| 번호 | 청구항 |
|---|---|
| 11 | 제10항에 있어서, 상기 학습 네트워크는상기 컨텍스트 잠재 표현과 상기 예측값 간의 상관관계에 관한 상호 정보(mutual information)를 학습하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 12 | 제11항에 있어서, 상기 학습 네트워크는상기 상호 정보를 로그-이중선형 모델(log-bilinear model)을 통해 모델링하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
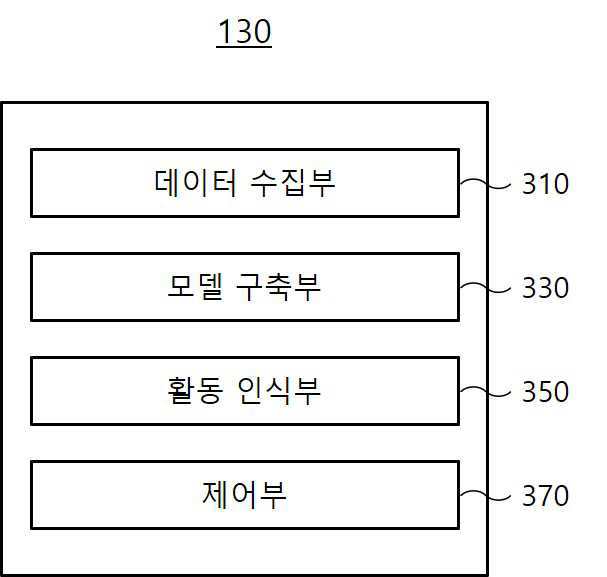
| 1 | 특정 시간 동안 특정 움직임을 수행하는 사용자로부터 하나 이상의 센서 데이터와 생체 데이터를 각각 수집하는 데이터 수집부;상기 센서 데이터의 동적 정보와 상기 생체 데이터의 정적 정보를 함께 학습하여 인간 활동 인식을 위한 인식 모델을 구축하는 모델 구축부; 및상기 인식 모델을 기초로 상기 특정 시간에 이산적 또는 연속적으로 계속되는 다음 시간 동안의 상기 사용자의 움직임을 예측하는 활동 인식부;를 포함하고,상기 인식 모델은상기 동적 정보와 상기 정적 정보 간의 융합 과정을 수행하는 인코더 네트워크; 및상기 인코더 네트워크의 출력을 이용하여 상기 사용자의 움직임에 관한 예측값을 생성하는 학습 네트워크;를 포함하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 2 | 제1항에 있어서, 상기 인코더 네트워크는상기 정적 정보를 처리한 결과로서 정적 변수들을 생성하는 정적 인코더(static encoder);하나의 센서 데이터로부터 증강된 서로 다른 증강 데이터를 상기 정적 변수들 중 일부와 함께 수신하여 독립적으로 처리하는 관찰 인코더(observed encoder); 및상기 관찰 인코더의 출력에 독립적으로 연결되는 복수의 GRN(Gated Residual Network) 블록들을 포함하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 3 | 제2항에 있어서, 상기 인코더 네트워크는상기 정적 인코더에 의해 생성된 정적 컨텍스트 변수(static context variable)를 상기 관찰 인코더의 입력으로 제공하고,상기 정적 인코더에 의해 생성된 정적 강화 변수(static enrichment variable)를 상기 관찰 인코더의 출력에 추가하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 4 | 제2항에 있어서, 상기 정적 인코더는정적 임베딩 레이어, 정적 변수 선택 레이어 및 GRN 레이어를 포함하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 5 | 제4항에 있어서, 상기 정적 인코더는상기 정적 임베딩 레이어를 통해, 입력값이 범주형 변수인 경우 임베딩을 수행하고 입력값이 실수형 변수인 경우 선형 변환을 수행하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 6 | 제4항에 있어서, 상기 정적 인코더는상기 정적 변수 선택 레이어의 출력에 2개의 GRN 블록들을 각각 연결하여 정적 컨텍스트 변수와 정적 강화 변수를 상기 정적 변수들로서 생성하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 7 | 제2항에 있어서, 상기 관찰 인코더는각각이 1D CNN(Convolutional Neural Network), 1D 배치 정규화 레이어 및 ReLU(Rectified Linear Unit)를 포함하는 복수의 컨볼루션 블록(convolutional block)들을 포함하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 8 | 제7항에 있어서, 상기 관찰 인코더는상기 복수의 컨볼루션 블록들 중 첫 번째 컨볼루션 블록을 통해 최대 풀링(max pooling)을 수행하고 마지막 컨볼루션 블록 이후에 전역 평균 풀링(global average pooling)을 수행하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 9 | 제7항에 있어서, 상기 관찰 인코더는상기 복수의 컨볼루션 블록들 중 두 번째 컨볼루션 블록을 통해 상기 증강 데이터와 상기 정적 변수들 중 일부를 동시 처리하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 10 | 제1항에 있어서, 상기 학습 네트워크는상기 인코더 네트워크의 출력으로부터 주어진 복수의 잠재 표현들을 통합하여 컨텍스트 잠재 표현(context latent representation)을 생성하는 자기회귀 모델(autoregression model)을 포함하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 13 | 제2항에 있어서, 상기 학습 네트워크는상기 서로 다른 증강 데이터로부터 독립적으로 생성된 서로 다른 컨텍스트 잠재 표현을 사용하여 상기 사용자의 움직임에 관한 크로스뷰 예측(cross-view prediction)을 수행하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 14 | 제13항에 있어서, 상기 학습 네트워크는상기 크로스뷰 예측 과정에서 손실함수를 통해 서로 다른 샘플들로부터의 값들의 내적을 최대화하면서 동일한 샘플들로부터 예측된 표현들의 내적을 최소화하는 방향으로 학습을 수행하는 것을 특징으로 하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 장치. |
| 15 | 인간 활동 인식 장치에서 수행되는 인간 활동 인식 방법에 있어서,데이터 수집부를 통해, 특정 시간 동안 특정 움직임을 수행하는 사용자로부터 하나 이상의 센서 데이터와 생체 데이터를 각각 수집하는 단계;모델 구축부를 통해, 상기 센서 데이터의 동적 정보와 상기 생체 데이터의 정적 정보를 함께 학습하여 인간 활동 인식을 위한 인식 모델을 구축하는 단계; 및활동 인식부를 통해, 상기 인식 모델을 기초로 상기 특정 시간에 이산적 또는 연속적으로 계속되는 다음 시간 동안의 상기 사용자의 움직임을 예측하는 단계;를 포함하고,상기 인식 모델은상기 동적 정보와 상기 정적 정보 간의 융합 과정을 수행하는 인코더 네트워크; 및상기 인코더 네트워크의 출력을 이용하여 상기 사용자의 움직임에 관한 예측값을 생성하는 학습 네트워크;를 포함하는 동적 및 정적 정보 융합 대조 학습을 통한 인간 활동 인식 방법. |