| 번호 | 청구항 |
|---|---|
| 18 | 제 15항에 있어서,상기 유효 문자열 셋의 부분 문자열은 상기 유효 문자열 셋의 다른 부분 문자열에 포함되지 않는 질의 처리 장치. |
| 19 | 제 15항에 있어서,상기 후보셋은,상기 유효 문자열 셋의 서브셋들 중 상기 접근 비용이 최소인 서브셋으로 결정되는 질의 처리 장치. |
| 20 | 제 15항에 있어서,상기 후보셋은, 상기 유효 문자열 셋의 서브셋들 중 부분 문자열이 추가될 때의 접근 비용보다 접근 비용이 적은 서브셋으로 결정되는 질의 처리 장치. |
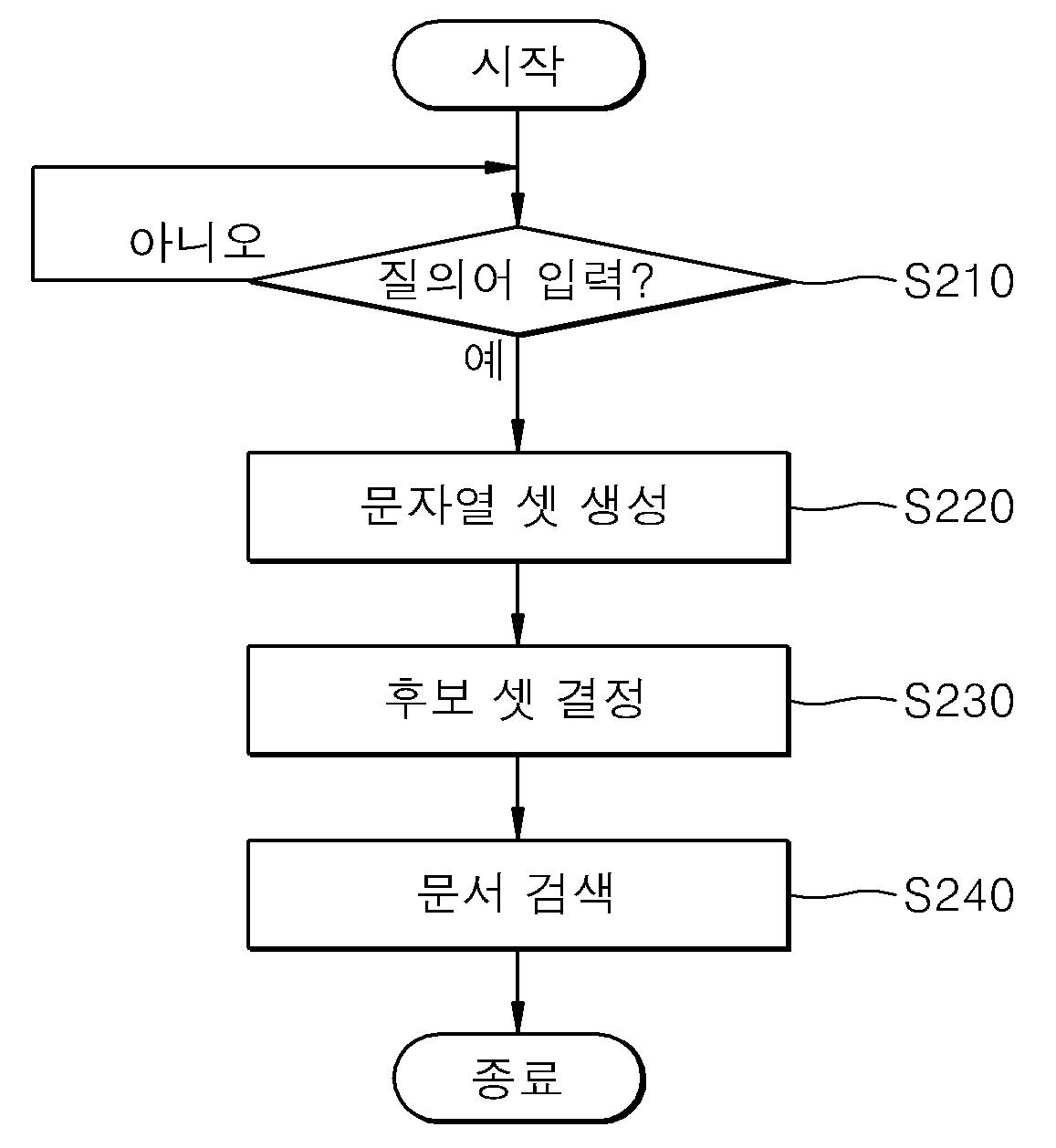
| 1 | 프로세서에 의해, 질의 문자열로부터 길이가 다른 복수 개의 부분 문자열들로 구성된 유효 문자열 셋을 생성하는 단계; 다수의 문서들의 정보가 저장된 데이터베이스에 대한 상기 유효 문자열 셋의 서브셋들의 접근 비용에 기초하여, 상기 프로세서에 의해, 상기 서브셋들 중 어느 하나를 후보셋으로 결정하는 단계; 및 상기 프로세서의 의해, 상기 후보셋을 이용하여 상기 데이터베이스에 저장된 정보로부터 상기 질의 문자열이 존재하는 문서를 검색하는 단계를 포함하고, 상기 유효 문자열 셋을 생성하는 단계는, 상기 질의 문자열을 길이가 다른 복수 개의 엔-그램으로 분리하고, 상기 복수 개의 엔-그램 중 상기 데이터베이스의 색인어에 포함되는 엔-그램을 선택하고, 상기 선택된 엔-그램 중 다른 엔-그램에 포함되지 않는 엔-그램의 셋을 상기 유효 문자열 셋으로 결정하는 질의 처리 방법. |
| 2 | 제 1 항에 있어서,상기 후보셋은 접근 비용이 기준 값 이하를 갖는 서브셋인 질의 처리 방법. |
| 3 | 제 2항에 있어서,상기 기준값은 상기 유효 문자열 셋의 서브셋에 대한 접근 비용의 산출시, 기산출된 접근 비용 중 최소값인 질의 처리 방법. |
| 4 | 제 1 항에 있어서,상기 접근 비용은,상기 데이터베이스에서 상기 서브셋에 포함된 부분 문자열 각각의 포스팅 리스트를 접근하여 독출하는데 소요되는 비용의 합과 상기 데이터베이스에서 상기 서브셋에 포함된 유효 문자열의 포스팅 리스트에 공통으로 포함된 문서의 식별 정보를 접근하여 독출하는데 소요되는 비용 중 적어도 하나인 질의 처리 방법. |
| 5 | 제 1 항에 있어서,상기 유효 문자열 셋의 부분 문자열들 중 적어도 두 개의 부분 문자열의 길이는 서로 다른 질의 처리 방법. |
| 6 | 제 1항에 있어서,상기 유효 문자열 셋의 부분 문자열은 상기 유효 문자열 셋의 다른 부분 문자열에 포함되지 않는 질의 처리 방법. |
| 7 | 삭제 |
| 8 | 제 1항에 있어서,상기 후보셋은,상기 유효 문자열 셋의 서브셋들 중 상기 접근 비용이 최소인 서브셋으로 결정되는 질의 처리 방법. |
| 9 | 제 1항에 있어서,상기 후보셋은, 상기 유효 문자열 셋의 서브셋들 중 부분 문자열이 추가될 때의 접근 비용보다 접근 비용이 적은 서브셋으로 결정되는 질의 처리 방법. |
| 10 | 제 1항에 있어서,상기 후보셋으로 결정하는 단계는,상기 유효 문자열 셋의 서브셋을 트리 구조로 정렬하고, 깊이 우선 탐색 방법으로 상기 트리 구조에서의 서브셋를 선택하고,상기 선택된 서브셋의 접근 비용을 산출하고, 최소의 접근 비용을 갖는 서브셋을 후보셋으로 결정하는 것을 포함하는 질의 처리 방법. |
| 11 | 제 1항에 있어서,상기 후보셋으로 결정하는 단계는상기 유효 문자열 셋의 서브셋 중 부분 문자열의 개수가 동일한 제1 서브셋들을 선택하고, 상기 제1 서브셋들 각각에 대한 접근 비용을 산출하며, 최소의 접근 비용을 갖는 서브셋을 후보셋으로 예상하고, 상기 유효 문자열 셋의 서브셋 중 상기 예상된 후보셋에 부분 문자열이 추가된 제2 서브셋을 선택하며, 상기 제2 서브셋들 각각에 대한 접근 비용이 상기 예상된 후보셋의 접근 비용보다 크면, 상기 예상된 후보셋을 후보셋으로 결정하는 것을 포함하는 질의 처리 방법. |
| 12 | 제 1항에 있어서,상기 데이터베이스는,색인 트리 및 포스팅 리스트를 포함하는 역색인 데이터베이스; 및 식별 정보를 갖는 다수의 문서들이 저장된 문서 데이터베이스;를 포함하는 질의 처리 방법. |
| 13 | 제 12항에 있어서,상기 문서를 결정하는 단계는,상기 역색인 데이터베이스에서 상기 후보셋의 부분 문자열 모두와 매칭되어 있는 문서의 식별 정보를 검색하고, 상기 문서데이터베이스에서 상기 문서의 식별 정보를 갖는 문서를 검색하는 것을 포함하는 질의 처리 방법. |
| 14 | 제 1항 내지 제 6항, 제 8항 내지 제 13항 중 어느 한 항의 방법을 상기 프로세서로 하여금 수행하도록 하는 프로그램이 기록된 컴퓨터 판독 가능한 기록매체. |
| 15 | 질의 문자열이 입력되고 상기 질의 문자열이 존재하는 문서가 출력되는 사용자 인터페이스;다수의 문서들에 대한 정보가 저장된 데이터베이스; 및 상기 질의 문자열로부터 길이가 다른 복수 개의 부분 문자열들로 구성된 유효 문자열 셋을 생성하고, 상기 데이터베이스에 대한 상기 유효 문자열 셋의 서브셋들의 접근 비용에 기초하여 상기 서브셋들 중 어느 하나를 후보 셋으로 결정하며, 상기 후보셋을 이용하여 상기 데이터베이스에 저장된 정보로부터 상기 질의 문자열이 존재하는 문서를 검색하는 프로세서;를 포함하고,상기 프로세서는, 상기 질의 문자열을 길이가 다른 복수 개의 엔-그램으로 분리하고, 상기 복수 개의 엔-그램 중 상기 데이터베이스의 색인어에 포함되는 엔-그램을 선택하며, 상기 선택된 엔-그램 중 다른 엔-그램에 포함되지 않는 엔-그램의 셋을 상기 유효 문자열 셋으로 결정함으로써 상기 유효 문자열 셋을 생성하는 질의 처리 장치. |
| 16 | 제 15항에 있어서,상기 접근 비용은,상기 데이터베이스에서 상기 서브셋에 포함된 부분 문자열 각각의 포스팅 리스트를 접근하여 독출하는데 소요되는 비용의 합과 상기 데이터베이스에서 상기 서브셋에 포함된 유효 문자열의 포스팅 리스트에 공통으로 포함된 문서의 식별 정보를 접근하여 독출하는데 소요되는 비용 중 적어도 하나인 질의 처리 장치. |
| 17 | 제 15항에 있어서,상기 유효 문자열 셋의 부분 문자열들 중 적어도 두 개의 부분 문자열의 길이는 서로 다른 질의 처리 장치. |
| 21 | 제 15항에 있어서,상기 데이터베이스는,색인 트리 및 포스팅 리스트를 포함하는 역색인 데이터베이스; 및 식별 정보를 갖는 다수의 문서들이 저장된 문서 데이터베이스;를 포함하는 질의 처리 장치. |
| 22 | 제 21항에 있어서,상기 프로세서는, 상기 역색인 데이터베이스에서 상기 후보셋의 부분 문자열 모두와 매칭되어 있는 상기 문서의 식별 정보를 검색하고, 상기 문서데이터베이스에서 상기 문서의 식별 정보를 갖는 문서를 검색하는 것을 포함하는 질의 처리 장치. |