| 번호 | 청구항 |
|---|---|
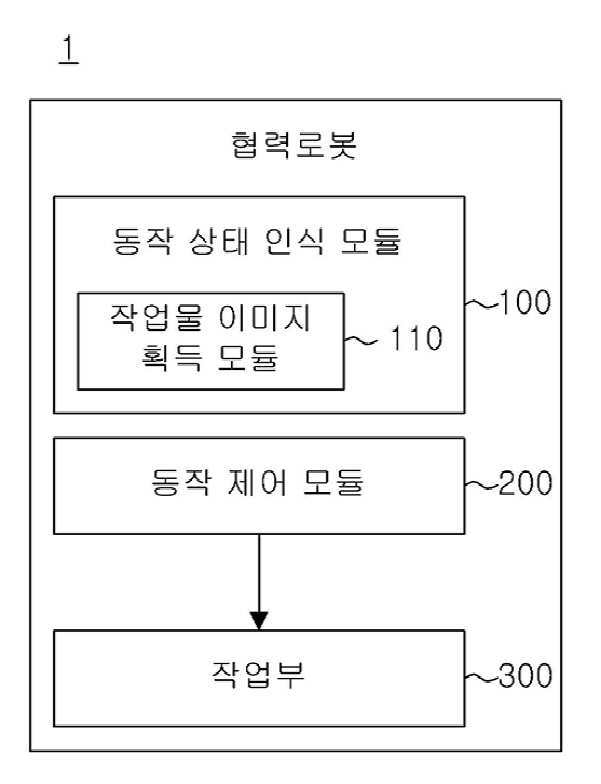
| 1 | 사용자의 동작을 인식하는 동작 상태 인식 모듈 및상기 동작 상태 인식 모듈로 수집되는 사용자의 동작에 따라 작업을 수행하도록 구비되는 협력로봇 작업부의 동작을 제어하는 동작 제어 모듈을 포함하는 휴머노이드 로봇이 사용자의 동작에 따라 함께 동작하여 협업할 수 있도록 제어하는 협력로봇 제어 시스템에 있어서,상기 동작 상태 인식 모듈은,휴머노이드 로봇의 전방에 구비되어 작업부에 거치된 작업물의 이미지를 촬영하여 데이터로 변환하는 작업물 이미지 획득 모듈을 포함하고,상기 동작 제어 모듈은,상기 작업물 이미지 획득 모듈을 통해 촬영된 작업부에 거치된 작업물의 각도에 따른 작업물 이미지의 범위를 토대로 작업부의 동작을 제어하고,상기 동작 제어 모듈은,상기 동작 상태 인식 모듈을 통해 인식되는 사용자의 동작에 관한 데이터를 바탕으로 도출되는 Q-학습 단계에서 산출된 정책(π)에 의해 작업부를 제어하고,상기 Q-학습 단계에서 산출되는 정책은,하기 [수학식 1]을 통해 도출되고,상기 작업부의 동작은,작업물의 상태(s)에서 Q 함수의 값이 가장 높은 작업부의 동작 모드(a)를 수행하고,상기 Q-학습 단계는, 작업부의 수행 단계에서 수행되는 모드의 동작에 사용되는 Q 값을 업데이트 하여 이후 수행될 작업부의 동작에 대한 보상 정책을 수립하는 Q-강화 학습 단계를 포함하고,상기 Q-강화 학습 단계는,하기 [수학식 2]로 도출되고,상기 Q 값은,하기 [수학식 3]으로 업데이트 되는 것을 특징으로 하는 Q-학습 기반의 협력로봇 제어 시스템[수학식 1](여기서, π 는 정책, Q 는 동작가치 함수, s 는 작업물의 상태, a 는 로봇의 동작, A는 모든 작업부 동작의 집합.)[수학식 2](는 현재 상태에서 다음 상태로 가는 로봇 동작에 대한 보상을 의미하며, , , 의 는 작업부의 동작 횟수(iteration time)을 의미한다.또한, 은 작업물의 동작 이후 상태이며 일 때 작업부가 로 동작한 후의 상태이다.이때, 상기 과 의 차이는 동작의 주체이며, 와 은 사용자의 동작 이후의 상태이며 동작 제어 모듈을 통해 작업부를 제어하는 입력값이고, 은 작업부의 동작 이후의 상태이다.또한, 여기서 는 학습율, 는 다음 상태의 Q값에 대한 영향을 감소하는 감가율이며, , 모두 0에서 1 사이의 값을 사용한다.또한, 는 다음 상태의 작업부의 동작 중 최대 Q값을 의미한다.)[수학식 3] |
| 2 | 삭제 |
| 3 | 삭제 |
| 4 | 삭제 |
| 5 | 삭제 |
| 6 | 제 1 항에 있어서,상기 Q-학습 기반의 협력로봇 제어 시스템은,작업부의 동작을 검토하는 정확도 검증 모듈을 더 포함하고,상기 정확도 검증 모듈은, [수학식 4]를 수행하여 작업부의 동작에 대한 정확성을 판별하는 것을 특징으로 하는 Q-학습 기반의 협력로봇 제어 시스템[수학식 4] |
| 7 | 제 6 항에 있어서,상기 Q-학습 기반의 협력로봇 제어 시스템은,Q-강화 학습 단계 이후 작업부의 동작을 정립하는 최종 정책 수립 단계를 더 포함하고,상기 최종 정책 수립 단계는, [수학식 5]에 의해 결정되어, 작업부에 동작을 수행하도록 하는 것을 특징으로 하는 Q-학습 기반의 협력로봇 제어 시스템[수학식 5](는 일 때의 Q 함수) |