| 번호 | 청구항 |
|---|---|
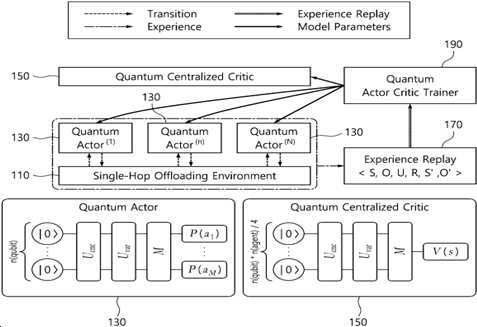
| 1 | 적어도 하나 이상의 관측 값과 상태 값을 출력하는 싱글-홉 오프로딩 환경(Single-Hop Offloading Environment) 모듈;상기 싱글-홉 오프로딩 환경 모듈로부터 상기 관측 값을 전달받고, 상기 관측 값을 큐비트로 변환하여 학습에 사용되는 행동 값을 출력하는 복수의 퀀텀 액터(Quantum Actor);상기 싱글-홉 오프로딩 환경 모듈로부터 상기 상태 값을 전달받고, 상기 상태 값을 큐비트로 변환하여 상기 행동 값에 근사하는 반환 값을 출력하는 퀀텀 크리틱(Quantum Critic);을 포함하되,상기 싱글-홉 오프로딩 환경 모듈은,상기 복수의 퀀텀 액터로부터 상기 행동 값을 전달받아 학습 데이터셋을 생성하는, 양자 다중 에이전트 강화학습 시스템. |
| 2 | 제1항에 있어서,상기 싱글-홉 오프로딩 환경 모듈로부터 상기 학습 데이터셋을 전달받아 저장하는 저장 모듈; 및상기 학습 데이터셋을 기초로 상기 복수의 퀀텀 액터 및 상기 퀀텀 크리틱을 학습시키는 학습 모듈을 더 포함하는 것을 특징으로 하는, 양자 다중 에이전트 강화학습 시스템. |
| 3 | 제1항에 있어서,상기 싱글-홉 오프로딩 환경 모듈은,현재 상태에 기초하여 상기 상태 값을 생성하고, 상기 상태 값 중 미리 설정된 범위 내의 값을 추출하여 상기 관측 값을 생성하고, 상기 복수의 퀀텀 액터로부터 상기 행동 값을 전달받으면, 상기 행동 값에 기초하여 다음 상태 값을 생성하고, 상기 다음 상태 값 중 미리 설정된 범위 내의 값을 추출하여 다음 상태 관측 값을 생성함으로써, 상기 학습 데이터셋을 생성하는 것을 특징으로 하는, 양자 다중 에이전트 강화학습 시스템. |
| 4 | 제3항에 있어서,상기 싱글-홉 오프로딩 환경 모듈은,상기 복수의 퀀텀 액터로부터 전달받는 상기 행동 값을 보상하는 보상 값을 생성하여 상기 학습 데이터셋에 더 포함하는 것을 특징으로 하는, 양자 다중 에이전트 강화학습 시스템. |
| 5 | 제1항에 있어서,상기 복수의 퀀텀 액터 및 상기 퀀텀 크리틱은,상기 싱글-홉 오프로딩 환경 모듈로부터 전달받은 값을 부호화하여 각 축에 따른 각도를 산출하고, 기본 큐비트 상태인 기본 레이어에 각 축에 따른 각도를 적용하여 상기 값을 큐비트(Qubit) 상태로 변환하는 상태 인코딩부;상기 각 축에 따른 각도가 적용된 기본 레이어를 중첩하여 큐비트를 생성하는 양자 회로부; 및상기 큐비트를 Z축 평면 상에서 반복적으로 사영하여 상기 큐비트에 대한 값을 측정하는 측정부;를 포함하는 것을 특징으로 하는, 양자 다중 에이전트 강화학습 시스템. |
| 6 | 제5항에 있어서,상기 상태 인코딩부는,Rx 게이트, Ry 게이트 및 Rz 게이트로 마련되는 기본 레이어에 각 축에 따른 각도를 적용하고,상기 양자 회로부는,CX(Controlled X) 게이트를 통해 상기 Rx 게이트, 상기 Ry 게이트 및 Rz 게이트를 중첩함으로써 각 축에 따라 회전된 상기 큐비트를 생성하는 것을 특징으로 하는, 양자 다중 에이전트 강화학습 시스템. |
| 7 | 양자 다중 에이전트 강화학습 시스템에서 수행되는 양자 다중 에이전트 강화학습 방법에 있어서,싱글-홉 오프로딩 환경(Single-Hop Offloading Environment) 모듈이 적어도 하나 이상의 관측 값과 상태 값을 출력하는 단계;복수의 퀀텀 액터(Quantum Actor)가 상기 싱글-홉 오프로딩 환경 모듈로부터 상기 관측 값을 전달받고, 상기 관측 값을 큐비트로 변환하여 학습에 사용되는 행동 값을 출력하는 단계;퀀텀 크리틱(Quantum Critic)이 상기 싱글-홉 오프로딩 환경 모듈로부터 상기 상태 값을 전달받고, 상기 상태 값을 큐비트로 변환하여 상기 행동 값에 근사하는 반환 값을 출력하는 단계;를 포함하되,상기 싱글-홉 오프로딩 환경 모듈은,상기 싱글-홉 오프로딩 환경 모듈이 상기 복수의 퀀텀 액터로부터 상기 행동 값을 전달받아 학습 데이터를 생성하는, 양자 다중 에이전트 강화학습 방법. |
| 8 | 제7항에 있어서,저장 모듈이 상기 싱글-홉 오프로딩 환경 모듈로부터 상기 학습 데이터셋을 전달받아 저장하는 단계; 및학습 모듈이 상기 학습 데이터셋을 기초로 상기 복수의 퀀텀 액터 및 상기 퀀텀 크리틱을 학습시키는 단계;를 더 포함하는 것을 특징으로 하는, 양자 다중 에이전트 강화학습 방법. |