| 번호 | 청구항 |
|---|---|
| 13 | 제12항에 있어서, 상기 FFT 프로세싱 엘리먼트 뱅크와 상기 비선형모듈 사이에 배치되며, 상기 가중치 블록 순환 행렬의 블록 크기를 분할하는, 쉬프트 연산자를 더 포함하는, 신경망 연산 가속기. |
| 14 | 제12항에 있어서, 상기 프루닝 과정이 완료된 가중치 블록 순환 행렬은 고속 푸리에 변환된 데이터인, 신경망 연산 가속기. |
| 1 | 프로세서; 및 신경망을 포함하며,상기 프로세서가, 상기 신경망의 각 레이어의 제1 블록 순환 행렬과 제2 블록 순환 행렬의 하다마드 곱인 제3 블록 순환 행렬을 획득하고, 상기 제3 블록 순환 행렬을 가중치로 이용하여 상기 신경망을 학습시키고,상기 신경망의 레이어들 중 임의의 레이어에 대하여, 학습된 상기 제1 블록 순환 행렬에 포함된 복수 개의 제1 서브 블록 순환 행렬들과 상기 제2 블록 순환 행렬에 포함된 복수 개의 제2 서브 블록 순환 행렬들을 각각 프루닝함으로써 상기 제1 블록 순환 행렬과 상기 제2 블록 순환 행렬을 파인 튜닝하는,컴퓨팅 시스템. |
| 2 | 제1항에 있어서, 상기 프로세서가, 상기 제1 서브 블록 순환 행렬들과 상기 제2 서브 블록 순환 행렬들을 프루닝할 때, 상기 제1 서브 블록 순환 행렬들 각각과 대응되는 제2 서브 블록 순환 행렬들 간의 하다마드 곱에 의하여 생성한 제3 서브 블록 순환 행렬들의 노름 값들을 계산하고, 상기 계산된 노름 값들을 정렬하고,미리 결정된 프루닝 비율을 이용하여 상기 제1 서브 블록 순환 행렬들 및 상기 제2 서브 블록 순환 행렬들 중 프루닝할 행렬들을 판정하는,컴퓨팅 시스템. |
| 3 | 제2항에 있어서, 상기 프로세서가, 상기 정렬된 노름 값들 중 가장 작은 값부터 상기 미리 결정된 프루닝 비율을 상기 제1 서브 블록 순환 행렬들의 개수와 곱한 값만큼의 서브 블록 순환 행렬들을 프루닝할 행렬들로 판정하는, 컴퓨팅 시스템. |
| 4 | 제1항에 있어서, 상기 프로세서가 프루닝함으로써 상기 제1 블록 순환 행렬과 상기 제2 블록 순환 행렬을 파인 튜닝하는 과정은 상기 파인 튜닝한 제1 블록 순환 행렬과 상기 파인 튜닝한 제2 블록 순환 행렬을 이용했을 때의 상기 신경망의 출력 정확도가 미리 결정된 정확도 이상인 동안 반복되는, 컴퓨팅 시스템. |
| 5 | 제2항 내지 제3항에 있어서, 상기 미리 결정된 프루닝 비율은 상기 제1 블록 순환 행렬과 상기 제2 블록 순환 행렬이 파인 튜닝될 때마다 미리 결정된 단계 프루닝 비율이 더해진 값으로 갱신되는, 컴퓨팅 시스템. |
| 6 | 제1항에 있어서, 상기 프로세서는 프루닝이 완료되면, 프루닝이 완료된 제1 블록 순환 행렬과 제2 블록 순환 행렬의 하다마드 곱인 제3 블록 순환 행렬을 고속 푸리에 변환하고, 상기 변환된 값을 상기 각 레이어의 연산을 위한 가속기에 입력으로 제공하며,상기 프로세서는 상기 제3 블록 순환 행렬의 서브 블록 순환 행렬들 중 프루닝된 서브 블록 순환 행렬에 대한 연산을 실행하지 않도록 프루닝 여부에 대한 인덱스 값을 상기 가속기에 제공하며,상기 가속기는 상기 인덱스 값을 이용하여 프루닝된 서브 블록 순환 행렬을 제외한 나머지 서브 블록 순환 행렬들에 대해서만 상기 변환된 값, 및 상기 신경망의 입력 데이터 간의 연산을 수행하는, 컴퓨팅 시스템. |
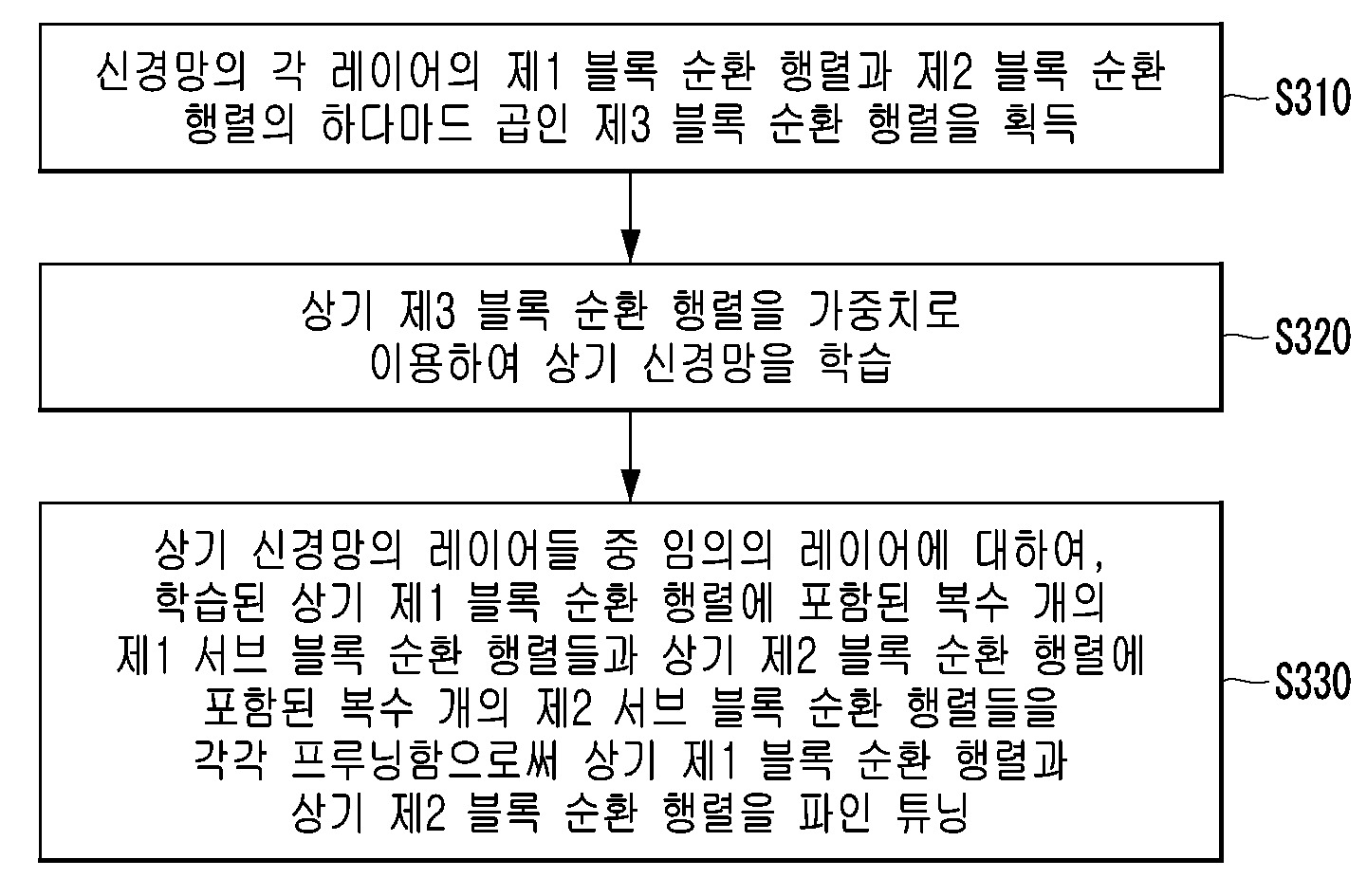
| 7 | 신경망의 각 레이어의 제1 블록 순환 행렬과 제2 블록 순환 행렬의 하다마드 곱인 제3 블록 순환 행렬을 획득하는 단계;상기 제3 블록 순환 행렬을 가중치로 이용하여 상기 신경망을 학습시키는 단계; 및상기 신경망의 레이어들 중 임의의 레이어에 대하여, 학습된 상기 제1 블록 순환 행렬에 포함된 복수 개의 제1 서브 블록 순환 행렬들과 상기 제2 블록 순환 행렬에 포함된 복수 개의 제2 서브 블록 순환 행렬들을 각각 프루닝함으로써 상기 제1 블록 순환 행렬과 상기 제2 블록 순환 행렬을 파인 튜닝하는 단계;를 포함하는,신경망 훈련 및 압축 방법. |
| 8 | 제7항에 있어서, 상기 파인 튜닝하는 단계는,상기 제1 서브 블록 순환 행렬들 각각과 대응되는 제2 서브 블록 순환 행렬들 간의 하다마드 곱에 의하여 생성한 제3 서브 블록 순환 행렬들의 노름 값들을 계산하는 단계;상기 계산된 노름 값들을 정렬하는 단계; 및미리 결정된 프루닝 비율을 이용하여 결정된 개수의 작은 노름 값들을 갖는 상기 제1 서브 블록 순환 행렬들 및 상기 제2 서브 블록 순환 행렬들을 프루닝할 행렬들로 판정하는 단계;를 포함하는,신경망 훈련 및 압축 방법. |
| 9 | 제8항에 있어서, 상기 프루닝할 행렬들로 판정하는 단계는,상기 정렬된 노름 값들 중 가장 작은 값부터 상기 미리 결정된 프루닝 비율을 상기 제1 서브 블록 순환 행렬들의 개수와 곱한 값만큼의 서브 블록 순환 행렬들을 프루닝할 행렬들로 판정하는 단계인,신경망 훈련 및 압축 방법. |
| 10 | 제7항에 있어서, 상기 파인 튜닝하는 단계는,상기 파인 튜닝한 제1 블록 순환 행렬과 상기 파인 튜닝한 제2 블록 순환 행렬을 이용했을 때의 상기 신경망의 출력 정확도가 미리 결정된 정확도 이상인 동안 반복되는, 신경망 훈련 및 압축 방법. |
| 11 | 제8항 내지 제9항에 있어서, 상기 파인 튜닝하는 단계는, 상기 제1 블록 순환 행렬과 상기 제2 블록 순환 행렬이 파인 튜닝될 때마다 상기 미리 결정된 프루닝 비율을 미리 결정된 단계 프루닝 비율이 더해진 값으로 갱신하는 단계를 더 포함하는, 신경망 훈련 및 압축 방법. |
| 12 | 신경망의 각 레이어의 입력 데이터, 프루닝 과정이 완료된 가중치 블록 순환 행렬, 및 프루닝 여부에 대한 인덱스 값을 입력 받는 버퍼; 상기 입력 데이터를 고속 푸리에 변환하는 FFT 프로세싱 엘리먼트 뱅크; 상기 고속 푸리에 변환된 데이터와 상기 가중치 블록 순환 행렬의 임의의 서브 블록 순환 행렬 간의 곱셈 누적 연산을 수행하는 MAC 프로세싱 엘리먼트 뱅크; 비선형모듈; 및컨트롤러;를 포함하며,상기 컨트롤러는 상기 프루닝 여부에 대한 인덱스 값을 이용하여 상기 임의의 서브 블록 순환 행렬이 프루닝된 경우, 상기 서브 블록 순환 행렬에 대한 상기 MAC 프로세싱 엘리먼트 뱅크의 실행을 건너 뛰고, 상기 서브 블록 순환 행렬이 프루닝되지 않은 경우 상기 MAC 프로세싱 엘리먼트 뱅크를 실행하며,상기 컨트롤러는 상기 FFT 프로세싱 엘리먼트 뱅크를 제어하여, 상기 MAC 프로세싱 엘리먼트 뱅크의 실행 결과 데이터를 역 고속 푸리에 변환하고, 상기 컨트롤러는 변환된 데이터를 상기 비선형 모듈을 통과시켜 상기 레이어의 출력 데이터로서 출력하는,신경망 연산 가속기. |
| 15 | 제12항에 있어서, 상기 프루닝 과정이 완료된 가중치 블록 순환 행렬은, 상기 신경망의 각 레이어의 제1 블록 순환 행렬과 제2 블록 순환 행렬의 하다마드 곱인 제3 블록 순환 행렬을 획득하고, 상기 제3 블록 순환 행렬을 가중치로 이용하여 상기 신경망을 학습시키고,상기 신경망의 레이어들 중 임의의 레이어에 대하여, 학습된 상기 제1 블록 순환 행렬에 포함된 복수 개의 제1 서브 블록 순환 행렬들과 상기 제2 블록 순환 행렬에 포함된 복수 개의 제2 서브 블록 순환 행렬들을 각각 프루닝함으로써 상기 제1 블록 순환 행렬과 상기 제2 블록 순환 행렬을 파인 튜닝하여,상기 파인 튜닝된 제1 블록 순환 행렬과 제2 블록 순환 행렬의 하다마드 곱에 의해 얻어진 제3 블록 순환 행렬인,신경망 연산 가속기. |