| 번호 | 청구항 |
|---|---|
| 15 | 제14항에 있어서,메인 메모리로부터 상기 신경망 모델의 제1 정밀도의 가중치 및 입력 데이터를 수신하여 제1 버퍼에 저장하는 단계를 더 포함하고,상기 제1 정밀도 연산을 수행하는 단계는, 상기 제1 버퍼에 저장된 가중치 및 입력 데이터를 이용하여 연산을 수행하고,상기 양자화하는 단계는, 상기 제1 버퍼에 저장된 가중치 및 입력 데이터를 양자화하는 것을 특징으로 하는 스케줄링 방법. |
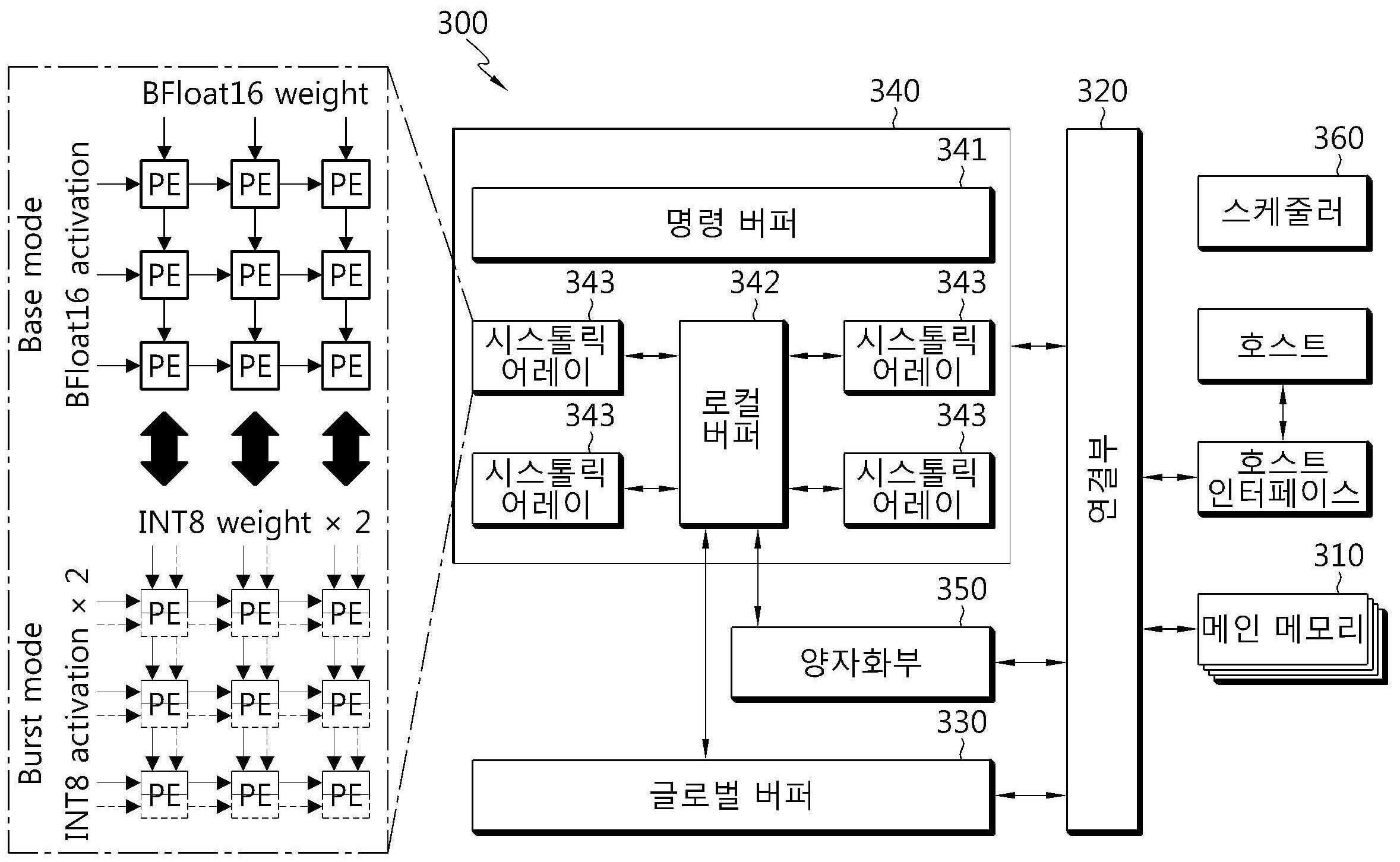
| 1 | 인공지능 추론을 위한 신경 처리 유닛에 있어서,제1 정밀도 연산을 위한 베이스 모드와 상기 제1 정밀도 보다 낮은 제2 정밀도 연산을 위한 버스트 모드 중 하나의 동작 모드를 결정하는 스케줄러;적어도 하나의 프로세싱 엘리먼트를 포함하는 적어도 하나의 시스톨릭 어레이를 포함하고, 상기 적어도 하나의 프로세싱 엘리먼트 각각은, 제1 곱셈기와 제1 덧셈기를 포함하는 제1 연산기; 및 제2 곱셈기와 제2 덧셈기를 포함하는 제2 연산기를 포함하며, 상기 베이스 모드에서 상기 제1 곱셈기, 상기 제1 덧셈기 및 상기 제2 덧셈기를 하나의 제1 정밀도 곱셈 누산(MAC, Multiply and Accumulation) 유닛으로 동작하여 제1 정밀도 연산을 수행하고, 상기 버스트 모드에서 상기 제1 곱셈기 및 상기 제1 덧셈기의 쌍과 상기 제2 곱셈기 및 상기 제2 덧셈기의 쌍 각각을 제2 정밀도 곱셈 누산(MAC) 유닛으로 동작하여 제2 정밀도 연산을 수행하는, 신경 처리 유닛. |
| 2 | 제1항에 있어서,상기 버스트 모드에서 신경망 모델의 제1 정밀도의 가중치 및 입력 데이터를 제2 정밀도의 가중치 및 입력 데이터로 양자화하여 상기 제2 정밀도 곱셈 누산 유닛으로 전달하는 양자화부를 더 포함하는 것을 특징으로 하는 신경 처리 유닛. |
| 3 | 제2항에 있어서,메인 메모리로부터 상기 신경망 모델의 제1 정밀도의 가중치 및 입력 데이터를 수신하여 저장하는 제1 버퍼를 더 포함하고,상기 베이스 모드에서 상기 제1 버퍼에 저장된 가중치 및 입력 데이터가 상기 적어도 하나의 시스톨릭 어레이로 전달되고,상기 버스트 모드에서 상기 제1 버퍼에 저장된 가중치 및 입력 데이터가 상기 양자화부를 통해 제2 정밀도의 가중치 및 입력 데이터로 양자화되어 상기 적어도 하나의 시스톨릭 어레이로 전달되는 것을 특징으로 하는 신경 처리 유닛. |
| 4 | 제2항에 있어서,상기 양자화부는,호스트에서 미리 계산된 양자화 파라미터를 고정 값으로 저장하고 그 양자화 파라미터를 이용하여 양자화를 수행하는 것을 특징으로 하는 신경 처리 유닛. |
| 5 | 제2항에 있어서,상기 양자화부는,추론 중 신경망 모델의 활성화(activation)를 참조하여 양자화 파라미터를 동적으로 계산하고 동적으로 계산된 양자화 파라미터를 이용하여 양자화를 수행하는 것을 특징으로 하는 신경 처리 유닛. |
| 6 | 제5항에 있어서,상기 양자화부는,상기 신경망 모델의 활성화의 범위를 관찰하여 제1 정밀도 데이터의 최대/최소를 결정하고, 제1 정밀도 데이터의 최대/최소를 제2 정밀도 데이터의 최대/최소에 매칭시키며, 매칭 결과에 기초하여 양자화 파라미터를 계산하는 것을 특징으로 하는 신경 처리 유닛. |
| 7 | 제6항에 있어서,상기 양자화부는,상기 제1 버퍼에 저장되는 상기 신경망 모델의 활성화의 범위를 관찰하여 제1 정밀도 데이터의 최대/최소를 결정하는 옵저버;제1 정밀도 데이터의 최대/최소를 제2 정밀도 데이터의 최대/최소에 매칭한 매칭 결과에 따른 양자화 파라미터를 저장하는 테이블; 및상기 테이블에 저장된 양자화 파라미터에 따라 양자화를 수행하는 양자화기를 포함하는 것을 특징으로 하는 신경 처리 유닛. |
| 8 | 제4항 내지 제7항 중 어느 한 항에 있어서,상기 양자화 파라미터는,스케일 팩터 및 바이어스를 포함하는 것을 특징으로 하는 신경 처리 유닛. |
| 9 | 제1항에 있어서,상기 스케줄러는,평균 추론 지연시간들의 평균과 서비스 수준 목표의 차이에 따라 목표 지연시간을 설정하고, 최근 추론 지연시간과 목표 지연시간의 비교 결과에 따라 동작 모드를 결정하는 것을 특징으로 하는 신경 처리 유닛. |
| 10 | 제9항에 있어서,상기 스케줄러는,최근 추론 지연시간이 상기 목표 지연시간을 위반하는 경우 동작 모드를 버스트 모드로 결정하고, 최근 추론 지연시간이 상기 목표 지연시간을 위반하지 않는 경우 동작 모드를 베이스 모드로 결정하는 것을 특징으로 하는 신경 처리 유닛. |
| 11 | 제9항에 있어서,상기 스케줄러는,최근 추론 지연시간이 상기 목표 지연시간을 위반하고 추론 지연시간들이 증가 추세인 경우 동작 모드를 버스트 모드로 결정하고, 최근 추론 지연시간이 목표 지연시간을 위반하지만 추론 지연시간들이 감소 추세인 경우 동작 모드를 베이스 모드로 결정하는 것을 특징으로 하는 신경 처리 유닛. |
| 12 | 제9항 내지 제11항 중 어느 한 항에 있어서,상기 스케줄러는,상기 차이가 작을수록 상기 목표 지연시간을 낮게 설정하는 것을 특징으로 하는 신경 처리 유닛. |
| 13 | 적어도 하나의 프로세싱 엘리먼트를 포함하는 적어도 하나의 시스톨릭 어레이를 포함하고, 상기 적어도 하나의 프로세싱 엘리먼트 각각은, 제1 곱셈기와 제1 덧셈기를 포함하는 제1 연산기; 및 제2 곱셈기와 제2 덧셈기를 포함하는 제2 연산기를 포함하는, 인공지능 추론을 위한 신경 처리 유닛의 스케줄링 방법에 있어서,제1 정밀도 연산을 위한 베이스 모드와 상기 제1 정밀도 보다 낮은 제2 정밀도 연산을 위한 버스트 모드 중 하나의 동작 모드를 결정하는 단계;상기 베이스 모드에서 상기 제1 곱셈기, 상기 제1 덧셈기 및 상기 제2 덧셈기를 하나의 제1 정밀도 곱셈 누산(MAC, Multiply and Accumulation) 유닛으로 동작하여 제1 정밀도 연산을 수행하는 단계; 및상기 버스트 모드에서 상기 제1 곱셈기 및 상기 제1 덧셈기의 쌍과 상기 제2 곱셈기 및 상기 제2 덧셈기의 쌍 각각을 제2 정밀도 곱셈 누산(MAC) 유닛으로 동작하여 제2 정밀도 연산을 수행하는 단계를 포함하는 스케줄링 방법, |
| 14 | 제13항에 있어서,상기 제2 정밀도 연산을 수행하는 단계 이전에,상기 버스트 모드에서 신경망 모델의 제1 정밀도의 가중치 및 입력 데이터를 제2 정밀도의 가중치 및 입력 데이터로 양자화하는 단계를 더 포함하고,상기 제2 정밀도 연산을 수행하는 단계는, 양자화된 가중치 및 입력 데이터로 연산을 수행하는 것을 특징으로 하는 스케줄링 방법. |
| 16 | 제14항에 있어서,상기 양자화하는 단계는,호스트에서 미리 계산된 양자화 파라미터를 고정 값으로 저장하고 그 양자화 파라미터를 이용하여 양자화를 수행하는 것을 특징으로 하는 스케줄링 방법. |
| 17 | 제14항에 있어서,상기 양자화하는 단계는,추론 중 신경망 모델의 활성화(activation)를 참조하여 양자화 파라미터를 동적으로 계산하고 동적으로 계산된 양자화 파라미터를 이용하여 양자화를 수행하는 것을 특징으로 하는 스케줄링 방법. |
| 18 | 제17항에 있어서,상기 양자화하는 단계는,상기 신경망 모델의 활성화의 범위를 관찰하여 제1 정밀도 데이터의 최대/최소를 결정하고, 제1 정밀도 데이터의 최대/최소를 제2 정밀도 데이터의 최대/최소에 매칭시키며, 매칭 결과에 기초하여 양자화 파라미터를 계산하는 것을 특징으로 하는 스케줄링 방법. |
| 19 | 제16항 내지 제18항 중 어느 한 항에 있어서,상기 양자화 파라미터는,스케일 팩터 및 바이어스를 포함하는 것을 특징으로 하는 스케줄링 방법. |
| 20 | 제13항에 있어서,상기 결정하는 단계는,평균 추론 지연시간들의 평균과 서비스 수준 목표의 차이에 따라 목표 지연시간을 설정하고, 최근 추론 지연시간과 목표 지연시간의 비교 결과에 따라 동작 모드를 결정하는 것을 특징으로 하는 스케줄링 방법. |
| 21 | 제20항에 있어서,상기 결정하는 단계는,최근 추론 지연시간이 상기 목표 지연시간을 위반하는 경우 동작 모드를 버스트 모드로 결정하고, 최근 추론 지연시간이 상기 목표 지연시간을 위반하지 않는 경우 동작 모드를 베이스 모드로 결정하는 것을 특징으로 하는 스케줄링 방법. |
| 22 | 제20항에 있어서,상기 결정하는 단계는,최근 추론 지연시간이 상기 목표 지연시간을 위반하고 추론 지연시간들이 증가 추세인 경우 동작 모드를 버스트 모드로 결정하고, 최근 추론 지연시간이 목표 지연시간을 위반하지만 추론 지연시간들이 감소 추세인 경우 동작 모드를 베이스 모드로 결정하는 것을 특징으로 하는 스케줄링 방법. |
| 23 | 제20항 내지 제22항 중 어느 한 항에 있어서,상기 결정하는 단계는,상기 차이가 작을수록 상기 목표 지연시간을 낮게 설정하는 것을 특징으로 하는 스케줄링 방법. |