| 번호 | 청구항 |
|---|---|
| 4 | 제3항에 있어서,상기 도메인 분리부는 상기 결정된 도메인 수에 관련된 클러스터의 중심점 주변 텍스트를 분석하여 도메인들 각각에 레이블을 할당하여 상기 학습 데이터를 복수의 도메인으로 분리하는 것을 특징으로 하는 도메인 적응형 언어모델 처리 장치. |
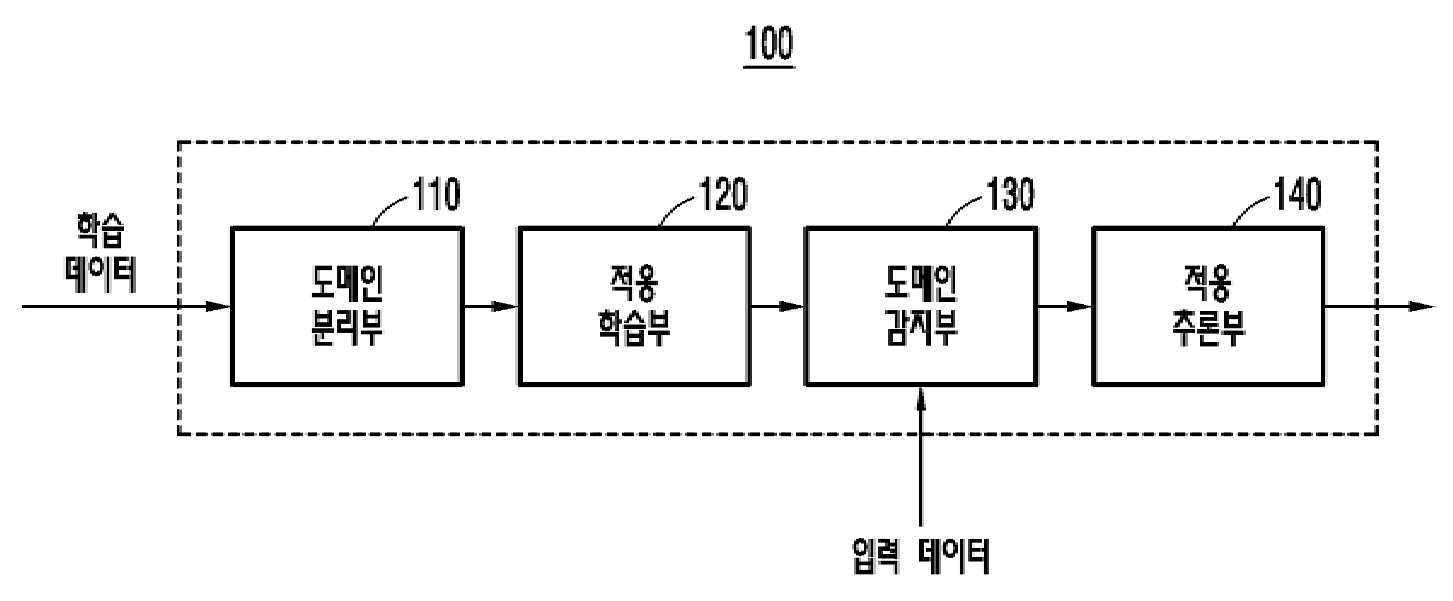
| 1 | 학습 데이터에 대한 학습 특징을 추출하고, 상기 추출된 학습 특징에 기반하여 도메인 수를 결정하며, 상기 결정된 도메인 수에 기반하여 상기 학습 데이터를 복수의 도메인으로 분리하는 도메인 분리부;상기 분리된 복수의 도메인 각각에 대하여 적응 학습 모델을 적용하여 상기 분리된 복수의 도메인 각각에 대응하는 도메인 별 언어 모델을 학습하는 적응 학습부;입력 데이터에 대한 입력 특징을 추출하고, 상기 추출된 입력 특징에 기반하여 상기 분리된 복수의 도메인에서 선택된 복수의 도메인으로 상기 입력 데이터를 분리하는 도메인 감지부; 및 상기 선택된 복수의 도메인 각각에 대응하여 학습된 도메인 별 언어 모델을 이용하여 복수의 추론 결과를 도출하고, 상기 도출된 복수의 추론 결과를 앙상블(ensemble) 학습하여 상기 입력 데이터에 대한 앙상블 추론 결과를 출력하는 적응 추론부를 포함하는 것을 특징으로 하는도메인 적응형 언어모델 처리 장치. |
| 2 | 제1항에 있어서,상기 도메인 분리부는 상기 학습 데이터와 관련하여 의료 텍스트 데이터 셋의 텍스트 데이터를 로드하고, 상기 로드된 텍스트 데이터를 전처리하여 분석 데이터로 변환하고, 상기 변환된 분석 데이터에서 문장 임베딩 모델(sentence transformer model)을 사용하여 상기 텍스트 데이터의 벡터 표현을 생성하여 상기 생성된 벡터 표현으로 상기 학습 특징을 추출하되, 상기 추출된 학습 특징에 대하여 차원 축소 기법을 적용하여 2차원 데이터로 축소하는 것을 특징으로 하는 도메인 적응형 언어모델 처리 장치. |
| 3 | 제2항에 있어서,상기 도메인 분리부는 상기 학습 특징에 대하여 계층적 클러스터링 알고리즘을 사용하여 거리 값을 산출하고, 상기 산출된 거리 값에 대하여 복수의 거리 임계 값으로 구분하여 클러스터링을 수행하여 복수의 클러스터를 결정하며, 상기 결정된 복수의 클러스터에 대하여 실루엣 점수로 내부 평가 지표를 산출하고, 상기 산출된 내부 평가 지표에 기반하여 상기 도메인 수를 결정하는 것을 특징으로 하는 도메인 적응형 언어모델 처리 장치. |
| 5 | 제1항에 있어서,상기 적응 학습부는 로우 랭크 행렬(Low Rank Matrix)의 집합을 이용하는 로우랭크적응(Low Rank Adaptation, LoRA)에 기반하여 상기 학습 데이터에 관련된 쿼리 데이터가 입력되면 상기 복수의 도메인 중에서 상기 쿼리 데이터에 대한 응답 데이터가 포함되는 도메인을 확인하여 상기 응답 데이터가 출력되도록 상기 도메인 별 언어 모델을 학습하는 것을 특징으로 하는 도메인 적응형 언어모델 처리 장치. |
| 6 | 제1항에 있어서,상기 도메인 감지부는 상기 입력 데이터를 구성하는 텍스트 데이터를 토큰화하고, 상기 토큰화된 텍스트 데이터를 인코딩하여 상기 입력 특징을 추출하고, 상기 추출된 입력 특징에 기반하여 상기 복수의 도메인에 대한 상기 텍스트 데이터의 확률을 산출하고, 상기 산출된 확률에 기반하여 상기 분리된 복수의 도메인에서 선택된 복수의 도메인으로 상기 입력 데이터를 분리하는 것을 특징으로 하는 도메인 적응형 언어모델 처리 장치. |
| 7 | 제1항에 있어서,상기 도메인 감지부는 상기 입력 데이터를 구성하는 텍스트 데이터를 토큰화하고, 상기 토큰화된 텍스트 데이터를 인코딩하여 상기 입력 특징을 추출하고, 상기 추출된 입력 특징에 기반하여 상기 복수의 도메인에 대한 상기 텍스트 데이터의 확률을 산출하고, 상기 산출된 확률에 기반하여 상기 분리된 복수의 도메인에서 선택된 복수의 도메인으로 상기 입력 데이터를 분리하는 것을 특징으로 하는 도메인 적응형 언어모델 처리 장치. |
| 8 | 제7항에 있어서,상기 적응 추론부는 상기 학습 데이터 및 상기 입력 데이터가 의료 텍스트 데이터인 경우에, 상기 복수의 도메인 각각이 서로 다른 의료 지식 모델에 기반한 응답을 제공하도록 상기 입력 데이터에 기반하여 상기 도메인 별 언어 모델들에서의 출력을 앙상블 학습하여 상호 보완함에 따라 상기 의료 텍스트 데이터에 기반하여 구분되는 의료 하위 영역에서의 추론 결과를 출력하는 것을 특징으로 하는 도메인 적응형 언어모델 처리 장치. |
| 9 | 도메인 분리부에서, 학습 데이터에 대한 학습 특징을 추출하고, 상기 추출된 학습 특징에 기반하여 도메인 수를 결정하며, 상기 결정된 도메인 수에 기반하여 상기 학습 데이터를 복수의 도메인으로 분리하는 단계;적응 학습부에서, 상기 분리된 복수의 도메인 각각에 대하여 적응 학습 모델을 적용하여 상기 분리된 복수의 도메인 각각에 대응하는 도메인 별 언어 모델을 학습하는 단계;도메인 감지부에서, 입력 데이터에 대한 입력 특징을 추출하고, 상기 추출된 입력 특징에 기반하여 상기 분리된 복수의 도메인에서 선택된 복수의 도메인으로 상기 입력 데이터를 분리하는 단계; 및 적응 추론부에서, 상기 선택된 복수의 도메인 각각에 대응하여 학습된 도메인 별 언어 모델을 이용하여 복수의 추론 결과를 도출하고, 상기 도출된 복수의 추론 결과를 앙상블(ensemble) 학습하여 상기 입력 데이터에 대한 앙상블 추론 결과를 출력하는 단계를 포함하는 것을 특징으로 하는도메인 적응형 언어모델 처리 방법. |
| 10 | 제9항에 있어서,상기 분리된 복수의 도메인 각각에 대하여 적응 학습 모델을 적용하여 상기 분리된 복수의 도메인 각각에 대응하는 도메인 별 언어 모델을 학습하는 단계는,로우 랭크 행렬(Low Rank Matrix)의 집합을 이용하는 로우랭크적응(Low Rank Adaptation, LoRA)에 기반하여 상기 학습 데이터에 관련된 쿼리 데이터가 입력되면 상기 복수의 도메인 중에서 상기 쿼리 데이터에 대한 응답 데이터가 포함되는 도메인을 확인하여 상기 응답 데이터가 출력되도록 상기 도메인 별 언어 모델을 학습하는 단계를 포함하는 것을 특징으로 하는 도메인 적응형 언어모델 처리 방법. |