| 번호 | 청구항 |
|---|---|
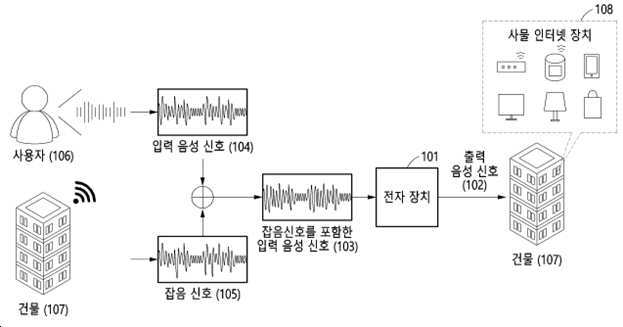
| 1 | 전자 장치가 수행하는 음성 인식 방법에 있어서,상기 전자 장치가 건물의 환경적 상황에 따른 사용자의 요구를 충족하는 특정 작업을 수행하기 위한 상기 사용자의 입력 음성 신호를 수집하는 단계;상기 전자 장치가 상기 사용자의 입력 음성 신호를 음성 향상 알고리즘에 적용하여 상기 사용자의 입력 음성 신호에서 건물의 환경적 상황과 관련된 잡음 신호를 제거하는 단계; 및상기 전자 장치가 상기 잡음 신호가 제거된 입력 음성 신호의 단어 오류율을 고려하여 상기 건물에서 활성화된 사물 인터넷 장치와 상호 작용이 가능한 출력 음성 신호를 인식하는 단계;를 포함하고상기 잡음 신호를 제거하는 단계는,상기 입력 음성 신호를 구성하는 스펙트럼 전체에 존재하는 잔류 잡음을 고려하여 상기 음성 향상 알고리즘을 통해 1차적으로 잡음 신호가 제거된 입력 음성 신호 중에서 비언어 활동 구간에 해당하는 입력 음성 신호에 포함된 상기 잔류 잡음을 2차적으로 억제함으로써, 상기 건물의 환경적 상황과 관련된 잡음 신호를 제거하는 단계를 포함하고,상기 잔류 잡음은, 단어 사이의 각 일시 중지 동안 계산된 잡음인 것을 특징으로 하며,상기 출력 음성 신호를 인식하는 단계는,상기 잡음 신호 및 잔류 잡음이 제거된 입력 음성 신호를 구성하는 각 음소의 점수를 기반으로 텍스트에 포함된 불필요한 켑스트랄 벡터를 삭제하여 상기 텍스트의 순서를 결정하는 단계; 및상기 텍스트의 순서가 결정된 출력 음성 신호의 단어 오류율을 상기 출력 음성 신호를 인식하는 단계를 포함하는 음성 인식 방법. |
| 2 | 제1항에 있어서,상기 사용자의 입력 음성 신호를 수집하는 단계는,신호 데이터 셋트의 속성 정보를 고려하여 상기 사용자의 발성 방식에 따라 연속적으로 표현되는 상기 사용자의 입력 음성 신호를 수집하는 음성 인식 방법. |
| 3 | 제1항에 있어서,상기 잡음 신호를 제거하는 단계는,상기 음성 향상 알고리즘에 적용된 상기 사용자의 입력 음성 신호의 프레임들로부터 n개의 행렬을 생성하는 단계;상기 n개의 행렬을 벡터화하여 입력 음성 신호에 포함된 잡음 신호를 제거하기 위한 n개의 벡터(Vector) 및 n개의 벡터(Vector)에 대응하는 n개의 랭크(Rank)를 생성하는 단계; 및상기 생성된 n개의 랭크를 활용하여 상기 사용자의 입력 음성 신호에 포함된 잡음을 제거하는 단계;를 포함하는 음성 인식 방법. |
| 4 | 제3항에 있어서,상기 잡음 신호를 제거하는 단계는,상기 n개의 랭크를 정렬하여 시간에 따른 t 개의 스펙트럼을 포함하는 사용자의 입력 음성 신호에 고속 퓨리에 변환을 수행하는 단계; 및상기 고속 퓨리에 변환이 수행된 사용자의 입력 음성 신호에 스펙트럼 감산 필터를 적용하여 상기 사용자의 입력 음성 신호에 포함된 잡음 신호를 제거하는 단계;를 포함하는 음성 인식 방법. |
| 5 | 제4항에 있어서,상기 잡음 신호를 제거하는 단계는,상기 스펙트럼 감산 필터를 통해 상기 고속 퓨리에 변환이 수행된 사용자의 입력 음성 신호를 구성하는 스펙트럼들 각각의 잡음 신호를 측정하는 단계; 및상기 입력 음성 신호를 구성하는 스펙트럼들 중 상기 잡음 신호가 측정된 스펙트럼을 제거하는 단계;를 포함하는 음성 인식 방법. |
| 6 | 제5항에 있어서,상기 잡음 신호가 측정된 스펙트럼을 제거하는 단계는,상기 잡음이 측정된 스펙트럼들에 포함된 잡음 신호의 평균을 이용하여 잡음 신호가 측정되지 않은 스펙트럼에서 예상되는 잡음 신호의 범위를 예측하는 단계; 및상기 예측된 잡음 신호의 범위를 고려하여 상기 입력 음성 신호를 구성하는 스펙트럼들 중 상기 잡음 신호가 측정된 음성 스펙트럼을 제거하는 단계;를 포함하는 음성 인식 방법. |
| 7 | 제1항에 있어서,상기 출력 음성 신호를 인식하는 단계는,상기 잡음 신호가 제거된 입력 음성 신호를 음소 단위로 분류하여 단일 형태 또는, 연속 형태의 텍스트로 변환하는 단계;상기 텍스트에 포함된 켑스트랄 벡터(Cepstral Vector)를 삭제하여 상기 텍스트의 순서를 결정하는 단계; 및상기 텍스트의 순서에 따른 텍스트와 텍스트 사이에 포함된 잡음 신호를 추가로 제거하여 상호 작용이 가능한 출력 음성 신호를 인식하는 단계;를 포함하는 음성 인식 방법. |
| 8 | 제7항에 있어서,상기 출력 음성 신호를 인식하는 단계는,상기 잡음 신호가 추가로 제거된 텍스트를 분석하여 텍스트가 나타내는 단어 오류율을 판단하는 단계; 및상기 단어 오류율과 기 설정된 임계치를 비교하여 건물에서 활성화된 사물 인터넷 장치와 상호 작용이 가능한 출력 음성 신호를 인식하는 단계;를 포함하는 음성 인식 방법. |
| 9 | 음성 인식 방법을 수행하는 전자 장치에 있어서,상기 전자 장치는, 프로세서를 포함하고,상기 프로세서는,건물의 환경적 상황에 따른 사용자의 요구를 충족하는 특정 작업을 수행하기 위한 상기 사용자의 입력 음성 신호를 수집하고,상기 사용자의 입력 음성 신호를 음성 향상 알고리즘에 적용하여 상기 사용자의 입력 음성 신호에서 건물의 환경적 상황과 관련된 잡음 신호를 제거하고,상기 잡음 신호가 제거된 입력 음성 신호의 오류율을 고려하여 상기 건물에서 활성화된 사물 인터넷 장치와 상호 작용이 가능한 출력 음성 신호를 인식하며,상기 잡음 신호를 제거함에 있어,상기 입력 음성 신호를 구성하는 스펙트럼 전체에 존재하는 잔류 잡음을 고려하여 상기 음성 향상 알고리즘을 통해 1차적으로 잡음 신호가 제거된 입력 음성 신호 중에서 비언어 활동 구간에 해당하는 입력 음성 신호에 포함된 상기 잔류 잡음을 2차적으로 억제함으로써, 상기 건물의 환경적 상황과 관련된 잡음 신호를 제거하고,상기 잔류 잡음은, 단어 사이의 각 일시 중지 동안 계산된 잡음인 것을 특징으로 하며,상기 출력 음성 신호를 인식함에 있어,상기 잡음 신호 및 잔류 잡음이 제거된 입력 음성 신호를 구성하는 각 음소의 점수를 기반으로 텍스트에 포함된 불필요한 켑스트랄 벡터를 삭제하여 상기 텍스트의 순서를 결정하고,상기 텍스트의 순서가 결정된 출력 음성 신호의 단어 오류율을 상기 출력 음성 신호를 인식하는 전자 장치. |
| 10 | 제9항에 있어서,상기 프로세서는,신호 데이터 셋트의 속성 정보를 고려하여 상기 사용자의 발성 방식에 따라 연속적으로 표현되는 상기 사용자의 입력 음성 신호를 수집하는 전자 장치. |
| 11 | 제9항에 있어서,상기 프로세서는,상기 음성 향상 알고리즘에 적용된 상기 사용자의 입력 음성 신호의 프레임들로부터 n개의 행렬을 생성하고,상기 n개의 행렬을 벡터화하여 입력 음성 신호에 포함된 잡음 신호를 제거하기 위한 n개의 벡터 및 n개의 벡터에 대응하는 n개의 랭크를 생성하고,상기 생성된 n개의 랭크를 활용하여 상기 사용자의 입력 음성 신호에 포함된 잡음을 제거하는 전자 장치. |
| 12 | 제11항에 있어서,상기 프로세서는,상기 n개의 랭크를 정렬하여 시간에 따른 t 개의 스펙트럼을 포함하는 사용자의 입력 음성 신호에 고속 퓨리에 변환을 수행하고,상기 고속 퓨리에 변환이 수행된 사용자의 입력 음성 신호에 스펙트럼 감산 필터를 적용하여 상기 사용자의 입력 음성 신호에 포함된 잡음 신호를 제거하는 전자 장치. |
| 13 | 제12항에 있어서,상기 프로세서는,상기 스펙트럼 감산 필터를 통해 상기 고속 퓨리에 변환이 수행된 사용자의 입력 음성 신호를 구성하는 스펙트럼들 각각의 잡음 신호를 측정하고,상기 입력 음성 신호를 구성하는 스펙트럼들 중 상기 잡음 신호가 측정된 스펙트럼을 제거하는 전자 장치. |
| 14 | 제13항에 있어서,상기 프로세서는,상기 잡음이 측정된 스펙트럼들에 포함된 잡음 신호의 평균을 이용하여 잡음 신호가 측정되지 않은 스펙트럼에서 예상되는 잡음 신호의 범위를 예측하고,상기 예측된 잡음 신호의 범위를 고려하여 상기 입력 음성 신호를 구성하는 스펙트럼들 중 상기 잡음 신호가 측정된 음성 스펙트럼을 제거하는 전자 장치. |
| 15 | 제9항에 있어서,상기 프로세서는,상기 잡음 신호가 제거된 입력 음성 신호를 음소 단위로 분류하여 단일 형태 또는, 연속 형태의 텍스트로 변환하고,상기 텍스트에 포함된 켑스트랄 벡터를 삭제하여 상기 텍스트의 순서를 결정하고,상기 텍스트의 순서에 따른 텍스트와 텍스트 사이에 포함된 잡음 신호를 추가로 제거하여 상호 작용이 가능한 출력 음성 신호를 인식하는 전자 장치. |
| 16 | 제15항에 있어서,상기 프로세서는,상기 잡음 신호가 추가로 제거된 텍스트를 분석하여 텍스트가 나타내는 단어 오류율을 판단하고,상기 단어 오류율과 기 설정된 임계치를 비교하여 건물에서 활성화된 사물 인터넷 장치와 상호 작용이 가능한 출력 음성 신호를 인식하는 전자 장치. |