| 번호 | 청구항 |
|---|---|
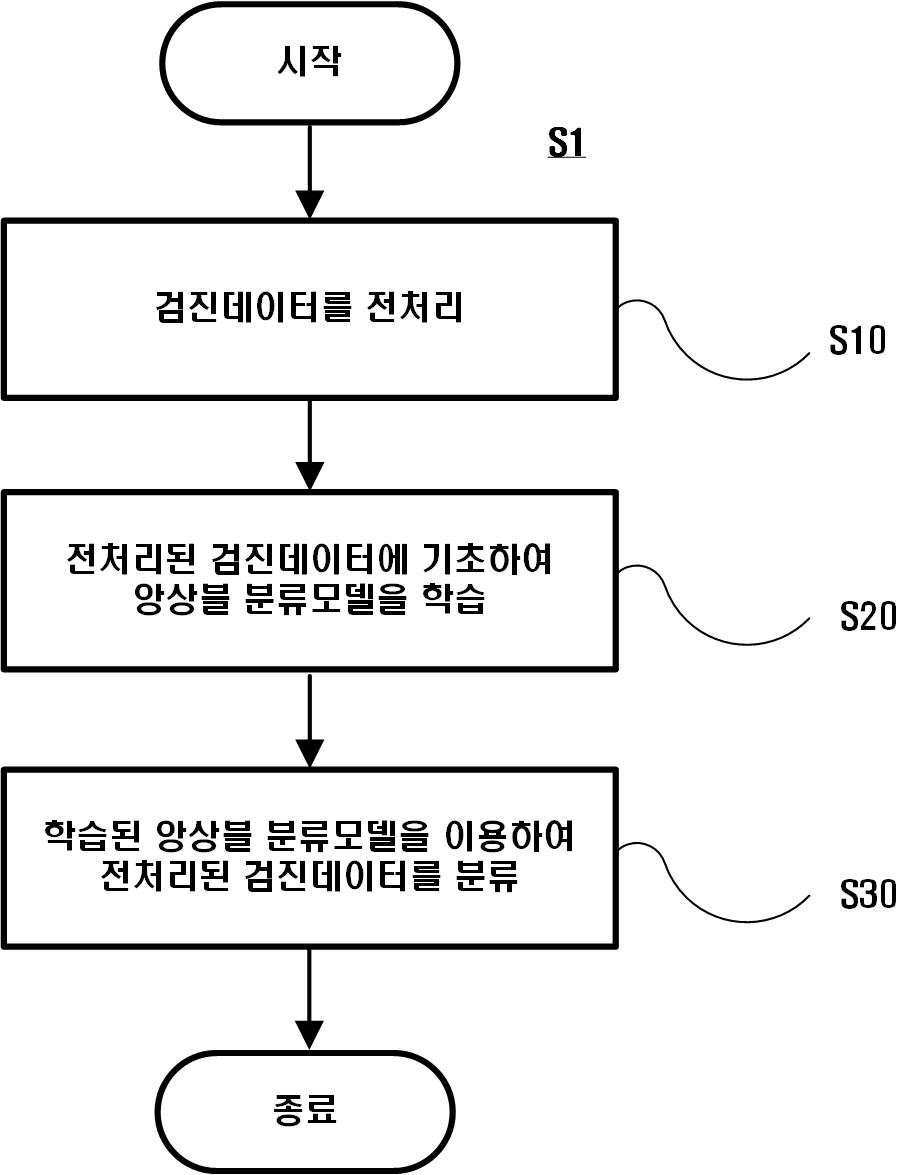
| 1 | 장치에 의해 수행되는 토크나이징 기반의 검진 데이터 분석 방법에 있어서,상기 장치의 데이터베이스부에 저장된 검진 데이터 또는 상기 장치의 통신부를 통해 외부 서버로부터 검진 데이터를 수신하는 단계;상기 장치의 제어부에 의해, 상기 검진 데이터를 전처리하는 단계;상기 제어부에 의해, 상기 전처리된 검진 데이터를 기반으로 앙상블 분류 모델을 생성하는 단계; 및상기 제어부에 의해, 상기 앙상블 분류 모델을 기반으로 상기 검진 데이터의 분류 결과를 획득하는 단계를 포함하되,상기 검진 데이터는, 복수의 진단명 각각에 대해 산출되며, 토크나이징(tokenizing)을 통해 산출되는 토큰(token)의 최대 및 평균의 개수가 기 설정된 각각의 기준 개수보다 큰 텍스트 데이터를 포함하고,상기 전처리하는 단계는,상기 제어부에 의해, 상기 텍스트 데이터에서 상기 복수의 진단명 각각에 대응되는 키워드를 검색하며,상기 제어부에 의해, 상기 검색된 키워드를 기반으로, 상기 토큰의 개수가 상기 기준 개수 이하인 문장을 추출하고,상기 제어부에 의해, 상기 추출된 문장을 기반으로 상기 전처리를 수행하는 것을 특징으로 하는, 방법. |
| 2 | 제1항에 있어서,상기 생성하는 단계는,상기 제어부에 의해, 상기 전처리된 검진 데이터에 대한 고정 임베딩(Static Embedding) 및 문맥화 임베딩(Contextualized Embedding)을 수행하고,상기 제어부에 의해, 상기 고정 임베딩 및 상기 문맥화 임베딩이 수행된 결과 데이터를 기반으로 상기 앙상블 분류 모델을 생성하는 것을 특징으로 하는, 방법. |
| 3 | 제2항에 있어서,상기 생성하는 단계는,상기 제어부에 의해, 상기 고정 임베딩이 수행된 결과 데이터를 기반으로 하는 학습을 통해 적어도 하나의 제1 분류 모델을 생성하는 단계;상기 제어부에 의해, 상기 문맥화 임베딩이 수행된 결과 데이터를 기반으로 하는 학습을 통해 적어도 하나의 제2 분류 모델을 생성하는 단계; 및상기 제어부에 의해, 상기 제1 분류 모델 및 상기 제2 분류 모델을 기반으로 상기 앙상블 분류 모델을 생성하는 것을 특징으로 하는, 방법. |
| 4 | 제1항에 있어서,상기 전처리하는 단계는,상기 제어부에 의해, 상기 검진 데이터에서 기 설정된 기준 특수 문자를 제외한 나머지 특수 문자를 삭제하는 단계;상기 제어부에 의해, 상기 특수 문자가 삭제된 검진 데이터의 띄어 쓰기 규칙을 기 설정된 기준 문법을 기반으로 균일화하는 단계;상기 제어부에 의해, 상기 균일화된 검진 데이터를 수치화하는 단계; 및상기 제어부에 의해, 상기 수치화된 검진 데이터를 패딩(padding)하는 단계를 포함하는, 방법. |
| 5 | 제4항에 있어서,상기 수치화하는 단계는,상기 제어부에 의해, 상기 균일화된 검진 데이터를 토크나이징(tokenizing)하고,상기 제어부에 의해, 상기 토크나이징을 통해 생성된 토큰(token)의 개수를 카운팅하며,상기 제어부에 의해, 상기 토큰의 개수를 기반으로 상기 균일화된 검진 데이터를 수치화하는 것을 특징으로 하는, 방법. |
| 6 | 제4항에 있어서,상기 수치화하는 단계는,상기 제어부에 의해, 상기 복수의 그룹 중 데이터의 양이 가장 작은 최소 그룹의 데이터의 양을 증식시키되,상기 제어부에 의해, 상기 최소 그룹에 포함된 데이터를 문장 단위로 분할하여 복수의 문장을 생성하고,상기 제어부에 의해, 상기 복수의 문장끼리 서로 연결하여 상기 최소 그룹의 데이터의 양을 증식시키는 것을 특징으로 하는, 방법. |
| 7 | 제1항에 있어서,상기 기준 개수는, 기 획득된 코퍼스셋에 포함된 코퍼스의 토큰의 최대 개수에 대응되는 것을 특징으로 하는, 방법. |
| 8 | 제1항에 있어서,상기 검진 데이터는 수치 검사 결과를 포함하고,상기 수치 검사 결과는, 상기 복수의 진단명 각각과 대응되어 기 설정된 정형화된 데이터인 것을 특징으로 하는, 방법. |
| 9 | 컴퓨터와 결합되어, 제1항 내지 제8항 중 어느 한 항의 방법을 실행시키기 위한 프로그램이 저장된 컴퓨터 판독 가능한 기록 매체. |
| 10 | 통신부;데이터베이스부; 및상기 데이터베이스부에 저장된 검진 데이터 또는 상기 통신부를 통해 외부 서버로부터 수신된 검진 데이터를 기 설정된 복수의 소견으로 분류하는 제어부를 포함하고,상기 제어부는,상기 검진 데이터를 전처리하고,상기 전처리된 검진 데이터를 기반으로 앙상블 분류 모델을 생성하며,상기 앙상블 분류 모델을 기반으로 상기 검진 데이터의 분류 결과를 획득하되,상기 검진 데이터는, 복수의 진단명 각각에 대해 산출되며, 토크나이징(tokenizing)을 통해 산출되는 토큰(token)의 최대 및 평균의 개수가 기 설정된 각각의 기준 개수보다 큰 텍스트 데이터를 포함하고,상기 검진 데이터를 전처리할 때,상기 텍스트 데이터에서 상기 복수의 진단명 각각에 대응되는 키워드를 검색하며, 상기 검색된 키워드를 기반으로, 상기 토큰의 개수가 상기 기준 개수 이하인 문장을 추출하고,상기 추출된 문장을 기반으로 상기 전처리를 수행하는 것을 특징으로 하는, 토크나이징 기반의 검진 데이터 분석 장치. |