(주)디블렌트
차량 내 신경망을 이용한 수어 응답 제공 방법, 장치 및 컴퓨터 프로그램
Method, device and computer program for providing sign language response using neural network in avehicle
특허 요약
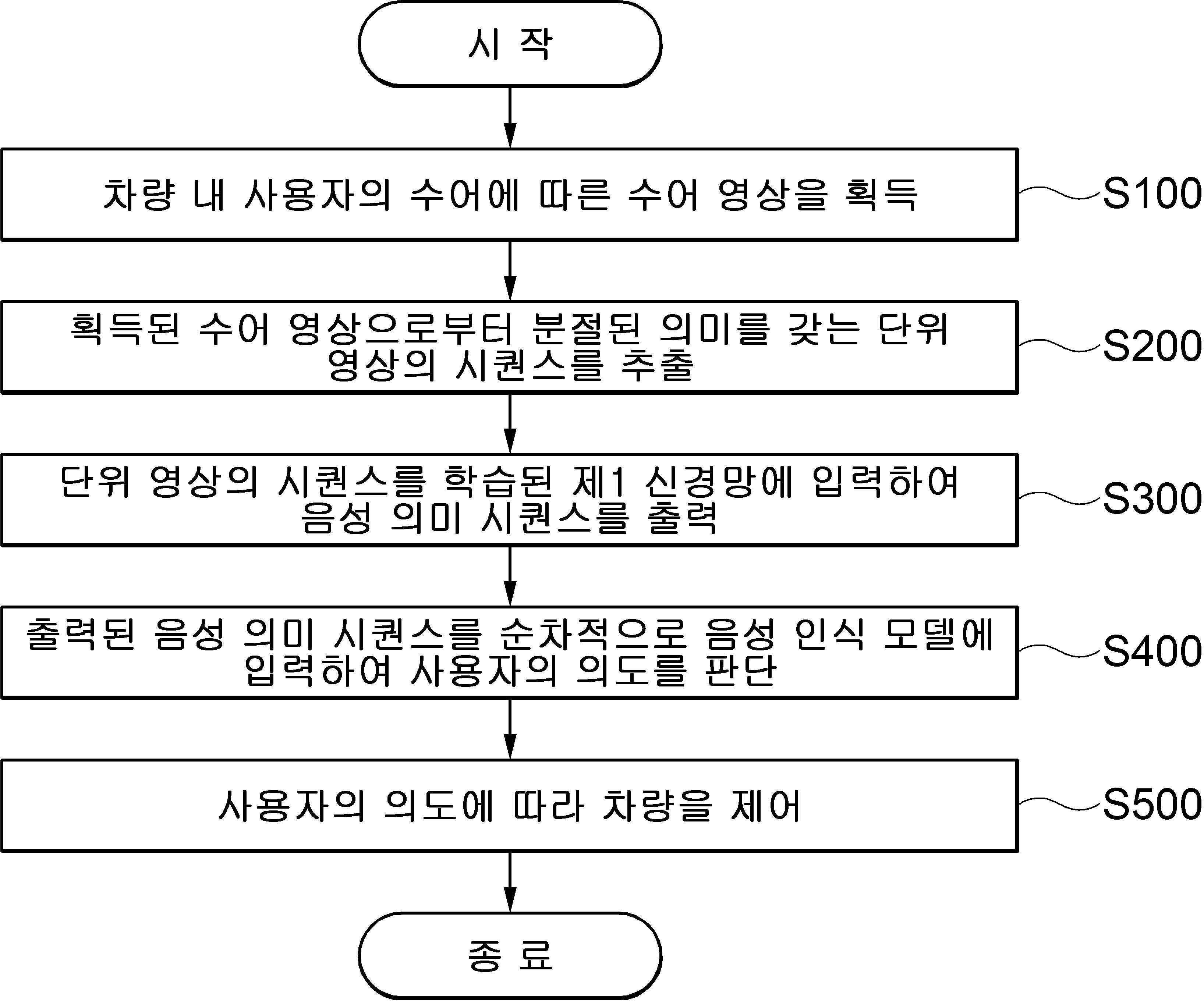
신경망을 이용한 차량의 수어 응답 제공 방법은 차량 내 사용자의 수어에 따른 수어 영상을 획득하는 단계, 획득된 수어 영상으로부터 분절된 의미를 갖는 단위 영상의 시퀀스를 추출하는 단계, 단위 영상의 시퀀스를 학습된 제1 신경망에 입력하여 음성 의미 시퀀스를 출력하는 단계, 출력된 음성 의미 시퀀스를 순차적으로 음성 인식 모델에 입력하여 사용자의 의도를 판단하는 단계 및 사용자의 의도에 따라 차량을 제어하는 단계를 포함할 수 있다.
청구항
| 번호 | 청구항 |
|---|---|
| 1 | 신경망을 이용한 차량의 수어 응답 제공 방법에 있어서, 차량 내 사용자의 수어에 따른 수어 영상을 획득하는 단계;상기 획득된 수어 영상으로부터 분절된 의미를 갖는 단위 영상의 시퀀스를 추출하는 단계;상기 단위 영상의 시퀀스를 학습된 제1 신경망에 입력하여 음성 의미 시퀀스를 출력하는 단계;출력된 음성 의미 시퀀스를 순차적으로 음성 인식 모델에 입력하여 사용자의 의도를 판단하는 단계; 및상기 사용자의 의도에 따라 차량을 제어하는 단계;를 포함하고,상기 제1 신경망 모델은,상기 제1 신경망 모델으로부터 출력된 실제 음성 의미 시퀀스와, 상기 실제 음성 의미 시퀀스를 입력으로 제2 신경망 모델을 통해 출력된 가상 단위 영상 시퀀스를 제1 신경망 모델의 입력으로 출력된 가상 음성 의미 시퀀스 간의 차이를 통해 학습되며,상기 제1 신경망 모델은 컨볼루션 레이어로 구성된 인코더(encoder)를 통해 상기 단위 영상에서 상기 음성 의미를 정의하는 특징 벡터를 출력하도록 학습되며,상기 제2 신경망 모델은 디컨볼루션 레이어로 구성된 디코더(decoder)를 통해 상기 음성 의미에 대한 특징 벡터로부터 단위 영상을 생성하여 출력하도록 학습되는 것을 특징으로 하는 수어 응답 제공 방법. |