| 번호 | 청구항 |
|---|---|
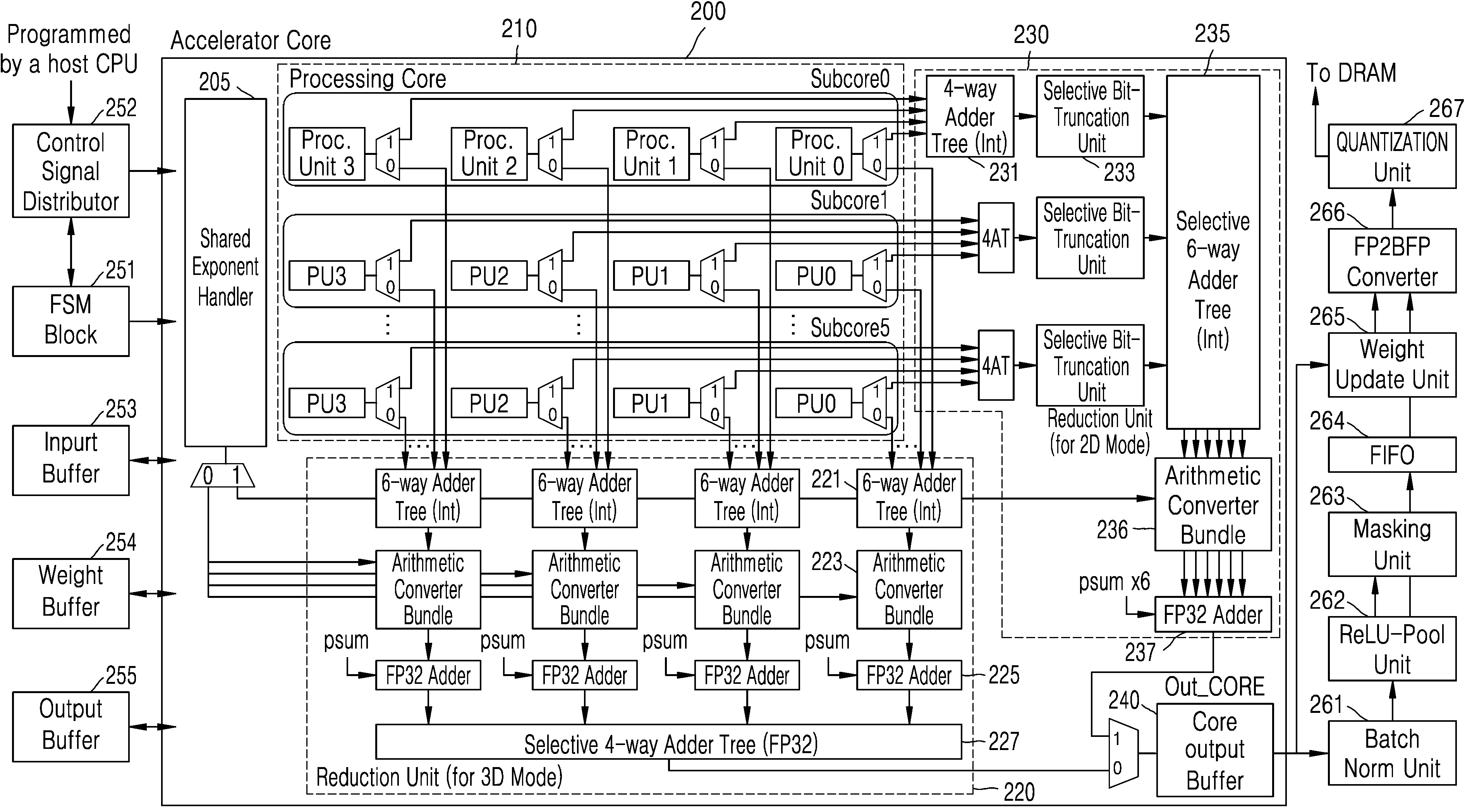
| 1 | 심층 신경망의 연산을 수행하는 하드웨어 가속기에 있어서,제1 텐서(tensor)의 부호 및 맨티서(mantissa)와 제2 텐서의 부호 및 맨티서 간의 1D 서브-워드 병렬 처리(1 dimensional sub-word parallelism)를 수행하는 복수의 멀티플라이어(multiplier)들을 포함하는 프로세싱 코어;상기 복수의 멀티플라이어들의 연산 결과를 출력하는, 2D 동작 모드(2 dimensional operation mode)에서 동작하는 제1 처리 장치; 및상기 복수의 멀티플라이어의 연산 결과를 채널 방향으로 누적하여 상기 누적된 연산 결과를 출력하는, 3D 동작 모드(3 dimensional operation mode)에서 동작하는 제2 처리 장치를 포함하는, 하드웨어 가속기. |
| 2 | 제1항에 있어서,상기 복수의 멀티플라이어들의 제1 그룹은 상기 제1 텐서에 포함되는 제1 값의 일련의 서브-워드들과, 상기 제2 텐서에 포함되는 제2 값의 일련의 서브-워드들 중 제1 서브-워드 간의 곱셈 연산을 수행하고,상기 복수의 멀티플라이어들의 제2 그룹은 상기 제1 값의 일련의 서브-워드들과, 상기 제2 값의 일련의 서브-워드들 중 제2 서브-워드 간의 곱셈 연산을 수행하는, 하드웨어 가속기. |
| 3 | 제1항에 있어서,상기 심층 신경망의 연산에서, 연산 결과가 채널 방향으로 누적되지 않는, 가중치 경사 연산, DW(depthwise) 컨볼루션, 팽창된(dilated) 컨볼루션, 또는 업(up) 컨볼루션을 수행하는 경우 상기 하드웨어 가속기는 상기 2D 동작 모드로 동작하고,상기 심층 신경망의 연산에서, 연산 결과가 채널 방향으로 누적되는, 컨볼루션, 포인트와이즈 컨볼루션, 또는 완전 연결 레이어 연산을 수행하는 경우 상기 하드웨어 가속기는 상기 3D 동작 모드로 동작하는, 하드웨어 가속기. |
| 4 | 제1항에 있어서,상기 프로세싱 코어는,6개의 서브 코어들을 포함하고,상기 서브 코어들 각각은 4개의 프로세싱 유닛들을 포함하고,상기 프로세싱 유닛들 각각은 4개의 프로세싱 엘리먼트들을 포함하고,상기 프로세싱 엘리먼트들 각각은 9개의 멀티플라이어들을 포함하는, 하드웨어 가속기. |
| 5 | 제4항에 있어서,상기 심층 신경망의 Conv3 레이어 연산의 경우,상기 제1 텐서의 부호 및 맨티서의 크기가 16 비트이면, 하나의 서브 코어를 구성하는 4개의 프로세싱 유닛들에 상기 Conv3 레이어의 하나의 입력 채널에 대응되는 상기 제1 텐서가 브로드캐스팅되고,상기 제1 텐서의 부호 및 맨티서의 크기가 8 비트이면, 하나의 서브 코어를 구성하는 4개의 프로세싱 유닛들에 상기 Conv3 레이어의 2개의 입력 채널들에 대응되는 상기 제1 텐서가 브로드캐스팅되고,상기 제1 텐서의 부호 및 맨티서의 크기가 4 비트이면, 하나의 서브 코어를 구성하는 4개의 프로세싱 유닛들이 상기 Conv3 레이어의 4개의 입력 채널들에 대응되는 상기 제1 텐서가 브로드캐스팅되는, 하드웨어 가속기. |
| 6 | 제4항에 있어서,상기 심층 신경망의 Conv3 레이어 연산의 경우,상기 제2 텐서의 부호 및 맨티서의 크기가 16 비트이면, 하나의 서브 코어를 구성하는 4개의 프로세싱 유닛들에 상기 Conv3 레이어의 하나의 출력 채널에 대응되는 상기 제2 텐서가 분배되고,상기 제2 텐서의 부호 및 맨티서의 크기가 8 비트이면, 하나의 서브 코어를 구성하는 4개의 프로세싱 유닛들에 상기 Conv3 레이어의 2개의 출력 채널들에 대응되는 상기 제2 텐서가 분배되고,상기 제2 텐서의 부호 및 맨티서의 크기가 4 비트이면, 하나의 서브 코어를 구성하는 4개의 프로세싱 유닛들에 상기 Conv3 레이어의 4개의 출력 채널들에 대응되는 상기 제2 텐서가 분배되는, 하드웨어 가속기. |
| 7 | 제4항에 있어서,상기 제1 처리 장치는:상기 6개의 서브 코어들 각각에 포함되는 4개의 프로세싱 유닛들의 출력들을 합산하는 6개의 4-way 가산기 트리들;상기 4-way 가산기 트리들의 출력들 각각을 기설정된 비트를 갖도록 반올림 처리하는 6개의 비트 절단기들;상기 비트 절단기들의 출력들을 선택적으로 합산하는 선택적 6-way 가산기 트리;상기 선택적 6-way 가산기 트리의 출력 및 공유 지수 핸들러의 출력에 기초하여 FP32 부분 합 데이터를 출력하는 산술 변환기; 및상기 FP32 부분 합 데이터를 누적하는 누적기를 포함하는, 하드웨어 가속기. |
| 8 | 제4항에 있어서,상기 제2 처리 장치는:각각이 서로 다른 서브 코어들 내의 상호 대응되는 프로세싱 유닛들의 출력을 합산하는 4개의 6-way 가산기 트리들;상기 6-way 가산기 트리들의 출력들 및 공유 지수 핸들러의 출력에 기초하여 FP32 부분 합 데이터를 출력하는 4개의 산술 변환기들;상기 FP32 부분 합 데이터를 누적하는 4개의 누적기들; 및상기 누적기들의 출력들을 선택적으로 합산하는 선택적 4-way 가산기 트리를 포함하는, 하드웨어 가속기. |
| 9 | 제4항에 있어서,상기 프로세싱 유닛들 각각은:곱셈 연산을 수행하는 상기 9개의 멀티플라이어들;상기 9개의 멀티플라이어들의 출력을 합산하는 9-way 가산기 트리; 및상기 9-way 가산기 트리의 출력을 기 정의된 비트만큼 시프팅하는 선택적 시프트 로직 회로를 포함하는, 하드웨어 가속기. |
| 10 | 제1항에 있어서,상기 제1 텐서의 공유 지수와 상기 제2 텐서의 공유 지수를 처리하는 공유 지수 핸들러를 더 포함하는, 하드웨어 가속기. |
| 11 | 제1항에 있어서,상기 프로세싱 코어는,제어 신호에 대응되는 자료형의 숫자를 이용하여 연산을 수행하고,상기 자료형은, 고정 소수점 형태의 제1 자료형, 정수만 갖는 제2 자료형, 부호와 정수를 갖는 제3 자료형, 지수를 공유하는 실수 형태의 제4 자료형을 포함하는, 하드웨어 가속기. |
| 12 | 제1항에 있어서,상기 제1 텐서의 공유 지수의 크기 및 상기 제2 텐서의 공유 지수의 크기는 8 비트이고,상기 제1 텐서의 부호 및 맨티서의 크기 또는 상기 제2 텐서의 부호 및 맨티서의 크기는 4 비트, 8 비트 및 16 비트 중 하나이고,상기 제1 텐서의 부호 및 맨티서의 크기 또는 상기 제2 텐서의 부호 및 맨티서의 크기에 기초하여, 상기 제1 텐서 및 상기 제2 텐서가 상기 프로세싱 코어에 맵핑되는, 하드웨어 가속기. |
| 13 | 제12항에 있어서,상기 심층 신경망의 학습의 포워드 패스 단계, 백워드 패스 단계, 또는 가중치 업데이트 단계에 기초하여, 상기 제1 텐서의 부호 및 맨티서의 크기 또는 상기 제2 텐서의 부호 및 맨티서의 크기가 결정되는, 하드웨어 가속기. |
| 14 | 제1항에 있어서,가중치 업데이트 단계에서 상기 제1 처리 장치의 출력 값을 출력하고, 포워드 패스 및 백워드 패스 단계에서 상기 제2 처리 장치의 출력 값을 출력하는 코어 출력 버퍼를 더 포함하는, 하드웨어 가속기. |
| 15 | 제14항에 있어서,코어 출력 버퍼의 출력에 기초하여 배치 정규화를 수행하는 배치 정규화 회로;상기 배치 정규화 회로의 출력에 기초하여 ReLU 함수 값 및 풀링 값을 수행하는 ReLU-Pool 회로;ReLU-Pool 회로의 출력을 저장하여 출력하는 FIFO 회로;부동 소수점 형태의 FIFO 회로의 출력의 자료형을 블록 부동 소수점 형태로 변환하는 FP2BFP 컨버터 회로; 및기 정의된 정밀도에 따라 FP2BFP 컨버터의 출력을 양자화하는 양자화 회로를 더 포함하는, 하드웨어 가속기. |
| 16 | 제1항에 있어서,상기 복수의 멀티플라이어들 각각은:제1 입력 단을 통해 이전 제2 텐서를 수신하고, 제2 입력 단을 통해 현재 제2 텐서를 수신하고, 유지 신호에 응답하여 상기 현재 제2 텐서 또는 상기 제1 텐서를 출력하는 제1 MUX;5 비트의 상기 제1 텐서 및 5 비트의 상기 제2 텐서를 피연산자로 하는 곱셈 연산을 수행하는 멀티플라이어 코어;상기 멀티플라이어 코어의 출력을 저장하는 제1 레지스터;상기 제1 MUX의 출력을 저장하는 제2 레지스터; 및제1 입력 단을 통해 제2 레지스터에 저장된 값을 수신하고, 제2 입력 단을 통해 상기 제1 MUX의 출력을 수신하고, 우회 신호에 응답하여 상기 제2 레지스터에 저장된 값 또는 상기 제1 MUX의 출력을 출력하는 제2 MUX를 포함하는, 하드웨어 가속기. |
| 17 | 제16항에 있어서,상기 유지 신호에 의해 형성된 피드백 루프를 통해 상기 제2 레지스터에 저장된 값이 유지되는, 하드웨어 가속기. |
| 18 | 심층 신경망의 학습 및 추론을 수행하는 전자 장치에 있어서,복수의 멀티플라이어들을 이용하여 제1 텐서의 부호 및 맨티서와 제2 텐서의 부호 및 맨티서 간의 1D 서브-워드 병렬 처리(1 dimensional sub-word parallelism)를 수행하고, 공유 지수 핸들러를 이용하여 상기 제1 텐서의 공유 지수 및 상기 제2 텐서의 공유 지수 간의 처리를 수행하는, 하드웨어 가속기;상기 심층 신경망의 레이어들의 수, 레이어들의 종류, 텐서들의 모양, 텐서들의 차원, 동작 모드, 비트 정밀도, 배치 정규화 종류, 풀링 레이어 종류, 및 ReLU 함수 종류 중 적어도 하나를 포함하는 심층 신경망 정보에 기초하여 상기 하드웨어 가속기를 제어하는, 적어도 하나의 인스트럭션을 실행하는 적어도 하나의 프로세서; 및상기 적어도 하나의 인스트럭션 및 상기 심층 신경망을 저장하는 메모리를 포함하는, 전자 장치. |
| 19 | 제16항에 있어서,상기 적어도 하나의 프로세서는,사용자 입력에 기초하여 상기 심층 신경망의 비트 정밀도 및 블록 크기 중 적어도 하나를 획득하고,상기 획득된 비트 정밀도 및 블록 크기 중 적어도 하나에 기초하여, 상기 제1 텐서 및 상기 제2 텐서에 대한 비트 정밀도 및 블록 크기 중 적어도 하나를 세팅하고,상기 세팅에 기초하여 상기 하드웨어 가속기가 상기 심층 신경망을 학습하도록 제어하는, 상기 적어도 하나의 인스트럭션을 실행하는, 전자 장치. |
| 20 | 제16항에 있어서,상기 하드웨어 가속기는, 상기 복수의 멀티플라이어들의 연산 결과를 채널 방향으로 누적하지 않고 상기 연산 결과를 출력하는 2D 동작 모드, 또는 상기 복수의 멀티플라이어들의 연산 결과를 채널 방향으로 누적하여 상기 누적된 연산 결과를 출력하는 3D 동작 모드로 동작하는, 전자 장치. |