| 번호 | 청구항 |
|---|---|
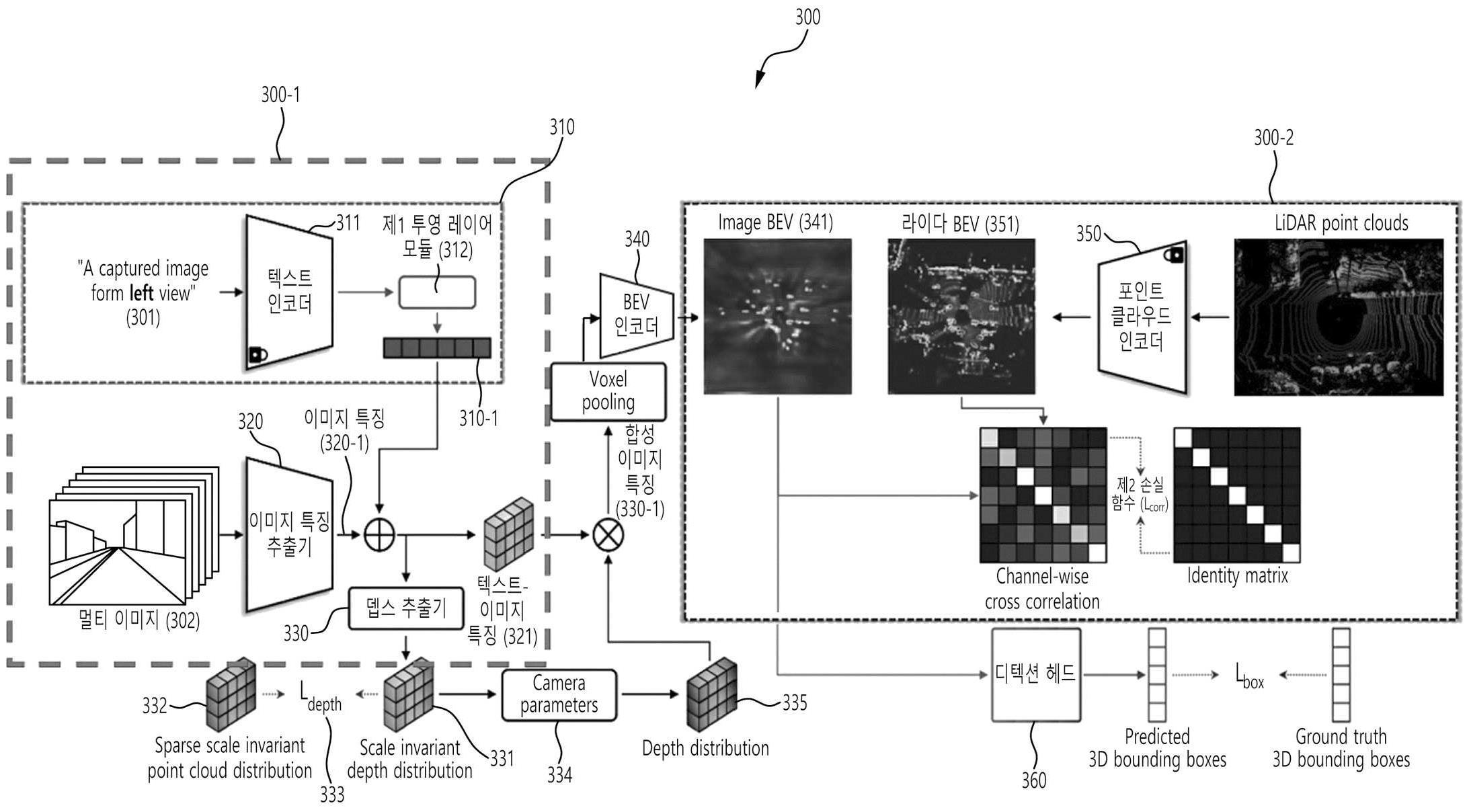
| 1 | 사전 학습된(pre-trained) 텍스트-가이드 모델 및 이미지 특징 추출기를 이용하는 텍스트-가이드 학습 동작;BEV 인코더 및 포인트 클라우드 인코더를 이용하는 라이다-가이드 학습 동작; 및상기 텍스트-가이드 학습 결과 및 상기 라이다-가이드 학습 결과에 기초하여, 객체 인식 모델을 학습하는 동작을 포함하고,상기 텍스트-가이드 학습 동작은하나 이상의 텍스트 입력 및 상기 하나 이상의 텍스트 입력에 대응하는 하나 이상의 이미지 입력을 수신하는 동작; 및상기 텍스트-가이드 모델 및 이미지 특징 추출기를 이용하여, 상기 객체 인식 모델의 학습에 사용되는 하나 이상의 텍스트-이미지 특징을 출력하는 동작을 포함하는, 객체 인식 모델의 학습 방법. |
| 2 | 제1항에 있어서,상기 하나 이상의 텍스트-이미지 특징을 출력하는 동작은상기 하나 이상의 텍스트 입력에 대해 상기 텍스트-가이드 모델에 포함된 텍스트 인코더 및 제1 투영 레이어 모듈을 통해 의미론적(semantic) 정보 인코딩을 수행하여, 하나 이상의 카메라 변형(camera-variant) 정보를 출력하는 동작; 및상기 하나 이상의 카메라 변형 정보와 상기 이미지 특징 추출기에서 추출된 하나 이상의 이미지 특징을 더하여, 상기 텍스트-이미지 특징을 생성하는 동작을 포함하는, 객체 인식 모델 학습 방법. |
| 3 | 제1항에 있어서,상기 라이다-가이드 학습 동작은상기 포인트 클라우드 인코더로부터 획득한 라이다 BEV들과 상기 BEV 인코더에 기초하여 생성된 이미지 BEV들을 대조 학습하는 동작을 포함하는, 객체 인식 모델 학습 방법. |
| 4 | 제3항에 있어서,상기 대조 학습하는 동작은상기 라이다 BEV와 상기 이미지 BEV에 대한 교차 상관 관계를 제2 손실 함수에 기초하여 학습하는 동작을 포함하는, 객체 인식 모델 학습 방법. |
| 5 | 제3항에 있어서,상기 객체 인식 모델을 학습하는 동작은상기 하나 이상의 텍스트-이미지 특징 또는 상기 대조 학습 결과에 기초하여, 상기 이미지 특징 추출기, 뎁스 추출기, 상기 BEV 인코더, 디텍션 헤드 중 적어도 하나를 업데이트하는 동작을 포함하는, 객체 인식 모델 학습 방법. |
| 6 | 제5항에 있어서,상기 뎁스 추출기는상기 하나 이상의 텍스트-이미지 특징에 기초하여 제1 뎁스 정보를 생성하고,상기 제1 뎁스 정보, 뎁스 추출 포인트 클라우드로부터 생성된 제2 뎁스 정보 및 뎁스 손실 함수에 기초하여 업데이트되는, 객체 인식 모델 학습 방법. |
| 7 | 제6항에 있어서,상기 BEV 인코더는상기 뎁스 추출기를 이용하여 추출된 뎁스 특징 및 상기 텍스트-이미지 특징에 기초하여 생성된 합성 이미지 특징에 기초하여, 상기 이미지 BEV를 생성하는, 객체 인식 모델 학습 방법. |
| 8 | 제1항에 있어서,상기 사전 학습된 텍스트-가이드 모델은텍스트 인코더, 제2 투영 레이어 모듈 및 이미지 인코더를 활용하여, 상기 제2 투영 레이어 모듈을 제1 투영 레이어 모듈로 업데이트하는 텍스트-가이드 모델 학습 방법에 의해 획득되는, 객체 인식 모델 학습 방법. |
| 9 | 제8항에 있어서,상기 텍스트-가이드 모델 학습 방법은학습용 텍스트 입력 및 학습용 이미지 입력을 수신하고,상기 학습용 텍스트 입력에서 상기 텍스트 인코더 및 상기 제2 투영 레이어 모듈을 이용하여 학습용 텍스트 특징-학습용 카메라 변형 정보를 포함함-을 추출하여, 공유 임베딩 공간에 투영하고,상기 학습용 이미지 입력에서 상기 이미지 인코더를 이용하여 학습용 이미지 특징을 추출하여, 상기 공유 임베딩 공간에 투영하고,미리 결정된 방법을 이용하여, 상기 제2 투영 레이어 모듈을 제1 투영 레이어 모듈로 업데이트하는 방법인, 객체 인식 모델 학습 방법. |
| 10 | 제9항에 있어서,상기 미리 결정된 방법은상기 학습용 텍스트 특징과 상기 학습용 이미지 특징을 상기 공유 임베딩 공간에서 대조 정렬 학습하고,상기 대조 정렬 학습 결과 및 제1 손실 함수를 이용하여, 상기 제2 투영 레이어 모듈을 상기 제1 투영 레이어 모듈로 학습하는 방법인, 객체 인식 모델 학습 방법. |
| 11 | 제10항에 있어서,상기 제1 손실 함수는상기 학습용 텍스트 특징에서 불분명한 기하학적 노이즈를 억제하는 카메라 분류기를 포함하는, 객체 인식 모델 학습 방법. |
| 12 | 텍스트-이미지 쌍의 입력으로부터 카메라 변형 정보를 생성하는 사전 학습된 텍스트-가이드 모델;상기 텍스트-이미지 쌍의 입력으로부터 이미지 특징을 추출하는 이미지 특징 추출기;상기 이미지 특징에 기초하여 뎁스 정보를 추출하는 뎁스 추출기;상기 카메라 변형 정보, 상기 이미지 특징 및 상기 뎁스 정보에 기초하여 이미지 BEV를 생성하는 이미지 BEV; 및상기 이미지 BEV에 기초하여, 객체 인식을 수행하는 디텍션 헤드를 포함하는, 텍스트-가이드 객체 인식 모델. |
| 13 | 객체 인식 모델 학습 장치에 있어서,인스트럭션들을 포함하는 메모리; 및사전 학습된 텍스트-가이드 모델, 이미지 특징 추출기, BEV 인코더 및 라이다-가이드 모델 -포인트 클라우드 인코더를 포함함-, 디텍션 헤드를 구동하는 하나 이상의 프로세서를 포함하고,상기 인스트럭션들은 상기 프로세서에 의해 실행될 때, 상기 객체 인식 모델 학습 장치로 하여금하나 이상의 텍스트 입력 및 상기 하나 이상의 텍스트 입력에 대응하는 하나 이상의 이미지 입력을 수신하고, 상기 텍스트-가이드 모델 및 상기 이미지 특징 추출기를 이용하여, 상기 객체 인식 모델의 학습에 사용되는 하나 이상의 텍스트-이미지 특징을 출력하고,상기 텍스트-이미지 특징 및 상기 라이다-가이드 모델의 결과에 기초하여, 객체 인식 모델을 학습하도록 하는, 객체 인식 모델 학습 장치. |
| 14 | 제13항에 있어서,상기 텍스트-가이드 모델은상기 하나 이상의 텍스트 입력에 대해 텍스트 인코더 및 제1 투영 레이어 모듈을 통해 의미론적 정보 인코딩을 수행하여, 상기 하나 이상의 카메라 변형 정보를 생성하고,상기 하나 이상의 텍스트-이미지 특징은상기 하나 이상의 카메라 변형 정보와 상기 이미지 특징 추출기에서 추출된 하나 이상의 이미지 특징을 더하여 생성되는, 객체 인식 모델 학습 장치. |
| 15 | 제13항에 있어서,상기 라이다-가이드 모델은상기 포인트 클라우드 인코더로부터 획득한 라이다 BEV들과 상기 BEV 인코더로부터 획득한 이미지 BEV들을 대조 학습하는 모델인, 객체 인식 모델 학습 장치. |
| 16 | 제15항에 있어서,상기 대조 학습은상기 라이다 BEV와 상기 이미지 BEV에 대한 교차 상관 관계를 제2 손실 함수에 기초하여 상기 객체 인식 모델을 학습하는 방법인, 객체 인식 모델 학습 장치. |
| 17 | 제15항에 있어서,상기 프로세서는상기 하나 이상의 텍스트-이미지 특징 또는 상기 대조 학습 결과에 기초하여, 상기 이미지 특징 추출기, 상기 뎁스 추출기, 상기 BEV 인코더, 상기 디텍션 헤드 중 적어도 하나를 업데이트하는, 객체 인식 모델 학습 장치. |
| 18 | 텍스트-가이드 모델 학습 장치에 있어서,인스트럭션들을 포함하는 메모리; 및텍스트 인코더, 제2 투영 레이어 모듈 및 이미지 인코더를 포함하는 하나 이상의 프로세서를 포함하고,상기 인스트럭션들은 상기 프로세서에 의해 실행될 때, 상기 텍스트-가이드 모델 학습 장치로 하여금,텍스트 입력 및 이미지 입력을 수신하고,상기 텍스트 입력에서 상기 텍스트 인코더 및 상기 제2 투영 레이어 모듈을 이용하여 텍스트 특징-카메라 변형 정보를 포함함-을 추출하여, 공유 임베딩 공간에 투영하고,상기 이미지 입력에서 상기 이미지 인코더를 이용하여 이미지 특징을 추출하여, 상기 공유 임베딩 공간에 투영하고,미리 결정된 방법을 이용하여, 상기 제2 투영 레이어 모듈을 제1 투영 레이어 모듈로 업데이트하여, 사전 학습된 텍스트-가이드 모델을 획득하도록 하는, 텍스트-가이드 모델 학습 장치. |
| 19 | 제18항에 있어서,상기 미리 결정된 방법은상기 텍스트 특징과 상기 이미지 특징을 상기 공유 임베딩 공간에서 대조 정렬 학습하고,상기 대조 정렬 학습 결과 및 제1 손실 함수를 이용하여, 상기 제2 투영 레이어 모듈을 상기 제1 투영 레이어 모듈로 학습하는 방법인, 객체 인식 모델 학습 방법. |
| 20 | 제19항에 있어서,상기 제1 손실 함수는상기 학습용 텍스트 특징에서 불분명한 기하학적 노이즈를 억제하는 카메라 분류기를 포함하는, 객체 인식 모델 학습 방법. |