| 번호 | 청구항 |
|---|---|
| 16 | 제15항에 있어서,상기 강화 학습은 상기 특정 액션에 따른 보상을 최대화하도록 상기 품질을 업데이트하는 Q-러닝에 기초하고,상기 보상은,상기 특정 액션에 따른 상기 복수의 프로세싱 유닛들에 의한 할당된 상기 복수의 딥 뉴럴 네트워크들의 프로세스의 시간이 짧을수록 큰 값을 갖거나, 상기 프로세스의 정확도가 클수록 큰 값을 갖거나, 상기 프로세스의 런타임에서의 상기 복수의 프로세싱 유닛들의 온도가 작을수록 큰 값을 갖거나, 상기 프로세스의 런타임에서의 상기 복수의 프로세싱 유닛들의 에너지 소비량이 작을수록 큰 값을 갖는, 시스템. |
| 17 | 제15항에 있어서,상기 미리 결정된 복수의 스테이트들은 상기 복수의 프로세싱 유닛들 각각의 이용률 및 온도, 및 상기 메모리의 이용률 중 적어도 하나의 전체 범위를 포괄하는 유한한 개수의 스테이트들인, 시스템. |
| 18 | 제15항에 있어서,상기 적어도 하나의 프로세싱 유닛은,상기 특정 액션에 따라 할당된 상기 복수의 딥 뉴럴 네트워크들을 프로세스하기 위한 상기 복수의 프로세싱 유닛들 각각의 전압 및 주파수 중 적어도 하나의 값을 설정하도록 구성된, 시스템. |
| 19 | 강화 학습에 기초하여 딥 뉴럴 네트워크를 프로세싱 유닛에 할당하기 위한 시스템의 작동 방법에 있어서,미리 결정된 복수의 스테이트들 중에서 복수의 프로세싱 유닛들을 포함하는 시스템의 스테이트에 대응하는 특정 스테이트를 선택하는 단계;강화 학습에 기초하여 미리 결정된 품질을 갖는 미리 결정된 복수의 액션들 중에서, 상기 특정 스테이트에서 최대 품질을 갖는 특정 액션을 선택하는 단계; 및상기 특정 액션을 수행함으로써 복수의 딥 뉴럴 네트워크들을 상기 복수의 프로세싱 유닛들에 할당하는 단계를 포함하는, 시스템의 작동 방법. |
| 20 | 제19항에 있어서,상기 특정 액션에 따라 할당된 상기 복수의 딥 뉴럴 네트워크들을 프로세스하기 위한 상기 복수의 프로세싱 유닛들 각각의 전압 및 주파수 중 적어도 하나의 값을 설정하는 단계를 더 포함하는, 시스템의 작동 방법. |
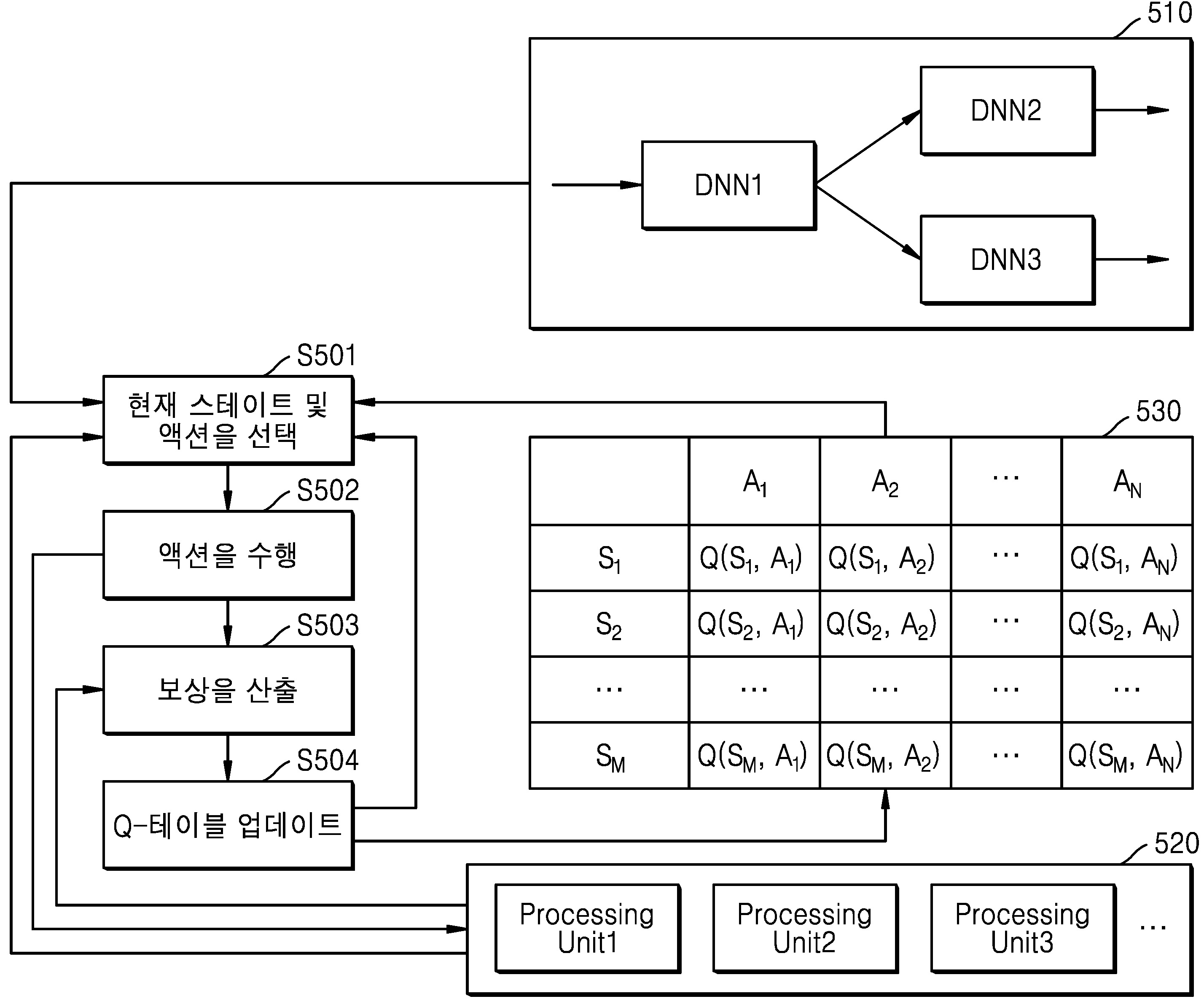
| 1 | 강화 학습에 기초하여 딥 뉴럴 네트워크를 프로세싱 유닛에 할당하기 위한 시스템에 있어서,하나 이상의 인스트럭션들을 저장하도록 구성된 메모리; 및복수의 프로세싱 유닛들을 포함하며, 상기 복수의 프로세싱 유닛들 중 적어도 하나의 프로세싱 유닛은 상기 하나 이상의 인스트럭션들을 실행함으로써:미리 결정된 복수의 스테이트들 중에서 상기 시스템의 스테이트에 대응하는 현재 스테이트(current state)를 선택하고,미리 결정된 품질(quality)을 갖는 미리 결정된 복수의 액션들 중에서, 상기 현재 스테이트에서 최대 품질을 갖는 액션을 선택하고,선택된 상기 액션을 수행함으로써 복수의 딥 뉴럴 네트워크들을 상기 복수의 프로세싱 유닛들에 할당하고,상기 복수의 프로세싱 유닛들에 의한 할당된 상기 복수의 딥 뉴럴 네트워크들의 프로세스가 미리 결정된 제약들(constraints)을 만족하도록 수행되었는지 여부에 기초하여 보상(reward)을 산출하고,상기 보상을 이용하여 상기 현재 스테이트에서 선택된 상기 액션의 품질을 업데이트하도록 구성된, 시스템. |
| 2 | 제1항에 있어서,상기 적어도 하나의 프로세싱 유닛은,상기 미리 결정된 복수의 스테이트들 중에서, 상기 복수의 프로세싱 유닛들 각각의 이용률(utilization) 및 온도 중 적어도 하나에 대응하는 상기 현재 스테이트를 선택하도록 구성된, 시스템. |
| 3 | 제2항에 있어서,상기 적어도 하나의 프로세싱 유닛은,상기 미리 결정된 복수의 스테이트들 중에서, 상기 메모리의 이용률에 대응하는 상기 현재 스테이트를 선택하도록 구성된, 시스템. |
| 4 | 제3항에 있어서,상기 미리 결정된 복수의 스테이트들은 상기 복수의 프로세싱 유닛들 각각의 이용률 및 온도, 및 상기 메모리의 이용률 중 적어도 하나의 전체 범위를 포괄하는 유한한 개수의 스테이트들인, 시스템. |
| 5 | 제1항에 있어서,상기 적어도 하나의 프로세싱 유닛은,상기 미리 결정된 복수의 스테이트들 중에서, 상기 복수의 딥 뉴럴 네트워크의 개수 및 상기 복수의 딥 뉴럴 네트워크 중에서 미리 결정된 개수보다 많은 개수의 연산을 포함하는 딥 뉴럴 네트워크의 개수 중 적어도 하나에 대응하는 상기 현재 스테이트를 선택하도록 구성된, 시스템. |
| 6 | 제5항에 있어서,상기 연산은 곱셈 연산, 누적 연산, 및 곱셈-누적(MAC) 연산 중 적어도 하나를 포함하는, 시스템. |
| 7 | 제1항에 있어서,상기 복수의 프로세싱 유닛들은 CPU, GPU, NPU, 및 DSP 중 적어도 하나를 포함하는, 시스템. |
| 8 | 제1항에 있어서,상기 미리 결정된 복수의 액션들은 미리 결정된 조합으로 상기 복수의 딥 뉴럴 네트워크들을 상기 복수의 프로세싱 유닛들에 할당하는 것을 포함하는, 시스템. |
| 9 | 제8항에 있어서,상기 미리 결정된 복수의 액션들은 상기 복수의 프로세싱 유닛들 각각의 전압 및 주파수 중 적어도 하나의 값을 미리 결정된 값으로 설정하는 것을 더 포함하는, 시스템. |
| 10 | 제1항에 있어서,상기 적어도 하나의 프로세싱 유닛은,상기 현재 스테이트에서 선택된 상기 액션에 따른 상기 프로세스를 수행하기 위한 상기 복수의 프로세싱 유닛들 각각의 전압 및 주파수 중 적어도 하나의 값을 설정하도록 구성된, 시스템. |
| 11 | 제1항에 있어서,상기 적어도 하나의 프로세싱 유닛은,상기 현재 스테이트에서 선택된 상기 액션에 따른 상기 프로세스의 시간 및 정확도 중 적어도 하나를 획득하고,상기 프로세스의 상기 시간 및 상기 정확도 중 획득된 상기 적어도 하나가 상기 미리 결정된 제약들을 만족하는지 여부에 기초하여 상기 보상을 산출하도록 구성된, 시스템. |
| 12 | 제1항에 있어서,상기 적어도 하나의 프로세싱 유닛은,상기 현재 스테이트에서 선택된 상기 액션에 따른 상기 프로세스의 런타임에서의 상기 복수의 프로세싱 유닛들의 온도를 획득하고,상기 복수의 프로세싱 유닛들의 상기 온도가 상기 미리 결정된 제약들을 만족하는지 여부에 기초하여 상기 보상을 산출하도록 구성된, 시스템. |
| 13 | 제1항에 있어서,상기 적어도 하나의 프로세싱 유닛은,상기 현재 스테이트에서 선택된 상기 액션에 따른 상기 프로세스의 시간 및 정확도, 및 상기 현재 스테이트에서 선택된 상기 액션에 따른 상기 프로세스의 런타임에서의 상기 복수의 프로세싱 유닛들의 온도 및 에너지 소비량 중 적어도 하나에 종속적(dependent on)이도록 상기 보상을 산출하도록 구성된, 시스템. |
| 14 | 제1항에 있어서,상기 강화 학습은 Q-러닝에 기초하고,상기 적어도 하나의 프로세싱 유닛은,상기 Q-러닝에 기초하여 상기 현재 스테이트에서 선택된 상기 액션의 상기 품질을 업데이트하도록 구성된, 시스템. |
| 15 | 강화 학습에 기초하여 딥 뉴럴 네트워크를 프로세싱 유닛에 할당하기 위한 시스템에 있어서,하나 이상의 인스트럭션들을 저장하도록 구성된 메모리; 및복수의 프로세싱 유닛들을 포함하며, 상기 복수의 프로세싱 유닛들 중 적어도 하나의 프로세싱 유닛은 상기 하나 이상의 인스트럭션들을 실행함으로써:미리 결정된 복수의 스테이트들 중에서 상기 시스템의 스테이트에 해당하는 특정 스테이트를 선택하고,강화 학습에 기초하여 미리 결정된 품질을 갖는 미리 결정된 복수의 액션들 중에서, 상기 특정 스테이트에서 최대 품질을 갖는 특정 액션을 선택하고,상기 특정 액션을 수행함으로써 복수의 딥 뉴럴 네트워크들을 상기 복수의 프로세싱 유닛들에 할당하도록 구성된, 시스템. |