| 번호 | 청구항 |
|---|---|
| 1 | 컴퓨팅 디바이스에 의한 개인정보 비식별 데이터의 품질 측정 방법에 있어서,복수의 개인에 대한 개인 정보를 담고 있는 트랜잭션 데이터베이스에서 동일한 항목 집합들이 최소 서로 다른 개인의 트랜잭션에 나타날 때 특정 개인의 식별여부를 검증하는 모델인 개인 중복도 모델을 이용하여 재식별 위험성을 검증하는 단계; 및원본 레코드와 비식별 레코드 차이에 대한 통계적 유사성을 수치적으로 측정한 활용 품질 지표를 이용하여 원본 유사도를 측정하는 단계를 포함하고,상기 활용 품질 지표를 이용하여 원본 유사도를 측정하는 단계는 트랜잭션 레코드의 각 항목에 대한 1-항목 원본 유사도를 형성하고, 각 항목 별 원본 유사도와 원본 데이터 세트를 비교하여 상기 트랜잭션 레코드의 원본 유사도를 계산하는 단계를 포함하고,상기 1-항목 원본 유사도는 항목 전체의 도메인 크기 대비 항목 계층 정보를 나타내는 자식 노드의 수로 계산을 하며, 상기 원본 유사도와 정보 손실이 반비례하는 것을 특징으로 하는 개인정보 비식별 데이터의 품질 측정 방법. |
| 2 | 제1항에 있어서,상기 개인 중복도 모델을 이용하여 재식별 위험성을 검증하는 단계는,개인 정보의 항목이 나타난 상기 트랜잭션을 발생시킨 각 개인들의 총 합인 개인 중복수를 지지도의 개념으로 사용하여 개인 중복도 기반 빈발 항목 집합을 찾아 개인 중복도 기반 테이블을 생성하는 단계; 및상기 개인 중복도 기반 테이블을 기반으로, 상기 개인 중복도 모델에 따라 개인 중복도를 검증하는 단계를 포함하는 것을 특징으로 하는 개인정보 비식별 데이터의 품질 측정 방법. |
| 3 | 제2항에 있어서,상기 개인 중복도를 검증하는 단계는,상기 개인 중복도 모델이 1일 경우, 개인 최소 지지도를 1로 두고 상기 개인 최소 지지도를 넘지 못하는 항목 집합을 갖는 재식별 위험이 있는 레코드를 기반으로 재식별 위험도를 계산하는 단계; 및상기 개인 중복도 모델이 2 이상일 경우, 특정 개인을 추정하는 가능성을 확률로 평가하여 상기 트랜잭션 데이터베이스에 따른 개인 추정 가능성 위험을 통해 개인 추정 가능성을 계산하는 단계를 더 포함하는 개인정보 비식별 데이터의 품질 측정 방법. |
| 4 | 제1항에 있어서,상기 활용 품질 지표를 이용하여 원본 유사도를 측정하는 단계는,원본 데이터를 비식별 데이터로 변환하는 과정에서 비식별 처리에 위반하는 레코드를 제거하여 상기 원본 데이터 수보다 적은 수의 상기 비식별 레코드를 형성하며, 상기 비식별 레코드의 수 및 상기 원본 레코드의 수를 이용하여 잔존율을 계산하는 단계를 포함하는 개인정보 비식별 데이터의 품질 측정 방법. |
| 5 | 삭제 |
| 6 | 삭제 |
| 7 | 제1항에 있어서,상기 트랜잭션 레코드의 원본 유사도는 상기 트랜잭션에 해당하는 각 항목들이 상기 항목들의 전체 크기로 가중치를 가지며, 상기 1-항목 원본 유사도에 상기 가중치를 부여하여 계산하는 것을 특징으로 하는 개인정보 비식별 데이터의 품질 측정 방법. |
| 8 | 제7항에 있어서,상기 트랜잭션 레코드의 원본 유사도는 원본 레코드 세트와 비식별 결과 레코드 세트 사이의 유사도를 나타내며, 상기 비식별 결과 레코드 세트의 각각의 레코드에 대한 상기 원본 레코드와의 유사도를 계산하고, 상기 유사도를 평균 내어 결과 유사도를 산출하며,상기 결과 유사도는 비식별 조치에 대한 상기 통계적 유사성 및 상기 활용 품질 지표로 활용하는 것을 특징으로 하는 개인정보 비식별 데이터의 품질 측정 방법. |
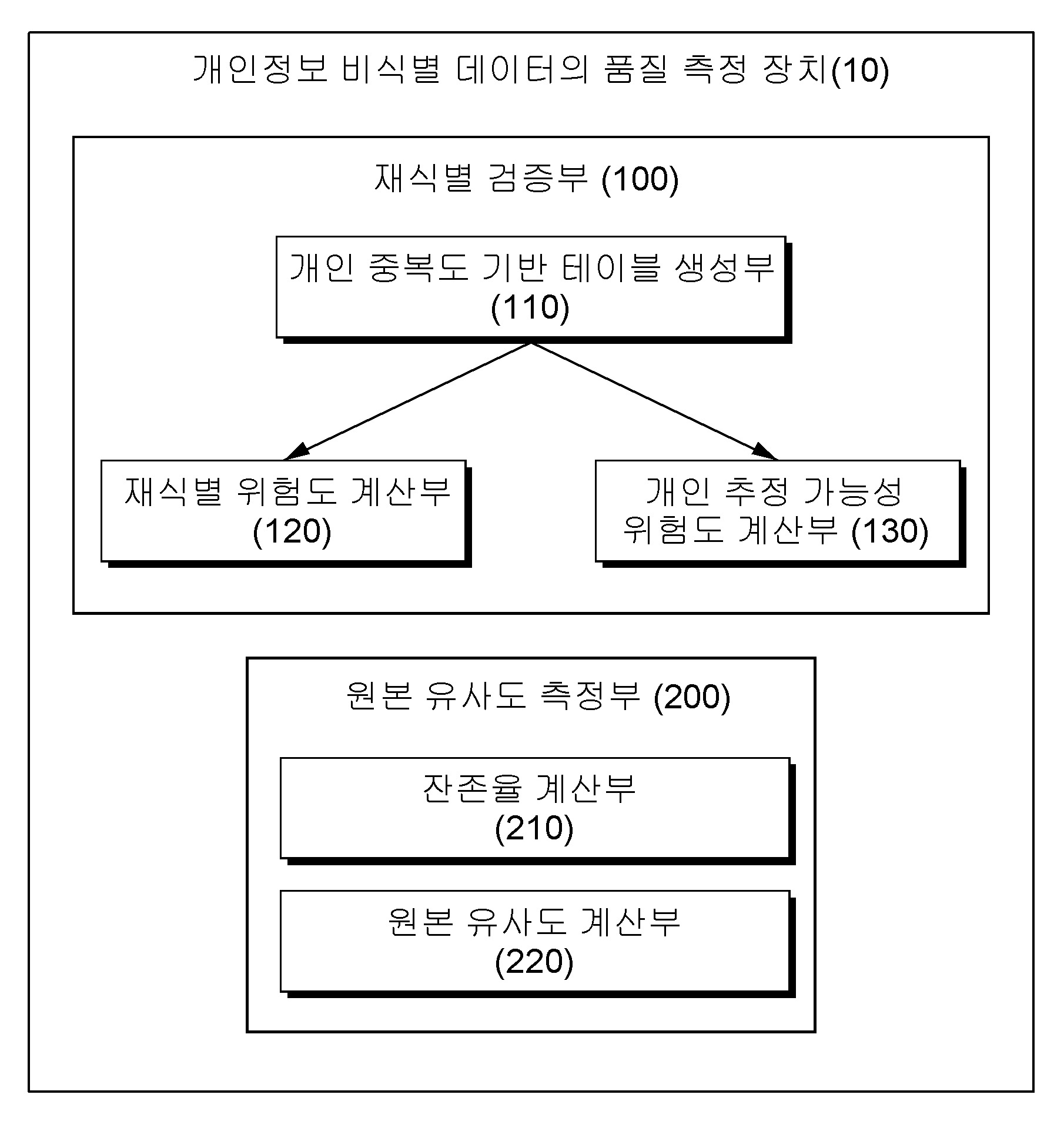
| 9 | 복수의 개인에 대한 개인 정보를 담고 있는 트랜잭션 데이터베이스에서 동일한 항목 집합들이 최소 서로 다른 개인의 트랜잭션에 나타날 때 특정 개인의 식별여부를 검증하는 모델인 개인 중복도 모델을 이용하여 재식별 위험성을 검증하는 재식별 검증부; 및원본 레코드와 비식별 레코드 차이에 대한 통계적 유사성을 수치적으로 측정한 활용 품질 지표를 이용하여 원본 유사도를 측정하는 원본 유사도 측정부를 포함하고,상기 원본 유사도 측정부는 트랜잭션 레코드의 각 항목에 대한 1-항목 원본 유사도를 형성하고, 각 항목 별 원본 유사도와 원본 데이터 세트를 비교하여 트랜잭션 레코드의 원본 유사도를 계산하는 원본 유사도 계산부를 포함하고,상기 1-항목 원본 유사도는 항목 전체의 도메인 크기 대비 항목 계층 정보를 나타내는 자식 노드의 수로 계산을 하며, 상기 원본 유사도와 정보 손실이 반비례하는 것을 특징으로 하는 개인정보 비식별 데이터의 품질 측정 장치. |
| 10 | 제9항에 있어서,상기 원본 유사도 측정부는,원본 데이터를 비식별 데이터로 변환하는 과정에서 비식별 처리에 위반하는 레코드를 제거하여 상기 원본 데이터 수보다 적은 수의 상기 비식별 레코드를 형성하며, 상기 비식별 레코드의 수 및 상기 원본 레코드의 수를 이용하여 잔존율을 계산하는 잔존율 계산부를 포함하는 개인정보 비식별 데이터의 품질 측정 장치. |
| 11 | 삭제 |
| 12 | 삭제 |
| 13 | 제9항에 있어서,상기 트랜잭션 레코드의 원본 유사도는 상기 트랜잭션에 해당하는 각 항목들이 상기 항목들의 전체 크기로 가중치를 가지며, 상기 1-항목 원본 유사도에 상기 가중치를 부여하여 계산하는 것을 특징으로 하는 개인정보 비식별 데이터의 품질 측정 장치. |
| 14 | 제9항에 있어서,상기 트랜잭션 레코드의 원본 유사도는 원본 레코드 세트와 비식별 결과 레코드 세트 사이의 유사도를 나타내며, 상기 비식별 결과 레코드 세트의 각각의 레코드에 대한 상기 원본 레코드와의 유사도를 계산하고, 상기 유사도를 평균 내어 결과 유사도를 산출하며,상기 결과 유사도는 비식별 조치에 대한 통계적 유사성 및 활용성 품질 지표로 활용하는 것을 특징으로 하는 개인정보 비식별 데이터의 품질 측정 장치. |