| 번호 | 청구항 |
|---|---|
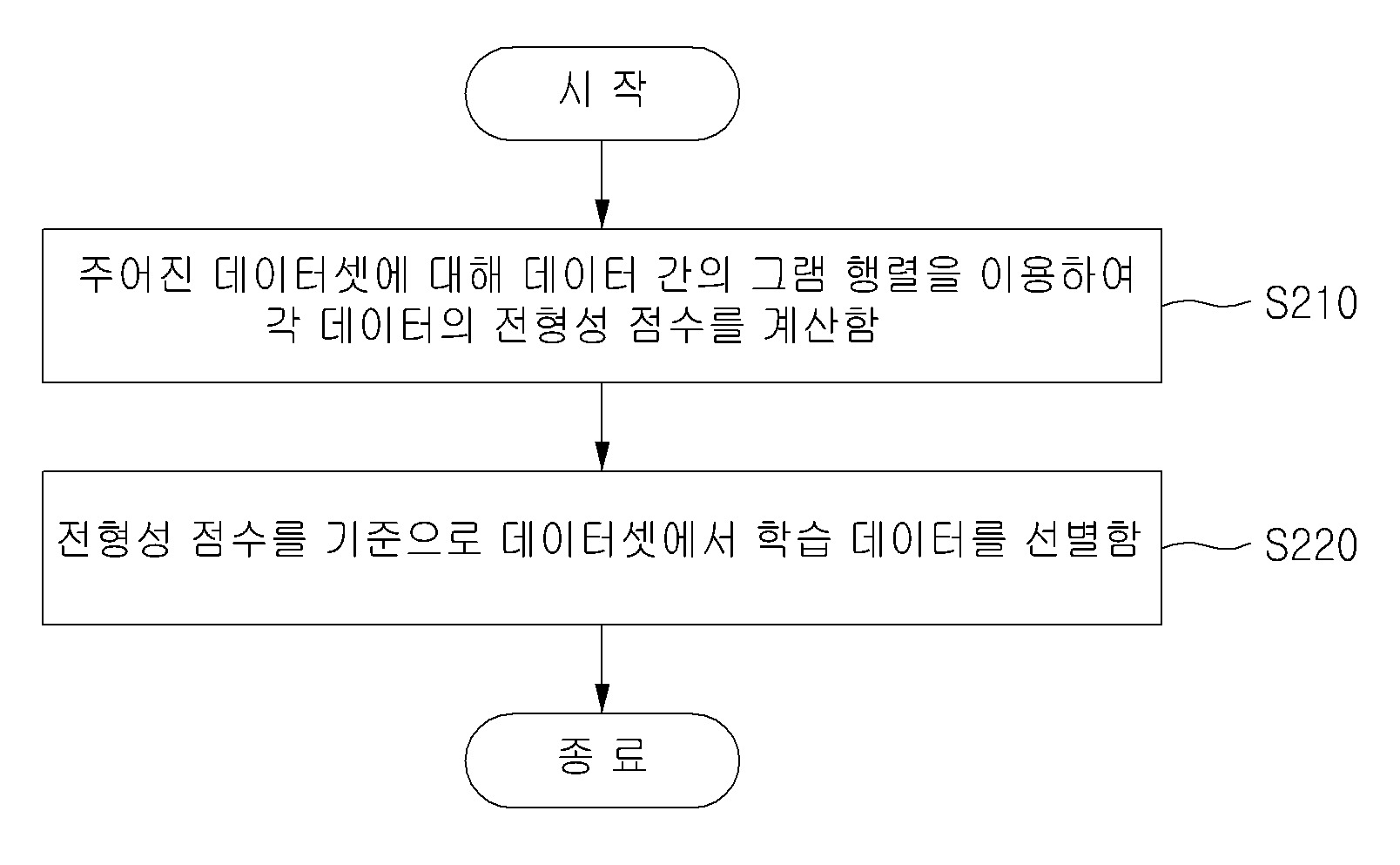
| 1 | 컴퓨터 장치에서 실행되는 데이터 평가 방법에 있어서,상기 컴퓨터 장치는 메모리에 포함된 컴퓨터 판독가능한 명령들을 실행하도록 구성된 적어도 하나의 프로세서를 포함하고,상기 데이터 평가 방법은,상기 적어도 하나의 프로세서에 의해, 주어진 데이터셋에 대해 데이터 간의 그램 행렬(gram matrix)을 이용하여 각 데이터의 전형성 정도를 나타내는 복잡도-격차 점수(complexity-gap score)를 계산하는 단계를 포함하고,상기 복잡도-격차 점수(CG)는 수학식 1과 같이 정의되는 것으로, 데이터들로 생성되는 그램 행렬 H과 레이블 벡터(label vector) y를 바탕으로 계산되고,수학식 1: 수학식 1에서 는 레이블 벡터 y를 전치(transpose)한 것이고, 은 그램 행렬 H의 역행렬(inverse matrix)을 나타내고,상기 데이터셋 으로 생성되는 그램 행렬 은 수학식 2와 같이 정의되고,수학식 2: 수학식 1에서 와 는 상기 데이터셋 에서 i번째 데이터 를 제외한 뒤 계산한 그램 행렬과 레이블 벡터를 의미하는 것을 특징으로 하는 데이터 평가 방법. |
| 2 | 삭제 |
| 3 | 삭제 |
| 4 | 제1항에 있어서,상기 계산하는 단계는,부분 행렬(sub matrix)의 역행렬을 구하는 공식인 슈어 보수(Schur complement)를 통해 전체 그램 행렬의 역행렬을 구하여 상기 복잡도-격차 점수를 계산하는 것을 특징으로 하는 데이터 평가 방법. |
| 5 | 제1항에 있어서,상기 계산하는 단계는,데이터의 피처(feature)를 입력 값으로 이용하여 상기 복잡도-격차 점수를 계산하는 것을 특징으로 하는 데이터 평가 방법. |
| 6 | 제1항에 있어서,상기 데이터 평가 방법은,상기 적어도 하나의 프로세서에 의해, 상기 복잡도-격차 점수를 기준으로 상기 데이터셋에서 일부 데이터를 선별하는 단계를 더 포함하는 데이터 평가 방법. |
| 7 | 제6항에 있어서,상기 선별하는 단계는,상기 복잡도-격차 점수를 이용하여 상기 데이터셋에서 모델 학습에 사용할 학습 데이터를 선별하는 것을 특징으로 하는 데이터 평가 방법. |
| 8 | 제6항에 있어서,상기 선별하는 단계는,상기 데이터셋에서 상기 복잡도-격차 점수가 임계치(threshold) 미만인 데이터를 제거하는 단계를 포함하는 데이터 평가 방법. |
| 9 | 제6항에 있어서,상기 선별하는 단계는,상기 복잡도-격차 점수를 이용하여 상기 데이터셋에서 노이즈 데이터를 감지하는 단계를 포함하는 데이터 평가 방법. |
| 10 | 데이터 평가 방법을 컴퓨터에 실행시키기 위해 컴퓨터 판독가능한 기록 매체에 저장되는 컴퓨터 프로그램에 있어서,상기 데이터 평가 방법은,주어진 데이터셋에 대해 데이터 간의 그램 행렬(gram matrix)을 이용하여 각 데이터의 전형성 정도를 나타내는 복잡도-격차 점수(complexity-gap score)를 계산하는 단계를 포함하고,상기 복잡도-격차 점수(CG)는 수학식 1과 같이 정의되는 것으로, 데이터들로 생성되는 그램 행렬 H과 레이블 벡터(label vector) y를 바탕으로 계산되고,수학식 1: 수학식 1에서 는 레이블 벡터 y를 전치(transpose)한 것이고, 은 그램 행렬 H의 역행렬(inverse matrix)을 나타내고,상기 데이터셋 으로 생성되는 그램 행렬 은 수학식 2와 같이 정의되고,수학식 2: 수학식 1에서 와 는 상기 데이터셋 에서 i번째 데이터 를 제외한 뒤 계산한 그램 행렬과 레이블 벡터를 의미하는 것을 특징으로 하는, 컴퓨터 프로그램. |
| 11 | 컴퓨터 장치에 있어서,메모리에 포함된 컴퓨터 판독가능한 명령들을 실행하도록 구성된 적어도 하나의 프로세서를 포함하고,상기 적어도 하나의 프로세서는,주어진 데이터셋에 대해 데이터 간의 그램 행렬(gram matrix)을 이용하여 각 데이터의 전형성 정도를 나타내는 복잡도-격차 점수(complexity-gap score)를 계산하는 과정; 및상기 복잡도-격차 점수를 기준으로 상기 데이터셋에서 모델 학습에 사용할 학습 데이터를 선별하는 과정을 처리하고,상기 복잡도-격차 점수(CG)는 수학식 1과 같이 정의되는 것으로, 데이터들로 생성되는 그램 행렬 H과 레이블 벡터(label vector) y를 바탕으로 계산되고,수학식 1: 수학식 1에서 는 레이블 벡터 y를 전치(transpose)한 것이고, 은 그램 행렬 H의 역행렬(inverse matrix)을 나타내고,상기 데이터셋 으로 생성되는 그램 행렬 은 수학식 2와 같이 정의되고,수학식 2: 수학식 1에서 와 는 상기 데이터셋 에서 i번째 데이터 를 제외한 뒤 계산한 그램 행렬과 레이블 벡터를 의미하는 것을 특징으로 하는 컴퓨터 장치. |
| 12 | 삭제 |
| 13 | 삭제 |
| 14 | 제11항에 있어서,상기 적어도 하나의 프로세서는,부분 행렬(sub matrix)의 역행렬을 구하는 공식인 슈어 보수(Schur complement)를 통해 전체 그램 행렬의 역행렬을 구하여 상기 복잡도-격차 점수를 계산하는 것을 특징으로 하는 컴퓨터 장치. |
| 15 | 제11항에 있어서,상기 적어도 하나의 프로세서는,데이터의 피처(feature)를 입력 값으로 이용하여 상기 복잡도-격차 점수를 계산하는 것을 특징으로 하는 컴퓨터 장치. |