| 번호 | 청구항 |
|---|---|
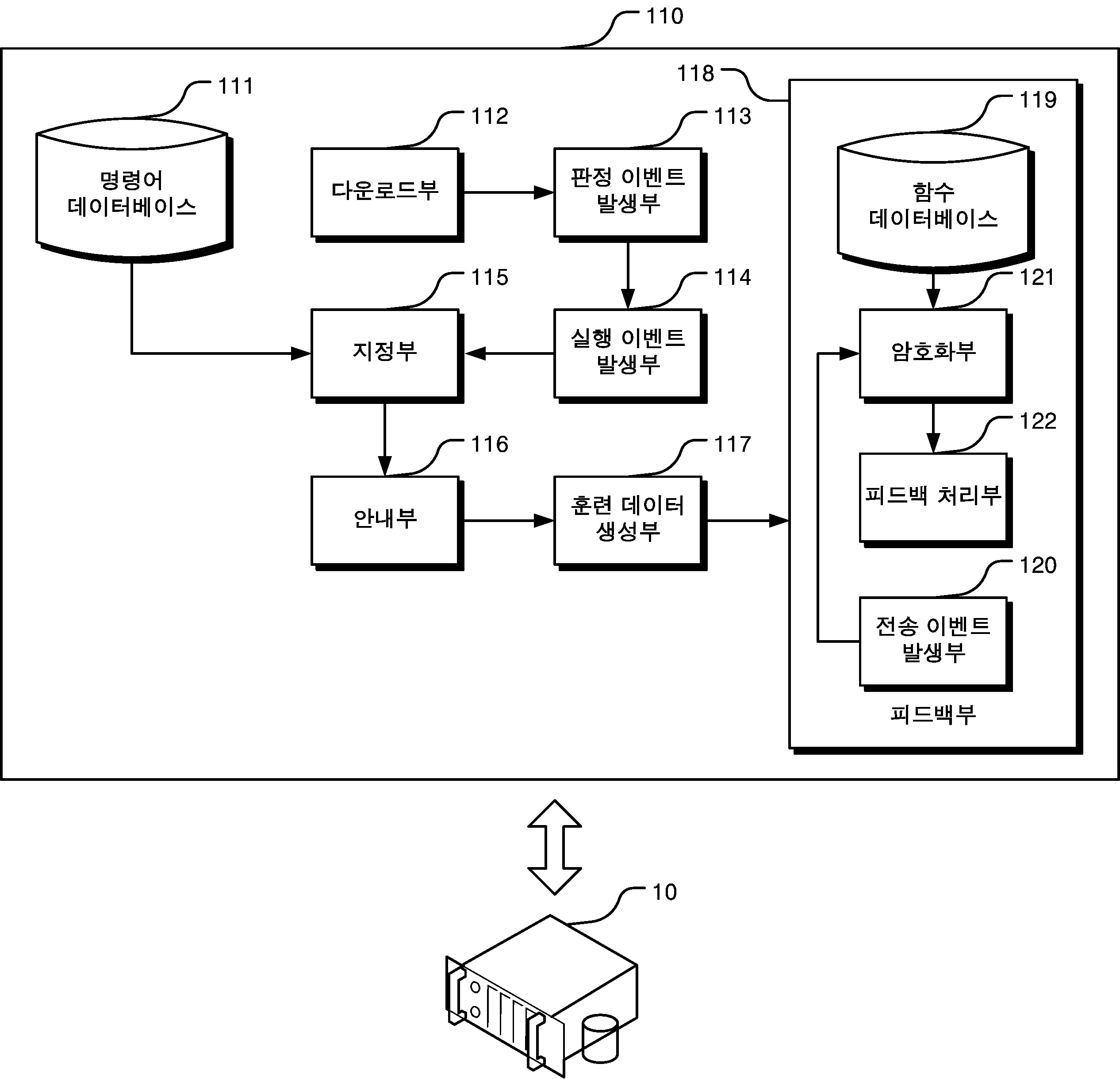
| 1 | 사용자의 액션 명령어 실행 이력을 분석하여 다음 액션 명령어를 추천하는 인공지능 기반의 추천 기능을 제공할 수 있는 컴퓨팅 장치에 있어서,사전 설정된 복수의 액션 명령어들 - 상기 복수의 액션 명령어들 각각은, 상기 컴퓨팅 장치에서 실행 가능한 것으로 지정된 액션을 호출하기 위한 명령어를 의미함 - 과 상기 복수의 액션 명령어들 각각에 대응되는 사전 설정된 임베딩 벡터가 저장되어 있는 명령어 데이터베이스;상기 컴퓨팅 장치의 사용자로부터, 액션 명령어 추천 기능의 활성화 명령이 인가되면, 사전 설정된 모델 관리 시스템 서버로부터 명령어 추천 모델 - 상기 명령어 추천 모델은, 상기 복수의 액션 명령어들 중 상기 컴퓨팅 장치 상에서 순차적으로 실행된 k(k는 2이상의 자연수임)개의 액션 명령어들로 구성된 명령어셋이 입력으로 인가되면, 상기 복수의 액션 명령어들 중, 입력으로 인가된 명령어셋에 대응되는 다음 액션 명령어를 선별하도록 사전 기계학습된 인공지능 모델임 - 에 대한 데이터를 다운로드하는 다운로드부;상기 명령어 추천 모델에 대한 데이터가 다운로드되면, 상기 컴퓨팅 장치에서, 상기 사용자에 의해서 실행된 액션 명령어들의 누적 개수가 k개가 될 때마다, 액션 명령어 추천 기능을 실행할지 여부를 판정하기 위한 판정 이벤트를 발생시키는 판정 이벤트 발생부;어느 한 시점에서 상기 판정 이벤트 발생부를 통해, 판정 이벤트가 발생되면, 판정 이벤트가 발생한 시점부터 사전 설정된 대기 시간 내에, 상기 컴퓨팅 장치에서 상기 사용자에 의한 추가 액션 명령어가 실행되는지 확인하여, 실행되지 않는 것으로 확인되면, 상기 판정 이벤트 발생부를 통한 판정 이벤트의 발생이 중단되도록 처리한 후, 액션 명령어 추천 기능을 실행하기 위한 실행 이벤트를 발생시키는 실행 이벤트 발생부;상기 실행 이벤트 발생부를 통해, 실행 이벤트가 발생되면, 이전 판정 이벤트가 발생된 시점부터 당해 판정 이벤트가 발생된 시점까지, 상기 컴퓨팅 장치 상에서 누적해서 실행된 k개의 제1 액션 명령어들을 확인하고, 상기 제1 액션 명령어들을, 그 실행 순서에 따라 정렬하여 제1 명령어셋으로 구성한 다음, 상기 제1 명령어셋을 상기 명령어 추천 모델에 입력으로 인가함으로써, 상기 명령어 추천 모델을 통해, 상기 복수의 액션 명령어들 중 어느 하나의 액션 명령어가 선별되도록 처리한 후, 상기 명령어 추천 모델을 통해, 어느 하나의 액션 명령어가 선별되면, 선별된 액션 명령어를 추천 액션 명령어로 지정하는 지정부;상기 추천 액션 명령어를, 상기 제1 액션 명령어들에 대응되는 다음 액션 명령어로 추천함을 안내하는 안내 메시지를 생성하여 화면 상에 표시한 후, 상기 판정 이벤트 발생부를 통한 판정 이벤트의 발생이 재개되도록 처리하는 안내부;상기 안내 메시지가 화면 상에 표시된 이후, 상기 사용자에 의해 상기 컴퓨팅 장치에서 신규 액션 명령어가 실행되면, 상기 신규 액션 명령어가 상기 추천 액션 명령어와 동일한지 비교하여, 동일하지 않은 것으로 판단되면, 상기 제1 명령어셋과 함께, 상기 신규 액션 명령어가 상기 제1 명령어셋에 대응되는 정답 데이터로서 포함된 훈련 데이터셋을 생성하는 훈련 데이터 생성부; 및상기 훈련 데이터셋이 생성되면, 상기 훈련 데이터셋을 상기 모델 관리 시스템 서버로 전송하는 피드백부를 포함하고,상기 명령어 추천 모델은 사전 설정된 복수의 훈련용 명령어셋들 - 상기 복수의 훈련용 명령어셋들 각각은, 상기 복수의 액션 명령어들 중에서 선택된 k개의 액션 명령어들을 순차적으로 정렬하여 구성한 셋임 - 과, 각 훈련용 명령어셋에 대응되는 어느 하나의 액션 명령어를 지시하는 정답 레이블을 기초로, 트랜스포머(Transformer)를 학습시켜 만든 모델로서, 상기 트랜스포머에 대한 학습은, 상기 복수의 훈련용 명령어셋들 각각에 대한 임베딩 입력 - 상기 복수의 훈련용 명령어셋들 각각에 대한 임베딩 입력은, 각 훈련용 명령어셋을 구성하는 k개의 액션 명령어들 각각의 정렬 순서와 각 액션 명령어에 대한 임베딩 벡터를 기반으로 포지셔널 인코딩(Position Encoding)이 수행됨에 따라 생성된 임베딩 입력임 - 을 상기 트랜스포머에 통과시켜 예측치를 산출하였을 때, 각 훈련용 명령어셋에 대응되는 예측치와 각 훈련용 명령어셋에 대응되는 정답 레이블 간의 오차가 최소가 되도록 수행된 것임을 특징으로 하는 컴퓨팅 장치. |