| 번호 | 청구항 |
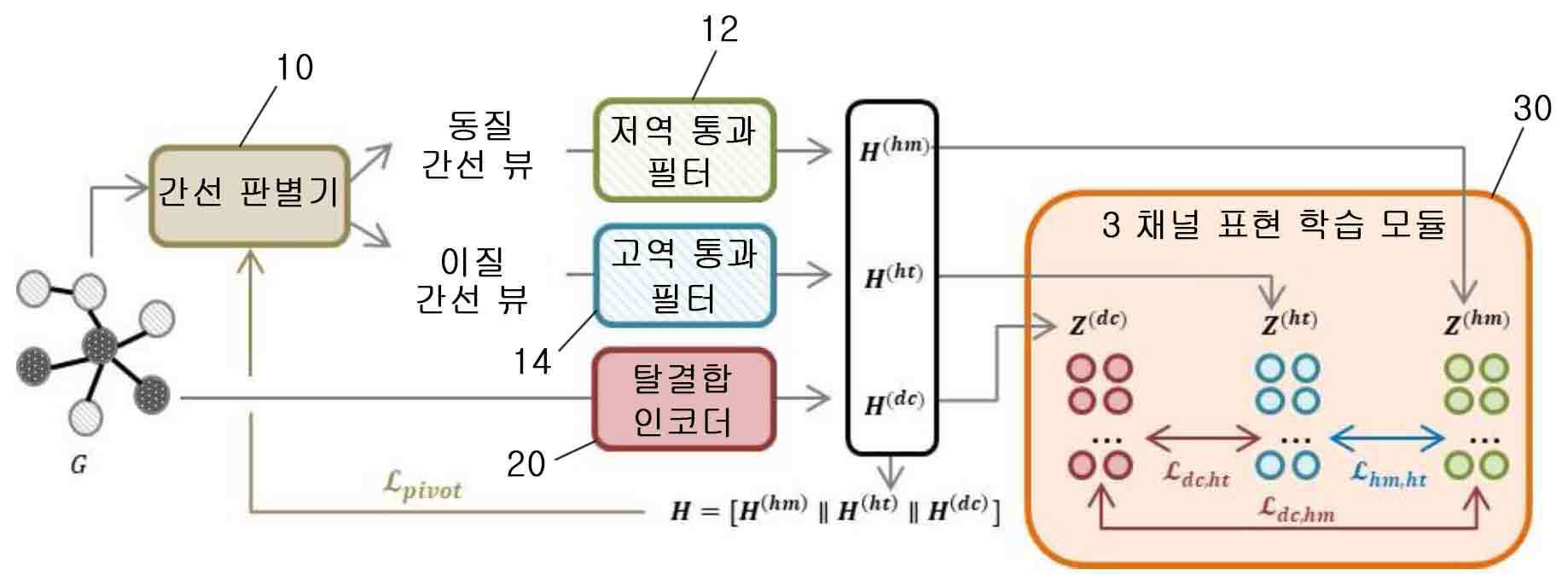
|---|---|
| 1 | 비지도 그래프 표현 학습 모델로서, 입력 그래프의 각 간선의 동질성 수준을 예측하고, 동질 간선 뷰(Homophilic View) 및 이질 간선 뷰(Heterophilic View)를 생성하는 간선 판별기(Edge Discriminator); 상기 동질 간선 뷰로부터 동질성 정점 표현을 생성하는 저역 통과 필터(Low-pass Filter);상기 이질 간선 뷰로부터 이질성 정점 표현을 생성하는 고역 통과 필터(High-pass Filter); 상기 입력 그래프의 인접 행렬과 특징 행렬을 독립적으로 학습하여 탈결합 정점 표현을 생성하는 탈결합 인코더(Decoupling Encoder); 및상기 동질성 정점 표현, 상기 이질성 정점 표현 및 상기 탈결합 정점 표현을 대조 학습하는 3 채널 표현 학습 모듈(3-Channel Representation Learning Module);을 포함하는, 비지도 그래프 표현 학습 모델. |
| 2 | 제1항에 있어서, 상기 간선 판별기는 다중 신경망을 사용하여 각 간선의 동질성 수준을 예측하고, 각 간선에 대한 동질성 피벗 앵커 랭킹 손실(Pivot-anchored Ranking Loss) 값 및 이질성 피벗 앵커 랭킹 손실 값을 합한 피벗 앵커 랭킹 손실로 학습되는 것을 특징으로 하는, 비지도 그래프 표현 학습 모델. |
| 3 | 제1항에 있어서, 상기 저역 통과 필터와 상기 고역 통과 필터는 다층 퍼셉트론(MLP)을 포함하며, 상기 동질성 정점 표현은 정규화된 인접 행렬을 사용하고 상기 이질성 정점 표현은 정규화된 라플라스 행렬을 사용하는 것을 특징으로 하는, 비지도 그래프 표현 학습 모델. |
| 4 | 제1항에 있어서, 상기 대조 학습은 InfoNCE 손실 함수를 사용하여 양성 샘플 간의 유사도를 극대화하고 음성 샘플 간의 유사도를 최소화하는 단계를 포함하는 것을 특징으로 하는, 비지도 그래프 표현 학습 모델. |
| 5 | 제1항에 있어서, 상기 3 채널 표현 학습 모듈은 상기 동질성 정점 표현, 상기 이질성 정점 표현 및 상기 탈결합 정점 표현 간 공유 정보를 얻기 위하여 데이터셋의 성질에 따라 상기 특징 행렬의 유사도를 사용한 특징 정보 기반 k-최근접 이웃(kNN) 샘플링 및 상기 인접 행렬의 유사도를 사용한 구조 정보 기반 k-최근접 이웃 샘플링을 수행하여 양성 샘플을 선택하는 단계를 포함하는 것을 특징으로 하는, 비지도 그래프 표현 학습 모델. |
| 6 | 제5항에 있어서, 상기 데이터셋의 성질은 상기 데이터셋의 규모 및 밀집도를 기초로 하고, 데이터셋의 규모가 작고 밀집도가 낮을수록 특징 정보 기반 kNN 샘플링 방법이 선택되고, 데이터셋의 규모가 크고 밀집도가 높을수록 구조 정보 기반 kNN 샘플링 방법이 선택되는 것을 특징으로 하는, 비지도 그래프 표현 학습 방법. |
| 7 | 비지도 그래프 표현 학습 방법으로서, 입력 그래프의 각 간선의 동질성 수준을 예측하는 간선 판별기(Edge Discriminator)를 구축하는 단계;상기 간선 판별기를 통해 동질 간선 뷰(Homophilic View) 및 이질 간선 뷰(Heterophilic View)를 생성하는 단계;저역 통과 필터(Low-pass Filter)를 사용하여 상기 동질 간선 뷰로부터 동질성 정점 표현을 생성하는 단계;고역 통과 필터(High-pass Filter)를 사용하여 상기 이질 간선 뷰로부터 이질성 정점 표현을 생성하는 단계; 탈결합 인코더(Decoupling Encoder)를 통해 상기 입력 그래프의 인접 행렬과 특징 행렬을 독립적으로 학습하여 탈결합 정점 표현을 생성하는 단계; 및3 채널 표현 학습 모듈(3-Channel Representation Learning Module)을 통해 상기 동질성 정점 표현, 상기 이질성 정점 표현 및 상기 탈결합 정점 표현을 대조 학습하는 단계;를 포함하는, 비지도 그래프 표현 학습 방법. |
| 8 | 제7항에 있어서, 상기 간선 판별기는 다중 신경망을 사용하여 각 간선의 동질성 수준을 예측하고, 각 간선에 대한 동질성 피벗 앵커 랭킹 손실(Pivot-anchored Ranking Loss) 값 및 이질성 피벗 앵커 랭킹 손실 값을 합한 피벗 앵커 랭킹 손실로 학습되는 것을 특징으로 하는, 비지도 그래프 표현 학습 방법. |
| 9 | 제7항에 있어서, 상기 저역 통과 필터와 상기 고역 통과 필터는 다층 퍼셉트론(MLP)을 포함하며, 상기 동질성 정점 표현은 정규화된 인접 행렬을 사용하고 상기 이질성 정점 표현은 정규화된 라플라스 행렬을 사용하는 것을 특징으로 하는, 비지도 그래프 표현 학습 방법. |
| 10 | 제7항에 있어서, 상기 대조 학습은 InfoNCE 손실 함수를 사용하여 양성 샘플 간의 유사도를 극대화하고 음성 샘플 간의 유사도를 최소화하는 단계를 포함하는 것을 특징으로 하는, 비지도 그래프 표현 학습 방법. |
| 11 | 제7항에 있어서, 상기 3 채널 표현 학습 모듈은 상기 동질성 정점 표현, 상기 이질성 정점 표현 및 상기 탈결합 정점 표현 간 공유 정보를 얻기 위하여 데이터셋의 성질에 따라 상기 특징 행렬의 유사도를 사용한 특징 정보 기반 k-최근접 이웃(kNN) 샘플링 및 상기 인접 행렬의 유사도를 사용한 구조 정보 기반 k-최근접 이웃 샘플링을 수행하여 양성 샘플을 선택하는 단계를 포함하는 것을 특징으로 하는, 비지도 그래프 표현 학습 방법. |
| 12 | 제11항에 있어서, 상기 데이터셋의 성질은 상기 데이터셋의 규모 및 밀집도를 기초로 하고, 데이터셋의 규모가 작고 밀집도가 낮을수록 특징 정보 기반 kNN 샘플링 방법이 선택되고, 데이터셋의 규모가 크고 밀집도가 높을수록 구조 정보 기반 kNN 샘플링 방법이 선택되는 것을 특징으로 하는, 비지도 그래프 표현 학습 방법. |
| 13 | 컴퓨터에 의해 판독 가능하고, 상기 컴퓨터에 의해 동작 가능한 프로그램 명령어를 저장하는 컴퓨터 판독가능한 기록매체로서, 상기 프로그램 명령어가 상기 컴퓨터의 프로세서에 의해 실행되는 경우 상기 프로세서가 제7항 내지 제12항 중 어느 하나의 항에 따른 비지도 그래프 표현 학습 방법을 수행하게 하는 컴퓨터 판독가능 기록매체. |