| 번호 | 청구항 |
|---|---|
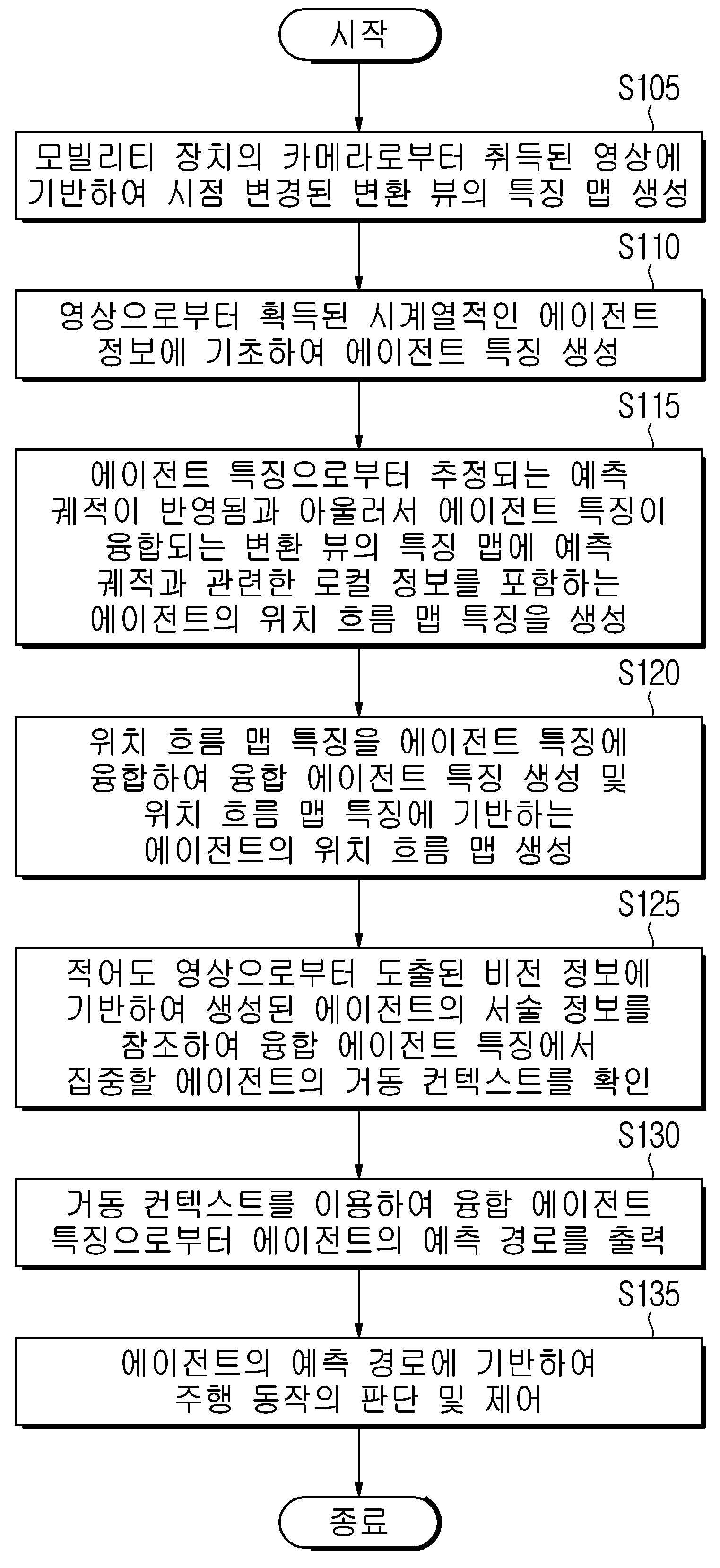
| 1 | 자율 주행을 위한 에이전트의 거동 예측 방법에 있어서, 모빌리티 장치의 센서로부터 취득된 영상에 기반하여, 시점 변경된 변환 뷰의 특징(feature) 맵 및 에이전트 특징을 생성하는 단계;상기 에이전트 특징으로부터 추정되는 예측 궤적(trajectory)을 반영함과 아울러서 상기 에이전트 특징을 융합시킨(fuse) 상기 변환 뷰의 특징 맵에 상기 예측 궤적과 관련한 로컬 정보를 포함하는 에이전트의 위치 흐름 맵(occupancy flow map) 특징을 생성하는 단계; 및 상기 영상과 관련하여 도출된 상기 에이전트의 서술(descriptive) 정보에 의해 집중되는 상기 에이전트의 거동 컨텍스트(behavioral context)를 기초로, 상기 위치 흐름 맵 특징을 상기 에이전트 특징에 융합한 융합 에이전트 특징으로부터 상기 에이전트의 예측 경로를 출력하는 단계를 포함하는, 에이전트의 거동 예측 방법. |
| 2 | 제 1 항에 있어서, 상기 위치 흐름 맵 특징을 생성하는 단계는, 상기 에이전트의 상기 예측 궤적을 상기 특징 맵에 제시하도록(represent), 상기 예측 궤적을 갖는 상기 변환 뷰의 특징 맵 및 상기 에이전트 특징을 이용하는 크로스 어텐션(Cross Attention)에 의해, 상기 특징 맵에 상기 에이전트 특징을 융합하는 단계; 상기 특징 맵에서 상기 예측 궤적에 기반하는 로컬 영역을 추출하여 상기 로컬 영역과 관련된 로컬 정보를 생성하는 단계; 및 상기 에이전트 특징이 융합된 상기 특징 맵 및 상기 로컬 정보를 포함하는 위치 흐름 맵 특징을 제공하는 단계를 포함하는, 에이전트의 거동 예측 방법. |
| 3 | 제 2 항에 있어서, 상기 로컬 정보를 생성하는 단계는, 상기 특징 맵으로부터 상기 예측 궤적이 차지하는 점유 영역을 추출하는 단계; 상기 특징 맵에 기반하는 셀프 어텐션(Self Attention)에 의해, 상기 점유 영역 간의 전역적인 인터랙션을 식별하여 상기 에이전트의 궤적을 예측하는 단계; 및 상기 셀프 어텐션이 처리된 상기 특징 맵에 합성곱 신경망(Convolution Neural Network; CNN)을 적용하여, 상기 예측된 궤적과 관련된 상기 로컬 영역의 특징을 포함하는 로컬 정보를 생성하는 단계를 포함하는, 에이전트의 거동 예측 방법. |
| 4 | 제 1 항에 있어서, 상기 융합 에이전트 특징은 상기 위치 흐름 맵 특징 및 상기 에이전트 특징을 이용하는 디포머블 크로스 어텐션(Deformable Cross Attention)에 의해 생성되는, 에이전트의 거동 예측 방법. |
| 5 | 제 1 항에 있어서, 상기 변환 뷰의 특징 맵에 융합되는 상기 에이전트 특징은 상기 에이전트 간의 인터랙션을 반영하도록 가공되는 에이전트 특징인, 에이전트의 거동 예측 방법. |
| 6 | 제 1 항에 있어서, 상기 에이전트의 예측 경로를 출력하는 단계 전에, 영상 언어 변환 모델에 의해, 상기 영상에서 상황을 표현하는 비전(vision) 정보에 기초하여, 상기 에이전트의 예측 궤적 및 상기 에이전트의 상황을 텍스트로 기술하는 텍스트 데이터를 생성하는 단계; 상기 텍스트 데이터를 인코딩하는 단계; 및 공통 임베딩 공간(common embedding space)에서 처리되며 상기 인코딩된 텍스트 데이터 및 상기 에이전트 특징을 이용하는 대조 학습 모델에 의해, 상기 에이전트 특징에 부합하는 상기 예측 궤적 및 상기 상황을 포함하는 상기 거동 컨텍스트를 텍스트로 표현하는 상기 에이전트의 서술 정보를 생성하는 단계를 더 포함하는, 에이전트의 거동 예측 방법. |
| 7 | 제 6 항에 있어서, 상기 텍스트 데이터를 생성하는 단계는, 상기 영상 언어 변환 모델에 의해, 상기 비전 정보에 기초하여 상기 텍스트 데이터를 생성하는 단계; 및 언어 정제 모델에 의해, 상기 비전 정보에 기반하여 상기 텍스트 데이터를 정제하는 단계를 포함하는, 에이전트의 거동 예측 방법. |
| 8 | 제 6 항에 있어서, 상기 거동 예측 방법을 구현하는 학습 모델은 상기 에이전트의 상황을 서술하는 텍스트 데이터와 상기 에이전트의 상황 특징 간의 유사도에 따른 손실, 상기 에이전트 특징이 융합된 상기 변환 뷰의 특징 맵에서의 상기 에이전트의 궤적에 따른 손실 및 상기 에이전트의 예측 경로에 따른 손실을 포함하는 손실 함수를 이용하여 학습되는, 에이전트의 거동 예측 방법. |
| 9 | 제 1 항에 있어서, 상기 변환 뷰는 조감도(bird's eye view) 이고, 상기 에이전트 특징은 상기 영상으로부터 획득되는 멀티 모달(multi-modal) 데이터를 갖는 에이전트 정보에 기초하여 생성되며, 상기 멀티 모달 데이터는 이종의 데이터이며, 상기 에이전트 특징은 상기 멀티 모달 데이터를 각각 학습하여 결합된 연결 데이터에 기반하는 트랜스포머(Transformer) 모델에 의해 생성되는, 에이전트의 거동 예측 방법. |
| 10 | 제 9 항에 있어서, 상기 멀티 모달 데이터는 상기 에이전트의 시계열적인 궤적, 상기 에이전트의 유형 및 상기 모빌리티 장치 관점에서의 거리 및 헤딩(heading) 변위를 포함하는 상기 에이전트의 시간적인(temporal) 변화 데이터를 포함하는, 에이전트의 거동 예측 방법. |
| 11 | 자율 주행을 위해 에이전트의 거동을 예측하는 모빌리티 장치에 있어서, 상기 모빌리티 장치의 주변 환경을 검출하는 센서; 적어도 하나의 인스트럭션을 저장하는 메모리; 및 상기 메모리에 저장된 상기 적어도 하나의 인스트럭션을 실행하는 프로세서를 포함하고,상기 프로세서는,상기 센서로부터 취득된 영상에 기반하여, 시점 변경된 변환 뷰의 특징 맵 및 에이전트 특징을 생성하고, 상기 에이전트 특징으로부터 추정되는 예측 궤적을 반영함과 아울러서 상기 에이전트 특징을 융합시킨 상기 변환 뷰의 특징 맵에 상기 예측 궤적과 관련한 로컬 정보를 포함하는 에이전트의 위치 흐름 맵 특징을 생성하고, 상기 영상과 관련하여 도출된 상기 에이전트의 서술 정보에 의해 집중되는 상기 에이전트의 거동 컨텍스트를 기초로, 상기 위치 흐름 맵 특징을 상기 에이전트 특징에 융합한 융합 에이전트 특징으로부터 상기 에이전트의 예측 경로를 출력하도록 구성되는, 모빌리티 장치. |
| 12 | 제 11 항에 있어서, 상기 위치 흐름 맵 특징의 생성은, 상기 에이전트의 상기 예측 궤적을 상기 특징 맵에 제시하도록, 상기 예측 궤적을 갖는 상기 변환 뷰의 특징 맵 및 상기 에이전트 특징을 이용하는 크로스 어텐션에 의해, 상기 특징 맵에 상기 에이전트 특징을 융합하고, 상기 특징 맵에서 상기 예측 궤적에 기반하는 로컬 영역을 추출하여 상기 로컬 영역과 관련된 로컬 정보를 생성하고, 상기 에이전트 특징이 융합된 상기 특징 맵 및 상기 로컬 정보를 포함하는 위치 흐름 맵 특징을 제공하는 것을 포함하는, 모빌리티 장치. |
| 13 | 제 12 항에 있어서, 상기 로컬 정보의 생성은, 상기 특징 맵으로부터 상기 예측 궤적이 차지하는 점유 영역을 추출하고, 상기 특징 맵에 기반하는 셀프 어텐션에 의해, 상기 점유 영역 간의 전역적인 인터랙션을 식별하여 상기 에이전트의 궤적을 예측하고, 상기 셀프 어텐션이 처리된 상기 특징 맵에 합성곱 신경망을 적용하여, 상기 예측된 궤적과 관련된 상기 로컬 영역의 특징을 포함하는 로컬 정보를 생성하는 것을 포함하는, 모빌리티 장치. |
| 14 | 제 11 항에 있어서, 상기 융합 에이전트 특징은 상기 위치 흐름 맵 특징 및 상기 에이전트 특징을 이용하는 디포머블 크로스 어텐션에 의해 생성되는, 모빌리티 장치. |
| 15 | 제 11 항에 있어서, 상기 변환 뷰의 특징 맵에 융합되는 상기 에이전트 특징은 상기 에이전트 간의 인터랙션을 반영하도록 가공되는 에이전트 특징인, 모빌리티 장치. |
| 16 | 제 11 항에 있어서, 상기 에이전트의 예측 경로의 출력 전에, 상기 프로세서는. 영상 언어 변환 모델에 의해, 상기 영상에서 상황을 표현하는 비전 정보에 기초하여, 상기 에이전트의 예측 궤적 및 상기 에이전트의 상황을 텍스트로 기술하는 텍스트 데이터를 생성하고, ; 상기 텍스트 데이터를 인코딩하고, 공통 임베딩 공간에서 처리되며 상기 인코딩된 텍스트 데이터 및 상기 에이전트 특징을 이용하는 대조 학습 모델에 의해, 상기 에이전트 특징에 부합하는 상기 예측 궤적 및 상기 상황을 포함하는 상기 거동 컨텍스트를 텍스트로 표현하는 상기 에이전트의 서술 정보를 생성하는 것을 더 포함하도록 구성되는, 모빌리티 장치. |
| 17 | 제 16 항에 있어서, 상기 텍스트 데이터의 생성은, 상기 영상 언어 변환 모델에 의해, 상기 비전 정보에 기초하여 상기 텍스트 데이터를 생성하고,언어 정제 모델에 의해, 상기 비전 정보에 기반하여 상기 텍스트 데이터를 정제하는 것을 포함하는, 모빌리티 장치. |
| 18 | 제 16 항에 있어서, 상기 에이전트의 거동을 예측하기 위한 학습 모델은 상기 에이전트의 상황을 서술하는 텍스트 데이터와 상기 에이전트의 상황 특징 간의 유사도에 따른 손실, 상기 에이전트 특징이 융합된 상기 변환 뷰의 특징 맵에서의 상기 에이전트의 궤적에 따른 손실 및 상기 에이전트의 예측 경로에 따른 손실을 포함하는 손실 함수를 이용하여 학습되는, 모빌리티 장치. |
| 19 | 제 11 항에 있어서, 상기 변환 뷰는 조감도이고, 상기 에이전트 특징은 상기 영상으로부터 획득되는 멀티 모달 데이터를 갖는 에이전트 정보에 기초하여 생성되며, 상기 멀티 모달 데이터는 이종의 데이터이며, 상기 에이전트 특징은 상기 멀티 모달 데이터를 각각 학습하여 결합된 연결 데이터에 기반하는 트랜스포머 모델에 의해 생성되는, 모빌리티 장치. |
| 20 | 제 19 항에 있어서, 상기 멀티 모달 데이터는 상기 에이전트의 시계열적인 궤적, 상기 에이전트의 유형 및 상기 모빌리티 장치 관점에서의 거리 및 헤딩 변위를 포함하는 상기 에이전트의 시간적인 변화 데이터를 포함하는, 모빌리티 장치. |