목표 객체에 대한 정보를 상기 제 1 프로토 타입 특징으로 대체함으로써, 상기 제 1 작업 지시를 제 2 작업 지시로 변환하고, 상기 제 2 작업 지시를 강화 학습 기반의 학습 모델에 전달하는 단계;상기 시각적 입력으로부터 상태 특징 정보를 추출하는 단계;상기 상태 특징 정보 및 상기 제 2 작업 지시에 기반하여 상기 학습 모델이 행동 정보를 출력하는 단계; 및상기 행동 정보를 기초로 상기 목표 작업의 성공 여부를 평가하고, 상기 학습 모델에 보상을 부여하는 단계를 포함하는, 방법. |
| 2 | 제 1 항에 있어서,상기 제 1 프로토 타입 특징은, 상기 임베딩 공간에서 복수의 상기 목표 이미지의 평균 특징인, 방법. |
| 3 | 제 1 항에 있어서,상기 목표 작업이 성공으로 평가되는 경우, 상기 시각적 입력을 상기 제 1 목표 객체에 대한 상기 목표 이미지로 라벨링하여 상기 목표 저장부에 저장하는 단계를 더 포함하는, 방법. |
| 4 | 제 1 항에 있어서,상기 목표 작업이 실패로 평가되는 경우, 최종 관찰 상태의 상기 시각적 입력 및 상기 행동 정보를 기초로 새로운 제 2 목표 객체 및 상기 상호 작용을 재지정함으로써, 자기 모방 학습을 수행하는 단계를 더 포함하는, 방법. |
| 5 | 제 4 항에 있어서,상기 자기 모방 학습을 수행하는 단계는,최종 관찰 상태에 대한 상기 시각적 입력을 상기 임베딩 공간에 임베딩하여, 최종 상태의 상기 시각적 입력에 대응하는 제 2 프로토 타입 특성을 생성하는 단계;상기 제 2 프로토 타입 특성 및 상기 행동 정보를 기초로 상기 제 2 목표 객체 및 상기 상호 작용을 재지정하는 단계; 및재지정된 상기 제 2 목표 객체 및 상기 상호 작용에 기초하여 상기 학습 모델에 대한 자기 모방 학습을 수행하는 단계를 포함하는, 방법. |
| 8 | 시각적 목표 재지정을 통한 강화 학습을 수행하기 위한 컴퓨터 장치로서,적어도 하나의 프로세서; 및상기 프로세서에 의해 실행 가능한 프로그램을 저장하는 메모리를 포함하고,상기 프로세서는, 상기 프로그램을 실행함으로써, 제 1 목표 객체 및 상호 작용에 대한 정보를 포함하는 목표 작업에 대한 제 1 작업 지시(instruction)와 관찰 상태에 대한 시각적 입력을 획득하고, PG(Prototype Goal) 임베딩 모듈을 통해 목표 저장부에 저장된 상기 제 1 목표 객체의 시각적 표현을 포함하는 복수의 목표 이미지를 소정의 임베딩 공간(embedding space)에 임베딩하여, 상기 제 1 목표 객체의 제 1 프로토 타입 특징을 산출하며, 제 1 목표 객체에 대한 정보를 상기 제 1 프로토 타입 특징으로 대체함으로써, 상기 제 1 작업 지시를 제 2 작업 지시로 변환하고, 상기 제 2 작업 지시를 강화 학습 기반의 학습 모델에 전달하고, 상기 시각적 입력으로부터 상태 특징 정보를 추출하며, 상기 학습 모델을 통해 상기 상태 특징 정보 및 상기 제 2 작업 지시에 기반하여 행동 정보를 출력하고, 상기 행동 정보를 기초로 상기 목표 작업의 성공 여부를 평가하고, 상기 학습 모델에 보상을 부여하는, 장치. |