| 번호 | 청구항 |
|---|---|
| 16 | 제15항에 있어서,상기 화자 등록 처리부는,주변 음향 환경에 적응되기 이전의 상기 제1 UBM 모델에 대응하는 제1 모델 파라미터를 상기 제1 특징 벡터에 적응시킴으로써, 상기 제1 화자 GMM 모델에 대응하는 제2 모델 파라미터를 획득하고,상기 제2 모델 파라미터는,혼합 가중치, 평균 벡터, 및 공분산 행렬을 포함하는화자 검증 장치. |
| 17 | 삭제 |
| 18 | 제13항에 있어서,상기 UBM 적응 처리부는,상기 적응 데이터에 포함된 상기 제2 특징 벡터에 대한 제1 GMM 혼합의 사후 확률을 추정하고, 상기 사후 확률에 기초해 충분 통계량을 추정하고, 상기 충분 통계량과 상기 제2 UBM 모델에 대응하는 제1 모델 파라미터를 이용해, 제2 모델 파라미터를 계산하고,상기 제2 모델 파라미터는 주변 음향 환경에 적응된 상기 제1 UBM 모델에 대응하고, 혼합 가중치, 평균 벡터, 및 공분산 행렬을 포함하는화자 검증 장치. |
| 1 | GMM(Gaussian Mixture Model)에 기반한 통계 모델 방식을 이용하는 화자 검증장치의 화자 검증 방법으로서,제1 화자의 제1 입력 음성으로부터 추출된 적어도 하나의 제1 특징 파라미터를 이용해, 상기 제1 화자를 위한 제1 화자 GMM 모델을 생성하는 단계;적어도 하나의 제2 화자의 입력 음성으로부터 추출된 적어도 하나의 제2 특징 파라미터를 이용해, 상기 제1 화자에 대응하는 제1 UBM(Universal Background Model) 모델을 주변 음향 환경에 적응시키는 단계; 및제2 입력 음성으로부터 추출된 적어도 하나의 제3 특징 파라미터에 대한 상기 제1 UBM 모델의 제1 우도(likelihood)와 상기 제3 특징 파라미터에 대한 상기 제1 화자 GMM 모델의 제2 우도를 비교하고, 상기 비교 결과에 기초해 상기 제2 입력 음성이 상기 제1 화자의 음성인지를 판단하는 단계를 포함하고, 상기 제1 UBM 모델을 주변 음향 환경에 적응시키는 단계는,상기 제2 특징 파라미터를 순차적으로 포함하는 적응 데이터를 생성하는 단계;상기 적응 데이터에 포함된 상기 제2 특징 파라미터 중에서 상기 제1 화자에 대응하는 특징 파라미터를 상기 적응 데이터에서 제외하는 단계; 및주변 음향 환경에 적응되기 이전의 상기 제1 UBM 모델인 제2 UBM 모델을, 상기 적응 데이터를 이용해 주변 음향 환경에 적응시키는 단계를 포함하는화자 검증 방법. |
| 2 | 제1항에 있어서,상기 제1 화자 GMM 모델을 생성하는 단계는,상기 제1 입력 음성을 적어도 하나의 제1 프레임으로 분할하는 단계; 및상기 제1 프레임으로부터 상기 제1 특징 파라미터를 추출하는 단계를 포함하는화자 검증 방법. |
| 3 | 제2항에 있어서,상기 제1 특징 파라미터는,MFCCs(Mel Frequency Cepstral Coefficients)를 포함하는화자 검증 방법. |
| 4 | 제3항에 있어서,상기 제1 화자 GMM 모델을 생성하는 단계는,주변 음향 환경에 적응되기 이전의 상기 제1 UBM 모델에 대응하는 제1 모델 파라미터를 상기 제1 특징 파라미터에 적응시킴으로써, 상기 제1 화자 GMM 모델에 대응하는 제2 모델 파라미터를 획득하는 단계를 더 포함하는화자 검증 방법. |
| 5 | 제4항에 있어서,상기 제2 모델 파라미터는혼합(mixture) 가중치, 평균 벡터, 및 공분산 행렬을 포함하는화자 검증 방법. |
| 6 | 제5항에 있어서,상기 제2 모델 파라미터를 획득하는 단계는,상기 제1 특징 파라미터에 대한 제1 GMM 혼합의 사후 확률(posteriori probability)을 추정하는 단계;상기 사후 확률에 기초해, 충분 통계량(sufficient statistics)을 추정하는 단계; 및상기 충분 통계량과 상기 제1 모델 파라미터를 이용해, 상기 제2 모델 파라미터를 계산하는 단계를 포함하는화자 검증 방법. |
| 7 | 제6항에 있어서,상기 제1 화자 GMM 모델을 생성하는 단계는,상기 제1 화자에 대한 정보를 화자 목록에 등록하는 단계를 더 포함하는화자 검증 방법. |
| 8 | 제1항에 있어서,상기 제2 화자의 입력 음성은 상기 제2 화자를 등록하기 위해 입력된 음성 및 상기 제2 화자를 검증하기 위해 입력된 음성 중 적어도 어느 하나인화자 검증 방법. |
| 9 | 제1항에 있어서,상기 적응 데이터를 이용해 적응시키는 단계는,상기 적응 데이터에 포함된 상기 제2 특징 파라미터에 대한 제1 GMM 혼합의 사후 확률을 추정하는 단계;상기 사후 확률에 기초해, 충분 통계량을 추정하는 단계; 및상기 충분 통계량과 상기 제2 UBM 모델에 대응하는 제1 모델 파라미터를 이용해, 제2 모델 파라미터를 계산하는 단계를 포함하고,상기 제2 모델 파라미터는 주변 음향 환경에 적응된 상기 제1 UBM 모델에 대응하는화자 검증 방법. |
| 10 | 제9항에 있어서,상기 제2 모델 파라미터는 혼합 가중치, 평균 벡터, 및 공분산 행렬을 포함하는화자 검증 방법. |
| 11 | 제1항에 있어서,상기 판단하는 단계는,상기 제1 우도와 상기 제2 우도 간의 비율에 대한 로그 값인 로그 우도비(likelihood ratio)를 계산하는 단계; 및상기 로그 우도비와 임계값을 비교해, 상기 제2 입력 음성이 상기 제1 화자의 음성인지를 판단하는 단계를 포함하는화자 검증 방법. |
| 12 | 제11항에 있어서,상기 판단하는 단계는,화자 목록에 포함된 화자 중에서 상기 제1 화자를 선택하는 단계를 더 포함하는화자 검증 방법. |
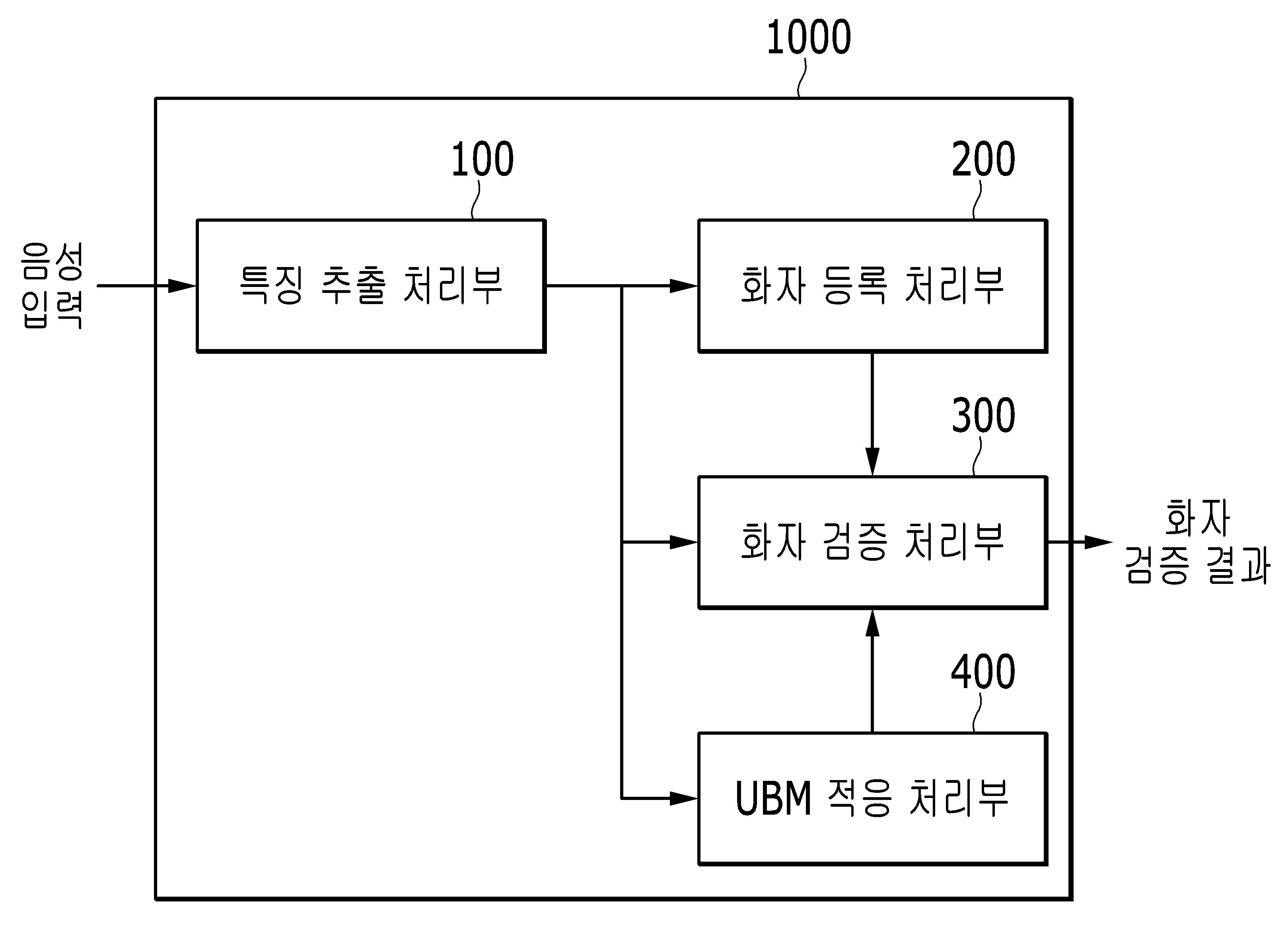
| 13 | GMM에 기반한 통계 모델 방식을 이용해 화자를 검증하는 장치로서, 입력 음성으로부터 적어도 하나의 특징 벡터를 추출하는 특징 추출 처리부;상기 특징 벡터 중 제1 화자에 대응하는 적어도 하나의 제1 특징 벡터를 이용해, 제1 화자 GMM 모델을 생성하는 화자 등록 처리부;상기 특징 벡터 중 적어도 하나의 제2 화자에 대응하는 적어도 하나의 제2 특징 벡터를 이용해, 상기 제1 화자에 대응하는 제1 UBM 모델을 주변 음향 환경에 적응시키는 UBM 적응 처리부; 및상기 특징 벡터 중 화자 검증을 위해 입력된 제1 음성에 대응하는 적어도 하나의 제3 특징 벡터에 대한 상기 제1 UBM 모델의 제1 확률적 유사도와, 상기 제3 특징 벡터에 대한 상기 제1 화자 GMM 모델의 제2 확률적 유사도를 비교하여, 상기 제1 음성이 상기 제1 화자의 음성인지를 판단하는 화자 검증 처리부를 포함하고,상기 UBM 적응 처리부는,상기 제2 특징 벡터를 순차적으로 포함하는 적응 데이터를 생성하고, 상기 적응 데이터에 포함된 상기 제2 특징 벡터 중에서 상기 제1 화자에 대응하는 특징 벡터를 상기 적응 데이터에서 제외하고, 주변 음향 환경에 적응되기 이전의 상기 제1 UBM 모델인 제2 UBM 모델을 상기 적응 데이터를 이용해 주변 음향 환경에 적응시키는 화자 검증 장치. |
| 14 | 제13항에 있어서,상기 화자 등록 처리부는 상기 제1 화자에 대한 정보를 화자 목록에 등록하는화자 검증 장치. |
| 15 | 제14항에 있어서,상기 특징 추출 처리부는,상기 제1 화자의 음성 신호를 적어도 하나의 제1 프레임으로 분할하고, 상기 제1 프레임으로부터 상기 제1 특징 벡터를 추출하고,상기 제1 특징 벡터는 MFCCs를 포함하는화자 검증 장치. |
| 19 | 제14항에 있어서,상기 화자 검증 처리부는,상기 화자 목록에 포함된 화자 중에서 상기 제1 화자를 선택하고, 상기 제1 확률적 유사도와 상기 제2 확률적 유사도 간의 비율에 대한 로그 값인, 로그 우도비를 계산하고, 상기 로그 우도비가 임계값보다 크면 상기 제1 음성을 상기 제1 화자의 음성으로 승인하는 화자 검증 장치. |
| 20 | 삭제 |