| 번호 | 청구항 |
|---|---|
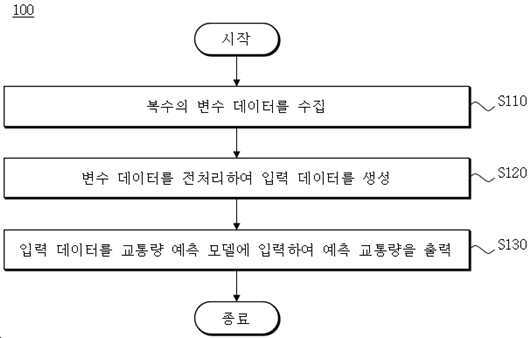
| 1 | 교통량 예측 방법으로서,도로 상의 복수의 위치에 관한 시계열적 교통 정보 및 비-시계열적 교통 정보 중 적어도 하나를 배포하는 적어도 하나의 오픈 데이터베이스로부터, 교통량 데이터, 교통 속도 데이터 및 교통 링크 정보 데이터를 포함하는 복수의 변수 데이터를 수집하는 단계;상기 변수 데이터를 전처리하여 입력 데이터를 생성하는 단계; 및상기 입력 데이터를 사전 학습된 교통량 예측 모델에 입력하여 도로 상의 복수의 지점에 대한 예측 교통량을 출력하는 단계;를 포함하고,상기 입력 데이터를 생성하는 단계에서, 상기 교통량 데이터, 교통 속도 데이터 및 교통 링크 정보 데이터는, 각각의 상기 데이터에 포함된 위치 정보 및 시점 정보를 기준으로 서로 병합되고,상기 교통량 데이터는 제 1 위치 세트 및 제 1 시계열 세트에 관한 데이터이고, 상기 교통 속도 데이터는 제 2 위치 세트 및 제 2 시계열 세트에 관한 데이터이고, 상기 교통 링크 정보 데이터는 제 3 위치 세트에 관한 비-시계열적 데이터이고,상기 제 1 시계열 세트 및 제 2 시계열 세트의 시간 간격은 서로 동일하거나 상이하고,상기 제 1 시계열 세트 및 제 2 시계열 세트의 시간 간격이 상이할 경우, 상기 입력 데이터를 생성하는 단계에서, 상기 제 1 시계열 세트 및 제 2 시계열 세트 중 시간 간격이 작은 시계열 세트를 기준으로 상기 변수 데이터가 병합되는, 방법. |
| 2 | 삭제 |
| 3 | 제 1 항에 있어서,상기 입력 데이터를 생성하는 단계에서, 상기 제 1 위치 세트, 제 2 위치 세트 및 제 3 위치 세트 중 공간 간격이 가장 작은 위치 세트를 기준으로 상기 변수 데이터가 병합되는, 방법. |
| 4 | 제 3 항에 있어서,상기 제 1 위치 세트 및 상기 제 2 위치 세트의 공간 간격에 비해 상기 제 3 위치 세트의 공간 간격이 작고,상기 제 3 위치 세트를 기준으로 상기 변수 데이터가 병합되는, 방법. |
| 5 | 제 4 항에 있어서,상기 제 1 위치 세트 중 적어도 하나의 위치에 관한 상기 교통량 데이터는, 상기 제 1 위치 세트의 상기 위치와 가장 가까운 상기 제 3 위치 세트의 위치에 관한 상기 교통 링크 정보 데이터와 병합되고,상기 제 2 위치 세트 중 적어도 하나의 위치에 관한 상기 교통 속도 데이터는, 상기 제 2 위치 세트의 상기 위치와 가장 가까운 상기 제 3 위치 세트의 위치에 관한 상기 교통 링크 정보 데이터와 병합되는, 방법. |
| 6 | 제 1 항에 있어서,상기 입력 데이터를 생성하는 단계에서, 상기 제 1 시계열 세트의 시점 정보 중 적어도 하나 및 제 2 시계열 세트의 시점 정보 중 적어도 하나가 서로 일치하도록, 상기 제 1 시계열 세트 또는 제 2 시계열 세트의 값이 보정되는, 방법. |
| 7 | 삭제 |
| 8 | 제 1 항에 있어서,상기 입력 데이터를 생성하는 단계에서, 상기 병합된 상기 교통량 데이터, 교통 속도 데이터 및 교통 링크 정보 데이터에 대하여, 복수의 데이터 윈도우가 생성되고,상기 데이터 윈도우는 소정의 시간 간격 및 시점 개수를 갖는 데이터의 집합인, 방법. |
| 9 | 제 1 항에 있어서,상기 교통 링크 정보 데이터는, 도로 상의 복수의 위치 각각에 관한 차선 수, 최대 허용 속도, 도로 등급, 도로 유형 및 연결로 여부 중 적어도 하나에 관한 정보를 포함하는, 방법. |
| 10 | 제 9 항에 있어서,상기 도로 등급은, 고속 국도, 도시 고속 국도, 일반 국도, 특별 광역시도, 국가 지원 지방도 및 지방도의 항목을 포함하고,상기 도로 유형은, 일반 국도, 고가 차도, 교량 및 터널의 항목을 포함하고,상기 연결로 여부는, 연결로 없음 및 도시 고속 국도와 연결됨의 항목을 포함하는, 방법. |
| 11 | 제 1 항에 있어서,상기 교통량 예측 모델은 랜덤 포레스트(Random Forest) 모델인, 방법. |
| 12 | 교통량 예측 모델의 학습 방법으로서,도로 상의 복수의 위치에 관한 시계열적 교통 정보 및 비-시계열적 교통 정보 중 적어도 하나를 배포하는 적어도 하나의 오픈 데이터베이스로부터, 교통량 데이터, 교통 속도 데이터 및 교통 링크 정보 데이터를 포함하는 복수의 변수 데이터를 수집하는 단계;상기 변수 데이터를 전처리하여 입력 데이터를 생성하는 단계; 및상기 입력 데이터를 교통량 예측 모델에 입력하여 학습시키는 단계;를 포함하고,상기 입력 데이터를 생성하는 단계에서, 상기 교통량 데이터, 교통 속도 데이터 및 교통 링크 정보 데이터는, 각각의 상기 데이터에 포함된 위치 정보 및 시점 정보를 기준으로 서로 병합되고,상기 교통량 데이터는 제 1 위치 세트 및 제 1 시계열 세트에 관한 데이터이고, 상기 교통 속도 데이터는 제 2 위치 세트 및 제 2 시계열 세트에 관한 데이터이고, 상기 교통 링크 정보 데이터는 제 3 위치 세트에 관한 비-시계열적 데이터이고,상기 제 1 시계열 세트 및 제 2 시계열 세트의 시간 간격은 서로 동일하거나 상이하고,상기 제 1 시계열 세트 및 제 2 시계열 세트의 시간 간격이 상이할 경우, 상기 입력 데이터를 생성하는 단계에서, 상기 제 1 시계열 세트 및 제 2 시계열 세트 중 시간 간격이 작은 시계열 세트를 기준으로 상기 변수 데이터가 병합되는, 방법. |
| 13 | 온실가스 배출량 예측 방법으로서,도로 상의 복수의 위치에 관한 시계열적 교통 정보 및 비-시계열적 교통 정보 중 적어도 하나를 배포하는 적어도 하나의 오픈 데이터베이스로부터, 교통량 데이터, 교통 속도 데이터 및 교통 링크 정보 데이터를 포함하는 복수의 변수 데이터를 수집하는 단계;상기 변수 데이터를 전처리하여 입력 데이터를 생성하는 단계;상기 입력 데이터를 사전 학습된 교통량 예측 모델에 입력하여 도로 상의 복수의 지점에 대한 예측 교통량을 출력하는 단계; 및상기 예측 교통량을 사전 학습된 온실가스 배출량 예측 모델에 입력하여 예측 온실가스 배출량을 출력하는 단계;를 포함하고,상기 입력 데이터를 생성하는 단계에서, 상기 교통량 데이터, 교통 속도 데이터 및 교통 링크 정보 데이터는, 각각의 상기 데이터에 포함된 위치 정보 및 시점 정보를 기준으로 서로 병합되고,상기 교통량 데이터는 제 1 위치 세트 및 제 1 시계열 세트에 관한 데이터이고, 상기 교통 속도 데이터는 제 2 위치 세트 및 제 2 시계열 세트에 관한 데이터이고, 상기 교통 링크 정보 데이터는 제 3 위치 세트에 관한 비-시계열적 데이터이고,상기 제 1 시계열 세트 및 제 2 시계열 세트의 시간 간격은 서로 동일하거나 상이하고,상기 제 1 시계열 세트 및 제 2 시계열 세트의 시간 간격이 상이할 경우, 상기 입력 데이터를 생성하는 단계에서, 상기 제 1 시계열 세트 및 제 2 시계열 세트 중 시간 간격이 작은 시계열 세트를 기준으로 상기 변수 데이터가 병합되는, 방법. |
| 14 | 제 1 항, 제 3 항 내지 제 6 항 및 제 8 항 내지 제 13 항 중 어느 한 항에 따른 방법을 실행하기 위하여 기록 매체에 저장된 컴퓨터 프로그램. |
| 15 | 교통량 예측을 위한 컴퓨팅 장치로서,적어도 하나의 프로세서; 및상기 프로세서에 의해 실행 가능한 프로그램을 저장하는 메모리를 포함하고,상기 프로세서는, 도로 상의 복수의 위치에 관한 시계열적 교통 정보 및 비-시계열적 교통 정보 중 적어도 하나를 배포하는 적어도 하나의 오픈 데이터베이스로부터, 교통량 데이터, 교통 속도 데이터 및 교통 링크 정보 데이터를 포함하는 복수의 변수 데이터를 수집하고, 상기 변수 데이터를 전처리하여 입력 데이터를 생성하며, 상기 입력 데이터를 사전 학습된 예측 모델에 입력하여 도로 상의 복수의 지점에 대한 예측 교통량을 출력하고, 상기 입력 데이터를 생성할 때, 상기 교통량 데이터, 교통 속도 데이터 및 교통 링크 정보 데이터를, 각각의 상기 데이터에 포함된 위치 정보 및 시점 정보를 기준으로 서로 병합하고,상기 교통량 데이터는 제 1 위치 세트 및 제 1 시계열 세트에 관한 데이터이고, 상기 교통 속도 데이터는 제 2 위치 세트 및 제 2 시계열 세트에 관한 데이터이고, 상기 교통 링크 정보 데이터는 제 3 위치 세트에 관한 비-시계열적 데이터이고,상기 제 1 시계열 세트 및 제 2 시계열 세트의 시간 간격은 서로 동일하거나 상이하고,상기 제 1 시계열 세트 및 제 2 시계열 세트의 시간 간격이 상이할 경우, 상기 입력 데이터를 생성할 때, 상기 제 1 시계열 세트 및 제 2 시계열 세트 중 시간 간격이 작은 시계열 세트를 기준으로 상기 변수 데이터가 병합되는, 장치. |