| 번호 | 청구항 |
|---|---|
| 14 | 하드웨어와 결합되어 제1항, 제3항 내지 제8항, 제10항 내지 제13항 중 어느 하나의 항의 방법을 실행시키기 위하여 컴퓨터 판독 가능한 기록매체에 저장된 컴퓨터 프로그램. |
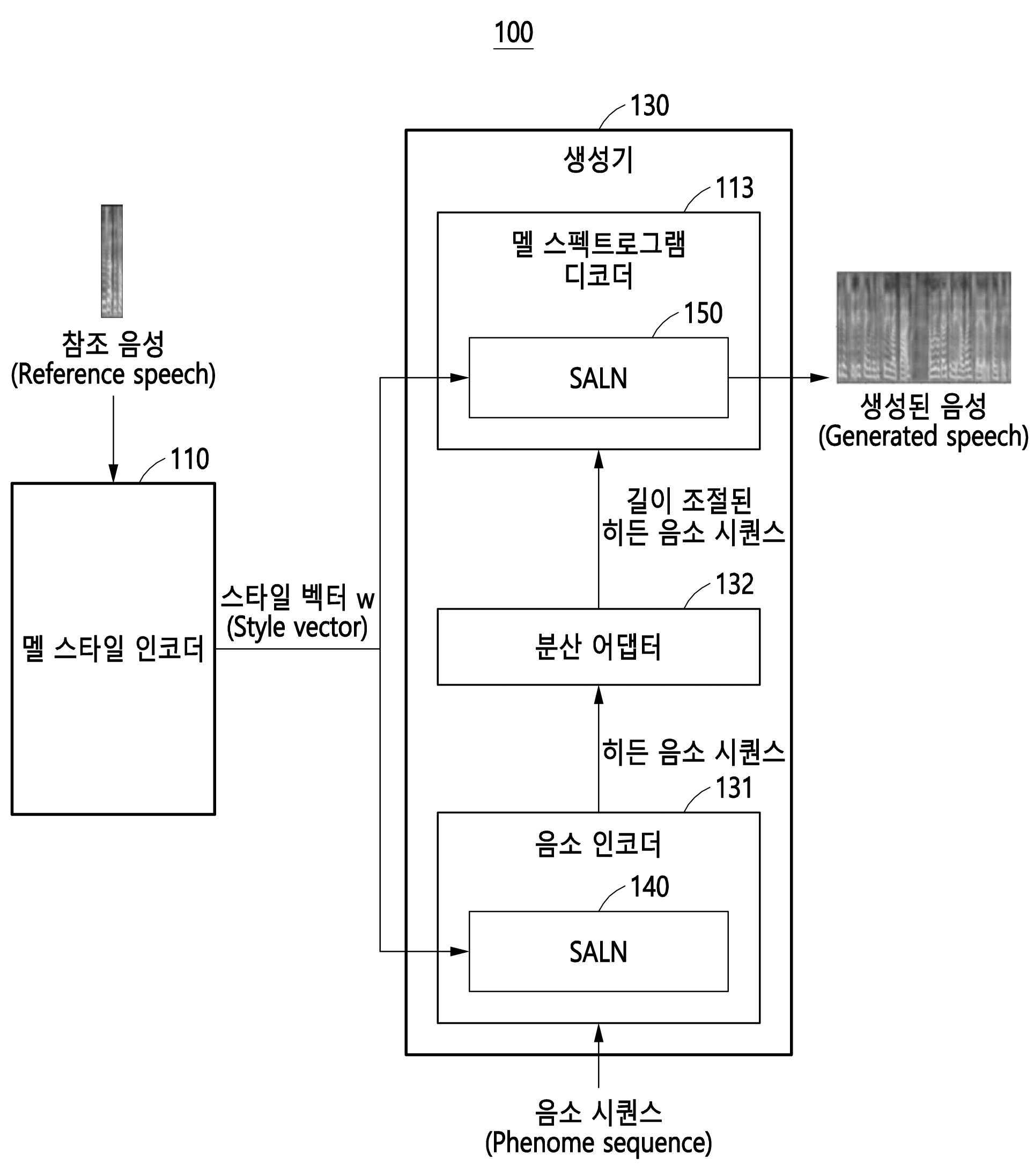
| 1 | 전자 장치가 수행하는 스타일 스피치 생성 방법에 있어서,상기 전자 장치가 참조 음성으로부터 상기 참조 음성의 특징에 대응하는 스타일 벡터를 추출하는 동작;상기 전자 장치가 음소 시퀀스 및 상기 스타일 벡터에 기초하여 상기 음소 시퀀스에 관한 복수의 SALN(style-adaptive layer normalization) 벡터를 생성하는 동작; 및상기 전자 장치가 상기 복수의 SALN 벡터에 기초하여 상기 음소 시퀀스를 상기 특징에 따라 발화한 음성인 스타일 스피치를 생성하는 동작을 포함하고,상기 추출하는 동작은,상기 참조 음성을 분석하여 분석 정보를 획득하는 동작;상기 분석 정보에 기초하여 상기 참조 음성을 이루는 복수의 프레임 중 상기 특징과 관련성이 가장 높은 프레임을 결정하는 동작; 및결정된 프레임의 정보에 기초하여 상기 스타일 벡터를 생성하는 동작을 포함하는, 스타일 스피치 생성 방법. |
| 2 | 삭제 |
| 3 | 제1항에 있어서,상기 획득하는 동작은,상기 참조 음성을 주파수 축 및 시간 축으로 순차적으로 분석하여 상기 참조 음성의 히든 시퀀스(hidden sequence)에 포함된 순차 정보(sequential information)를 획득하는 동작를 포함하는, 스타일 스피치 생성 방법. |
| 4 | 제1항에 있어서,상기 복수의 SALN 벡터는,상기 음소 시퀀스의 제1 히든 음소 시퀀스에 포함된 복수의 음소 각각을 상기 특징에 따라 발화한 음성에 대응하는 복수의 제1 SALN 벡터; 및상기 제1 히든 음소 시퀀스의 길이가 조절된 제2 히든 음소 시퀀스에 포함된 복수의 음소 각각을 상기 특징에 따라 발화한 음성에 대응하는 복수의 제2 SALN 벡터를 포함하고,상기 복수의 SALN 벡터를 생성하는 동작은,상기 음소 시퀀스에 포함된 복수의 음소의 특징 벡터 및 상기 스타일 벡터에 기초하여 상기 복수의 제1 SALN 벡터를 생성하는 동작; 및상기 제2 히든 음소 시퀀스에 포함된 복수의 음소의 특징 벡터 및 상기 스타일 벡터에 기초하여 상기 복수의 제2 SALN 벡터를 생성하는 동작을 포함하는, 스타일 스피치 생성 방법. |
| 5 | 제4항에 있어서,상기 각각의 특징 벡터는,상기 복수의 음소를 음소마다 가지는 하나 이상의 특징을 기준으로 다른 음소와 비교함으로써 상기 복수의 음소 간의 상호 관계를 분석하여 획득된 것인, 스타일 스피치 생성 방법. |
| 6 | 제5항에 있어서,상기 하나 이상의 특징은,높낮음(pitch), 에너지(energy), 및 지속 시간(duration time)을 포함하는 것인, 스타일 스피치 생성 방법. |
| 7 | 전자 장치가 수행하는 음소 시퀀스를 음성 샘플이 가지는 특징에 따라 발화한 스타일 스피치를 생성하는 스타일 스피치 모델의 생성 방법에 있어서,상기 전자 장치가 상기 음성 샘플로부터 상기 특징에 대응하는 스타일 벡터를 추출하는 동작;상기 전자 장치가 상기 음소 시퀀스(phenome sequence) 및 상기 스타일 벡터에 기초하여 상기 음소 시퀀스에 관한 복수의 SALN(style-adaptive layer normalization) 벡터를 생성하는 동작; 및상기 전자 장치가 상기 스타일 벡터, 상기 음성 샘플, 및 상기 복수의 SALN 벡터에 기초하여 스타일 스피치(style speech)모델을 생성하는 동작을 포함하고,상기 음소 시퀀스는,상기 음성 샘플에 대응하는 음소 시퀀스 샘플; 및상기 특징에 따라 발화하려는 타겟 음소 시퀀스(target phenome sequence)를 포함하고,상기 추출하는 동작은,상기 음성 샘플을 분석하여 분석 정보를 획득하는 동작;상기 분석 정보에 기초하여 상기 음성 샘플을 이루는 복수의 프레임 중 상기 특징과 관련성이 가장 높은 프레임을 결정하는 동작; 및결정된 프레임의 정보에 기초하여 상기 스타일 벡터를 생성하는 동작을 포함하는, 스타일 스피치 모델 생성 방법. |
| 8 | 제7항에 있어서,상기 생성하는 동작은,상기 스타일 벡터 및 상기 음소 시퀀스 샘플에 기초하여 상기 특징에 따라 상기 음소 시퀀스를 발화하는 음성을 생성하는 동작;생성된 음성 및 상기 음성 샘플에 기초하여 상기 스타일 스피치 모델에 포함된 멜 스타일 인코더 및 생성기를 생성하는 동작; 및상기 복수의 SALN(style-adaptive layer normalization) 벡터 및 상기 타겟 음소 시퀀스에 기초하여 상기 스타일 스피치 모델에 포함된 판별기를 생성하는 동작을 포함하는, 스타일 스피치 모델 생성 방법. |
| 9 | 삭제 |
| 10 | 제7항에 있어서,상기 획득하는 동작은,상기 음성 샘플을 주파수 축 및 시간 축으로 순차적으로 분석하여 상기 음성 샘플의 히든 시퀀스(hidden sequence)에 포함된 순차 정보(sequential information)를 획득하는 동작를 포함하는, 스타일 스피치 모델 생성 방법. |
| 11 | 제7항에 있어서,상기 복수의 SALN 벡터는,상기 음소 시퀀스의 제1 히든 음소 시퀀스에 포함된 복수의 음소 각각을 상기 특징에 따라 발화한 음성에 대응하는 복수의 제1 SALN 벡터; 및상기 제1 히든 음소 시퀀스의 길이가 조절된 제2 히든 음소 시퀀스에 포함된 복수의 음소 각각을 상기 특징에 따라 발화한 음성에 대응하는 복수의 제2 SALN 벡터를 포함하고,상기 복수의 SALN 벡터를 생성하는 동작은,상기 음소 시퀀스에 포함된 복수의 음소의 특징 벡터 및 상기 스타일 벡터에 기초하여 상기 복수의 제1 SALN 벡터를 생성하는 동작; 및상기 제2 히든 음소 시퀀스에 포함된 복수의 음소 각각의 특징 벡터 및 상기 스타일 벡터에 기초하여 상기 복수의 제2 SALN 벡터를 생성하는 동작을 포함하는, 스타일 스피치 모델 생성 방법. |
| 12 | 제11항에 있어서,상기 각각의 특징 벡터는,상기 복수의 음소를 음소마다 가지는 하나 이상의 특징을 기준으로 다른 음소와 비교함으로써 상기 복수의 음소 간의 상호 관계를 분석하여 획득된 것인, 스타일 스피치 모델 생성 방법. |
| 13 | 제12항에 있어서,상기 하나 이상의 특징은,높낮음(pitch), 에너지(energy), 및 지속 시간(duration time)을 포함하는 것인, 스타일 스피치 모델 생성 방법. |
| 15 | 인스트럭션들을 포함하는 메모리; 및상기 메모리와 전기적으로 연결되고, 상기 인스트럭션들을 실행하기 위한 프로세서를 포함하고,상기 프로세서에 의해 상기 인스트럭션들이 실행될 때, 상기 프로세서는,참조 음성으로부터 상기 참조 음성의 특징에 대응하는 스타일 벡터를 추출하고,음소 시퀀스 및 상기 스타일 벡터에 기초하여 상기 음소 시퀀스에 관한 복수의 SALN(style-adaptive layer normalization) 벡터를 생성하며,상기 복수의 SALN 벡터에 기초하여 상기 음소 시퀀스를 상기 특징에 따라 발화한 음성인 스타일 스피치를 생성하고,상기 프로세서는,상기 참조 음성을 분석하여 분석 정보를 획득하고,상기 분석 정보에 기초하여 상기 참조 음성을 이루는 복수의 프레임 중 상기 특징과 관련성이 가장 높은 프레임을 결정하며,결정된 프레임의 정보에 기초하여 상기 스타일 벡터를 생성하는, 장치. |
| 16 | 삭제 |
| 17 | 제15항에 있어서,상기 프로세서는,상기 참조 음성을 주파수 축 및 시간 축으로 순차적으로 분석하여 상기 참조 음성의 히든 시퀀스(hidden sequence)에 포함된 순차 정보(sequential information)를 획득하는, 장치. |
| 18 | 제15항에 있어서,상기 복수의 SALN 벡터는,상기 음소 시퀀스의 제1 히든 음소 시퀀스에 포함된 복수의 음소 각각을 상기 특징에 따라 발화한 음성에 대응하는 복수의 제1 SALN 벡터; 및상기 제1 히든 음소 시퀀스의 길이가 조절된 제2 히든 음소 시퀀스에 포함된 복수의 음소 각각을 상기 특징에 따라 발화한 음성에 대응하는 복수의 제2 SALN 벡터를 포함하고,상기 프로세서는,상기 음소 시퀀스에 포함된 복수의 음소의 특징 벡터 및 상기 스타일 벡터에 기초하여 상기 복수의 제1 SALN 벡터를 생성하며,상기 제2 히든 음소 시퀀스에 포함된 복수의 음소의 특징 벡터 및 상기 스타일 벡터에 기초하여 상기 복수의 제2 SALN 벡터를 생성하는, 장치. |
| 19 | 제18항에 있어서,상기 각각의 특징 벡터는,상기 복수의 음소를 음소마다 가지는 하나 이상의 특징을 기준으로 다른 음소와 비교함으로써 상기 복수의 음소 간의 상호 관계를 분석하여 획득된 것인, 장치. |
| 20 | 제19항에 있어서,상기 하나 이상의 특징은,높낮음(pitch), 에너지(energy), 및 지속 시간(duration time)을 포함하는 것인, 장치. |