| 번호 | 청구항 |
|---|---|
| 1 | 제 2항에 있어서,상기 a)단계는,상기 분리된 보컬트랙과 반주트랙이 재결합되어 생성된 음원과 상기 원곡 간의 차이가 최소화되는 방향으로 상기 획득된 파라미터값을 조정하는 학습을 반복하는 단계;를 포함하는, 딥러닝 기반 음원 생성 방법. |
| 1 | 제 1항에 있어서,상기 b)단계는,상기 사용자 단말로부터 자작곡의 콘텐츠를 수신하는 경우, 기 설정된 음원분리 알고리즘을 이용하여 상기 자작곡의 콘텐츠를 보컬트랙 및 반주트랙으로 분리하는 단계;를 포함하는, 딥러닝 기반 음원 생성 방법. |
| 1 | 제 1항에 있어서,상기 c)단계는,상기 사용자 단말로부터 상기 사용자 음원에 대한 피드백 정보를 수신하고, 상기 피드백 정보를 기초로 상기 믹싱모델을 학습하여 업데이트하는 단계;를 포함하는, 딥러닝 기반 음원 생성 방법. |
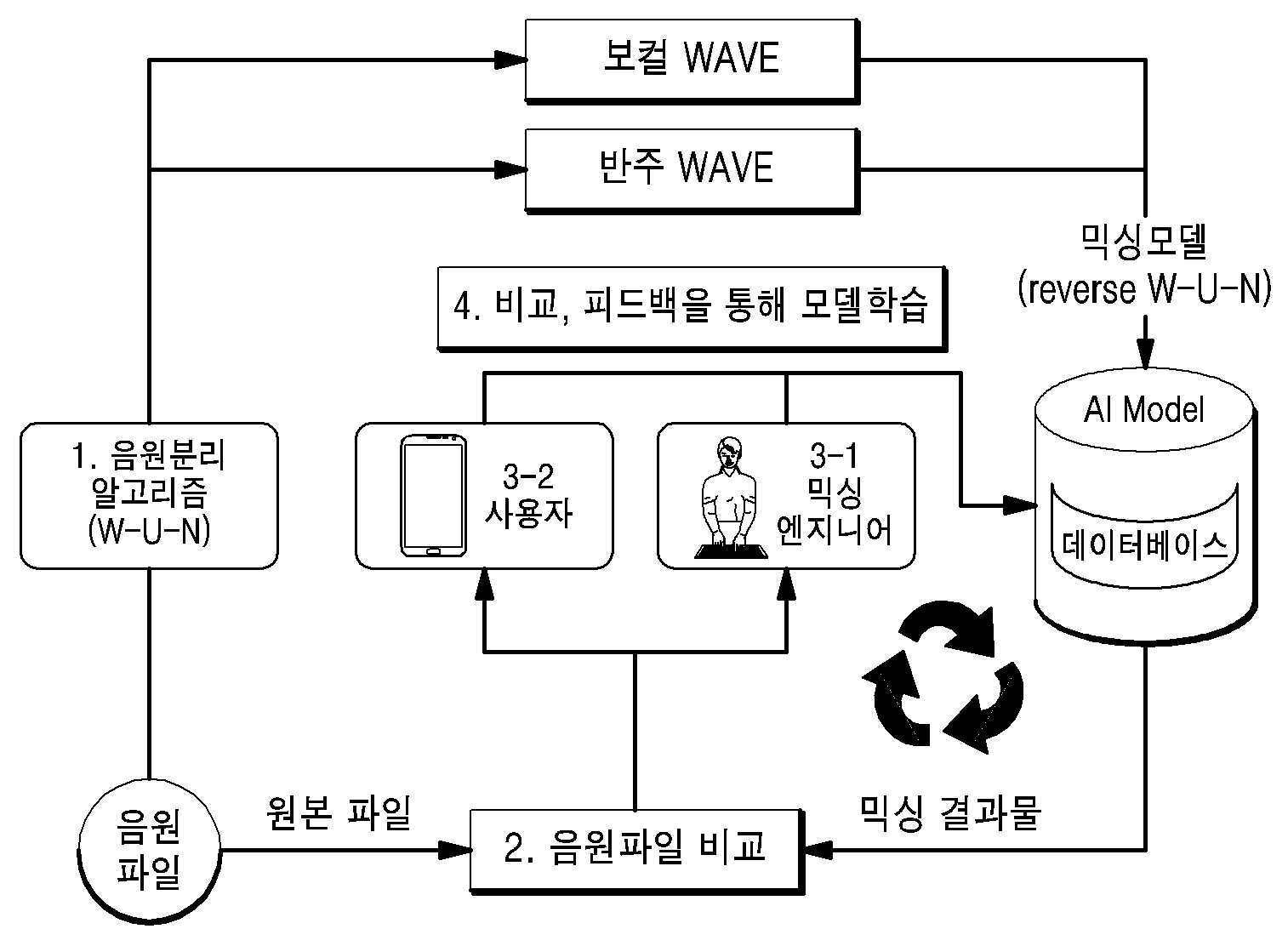
| 1 | 서버에 의해 수행되는, 딥러닝 기반 음원 생성 방법에 있어서,a) 기 수집된 원곡의 음원을 이용하여, 적어도 두 개의 트랙으로 분리된 음원이 결합되는 과정에서 적용되는 파라미터값을 도출하기 위한 믹싱모델을 학습하는 단계;b) 사용자 단말로 반주트랙을 제공하고 상기 사용자 단말로부터 상기 반주트랙에 따라 사용자로부터 녹음된 보컬트랙을 수신하는 단계; 및c) 상기 보컬트랙 및 반주트랙을 상기 믹싱모델에 입력하여 적어도 하나 이상의 파라미터값을 출력하고, 상기 파라미터값을 기초로 상기 보컬트랙 및 반주트랙을 결합한 사용자 음원을 생성하여 상기 사용자 단말로 제공하는 단계;를 포함하되,상기 파라미터값은 기 설정된 종류의 믹싱값 및 마스터링값을 포함하는 것인, 딥러닝 기반 음원 생성 방법. |
| 1 | 제 1항에 있어서,상기 a)단계는,기 설정된 음원분리 알고리즘을 이용하여 상기 원곡의 음원을 보컬트랙과 반주트랙으로 분리하고,분리된 보컬트랙과 반주트랙을 재결합하며, 재결합할 때 사용되는 적어도 하나 이상의 파라미터값을 획득하는 단계;를 포함하는, 딥러닝 기반 음원 생성 방법. |
| 1 | 제 2항에 있어서,상기 a)단계에서,상기 분리된 보컬트랙과 반주트랙은, 상기 음원분리 알고리즘이 리버스(reverse)되어 설계된 알고리즘을 통해 재결합되는 것인, 딥러닝 기반 음원 생성 방법. |
| 1 | 제 6항에 있어서,상기 c)단계는,서로 다른 파라미터값이 적용된 복수의 사용자 음원을 생성하여 상기 사용자 단말로 추천하고,추천된 사용자 음원 중 사용자에 의해 선택된 사용자 음원 및 선택한 이유에 대한 정보를 포함하는 피드백 정보를 상기 사용자 단말로부터 수신하고,상기 피드백 정보에 따라 상기 믹싱모델에 의해 출력되는 파라미터값과 상기 선택된 사용자 음원에 적용된 파라미터값 간의 차이가 최소화되는 방향으로 학습을 반복하는 단계;를 포함하는, 딥러닝 기반 음원 생성 방법. |
| 1 | 제 1항에 있어서,상기 c)단계는,상기 파라미터값 및 상기 사용자 음원을 기 설정된 믹싱엔지니어의 디지털믹싱콘솔로 전송하고,상기 믹싱엔지니어에 의해 확정된 상기 파라미터값의 조정값을 상기 디지털믹싱콘솔로부터 수신하고,상기 조정값을 기초로 상기 믹싱모델을 학습하여 업데이트하는 단계;를 포함하는, 딥러닝 기반 음원 생성 방법. |
| 1 | 제 1항에 있어서,상기 믹싱값은 보컬 싱크값, 마스터볼륨값 및 편집 옵션값 중 적어도 하나를 포함하고, 상기 마스터링값은 더블링값, 컴프레서값, 이퀄라이져값, 리버브값, 딜레이값 및 리미터값 중 적어도 하나를 포함하는 것인, 딥러닝 기반 음원 생성 방법. |
| 1 | 음원 생성 서버에 있어서,딥러닝 기반 음원 생성 방법을 수행하기 위한 프로그램이 저장된 메모리; 및상기 프로그램을 실행하는 프로세서;를 포함하고,상기 방법은,a) 기 수집된 원곡의 음원을 이용하여, 적어도 두 개의 트랙으로 분리된 음원이 결합되는 과정에서 적용되는 파라미터값을 도출하기 위한 믹싱모델을 학습하는 단계;b) 사용자 단말로 반주트랙을 제공하고 상기 사용자 단말로부터 상기 반주트랙에 따라 사용자로부터 녹음된 보컬트랙을 수신하는 단계; 및c) 상기 보컬트랙 및 반주트랙을 상기 믹싱모델에 입력하여 적어도 하나 이상의 파라미터값을 출력하고, 상기 파라미터값을 기초로 상기 보컬트랙 및 반주트랙을 결합한 사용자 음원을 생성하여 상기 사용자 단말로 제공하는 단계;를 포함하되,상기 파라미터값은 기 설정된 종류의 믹싱값 및 마스터링값을 포함하는 것인, 음원 생성 서버. |