| 번호 | 청구항 |
|---|---|
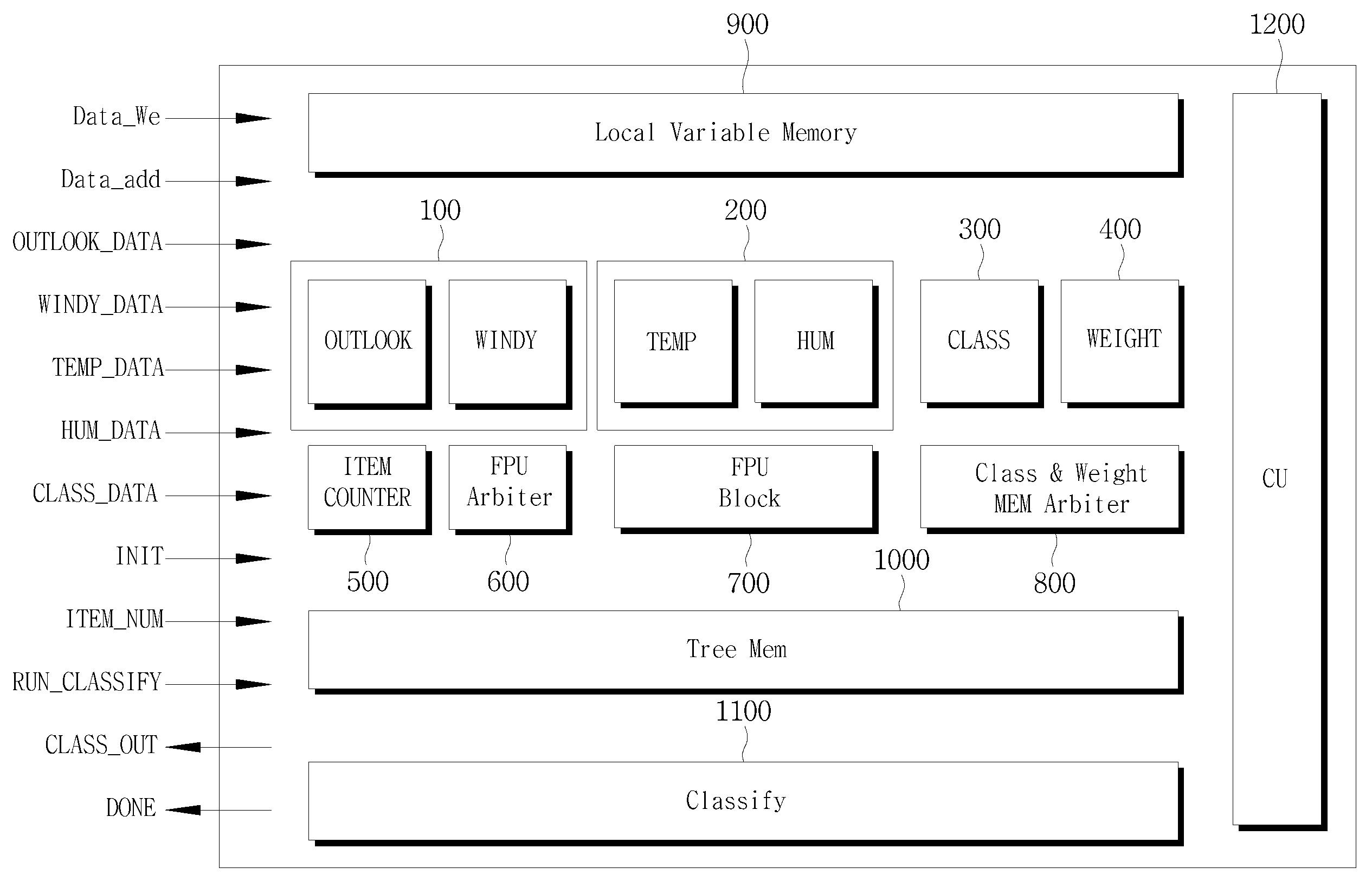
| 1 | 이산형 자료의 처리를 담당하는 모듈들을 갖는 이산형 자료 처리부;연속형 자료의 처리를 담당하는 모듈들을 갖는 연속형 자료 처리부;학습할 데이터의 클래스 정보를 처리하는 클래스 정보 처리부;학습할 데이터의 가중치를 저장하는 가중치 저장부 및 학습 데이터 전체의 가중치(Weight) 합을 구하는 가중치 처리부;FPU(Floating Point Unit)의 사용권을 제어하는 FPU 아비터 및 부동 소수점 연산을 수행하는 FPU;상기 클래스 정보 처리부의 내부 클래스 메모리와 가중치 저장부의 접근을 제어하기 위한 메모리 아비터;학습의 결과가 트리의 형태로 저장되는 학습 결과 저장부 및 학습이 완료된 데이터를 대상으로 분류를 수행하는 데이터 분류부;를 포함하는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 장치. |
| 2 | 제 1 항에 있어서, 상기 이산형 자료 처리부의 이산형 자료의 처리를 담당하는 모듈들은 이산형 속성의 개수에 따라 확장 또는 축소되는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 장치. |
| 3 | 제 2 항에 있어서, 상기 이산형 자료 처리부가 갖는 이산형 자료 처리 모듈은,학습에 필요한 해당 속성의 데이터를 저장하기 위한 메모리와,각 데이터에 따른 가중치 누적합과 데이터 및 클래스에 따른 가중치 누적합 및 알려진 값에 대해서만 클래스에 따른 가중치 누적합을 계산하기 위한 카운터 모듈과,정보량의 이득(Gain) 및 특정 속성을 선택함으로써 얻을 수 있는 정보량(Information) 계산을 수행하는 제어 모듈과,제어 모듈에 종속되어 BaseInfo(데이터 셋에서 클래스 값 빈도별로 classcountlog(classcount) 를 sum 하여, 이값을 knownitemslog(knownitems)로 부터 뺀 후 knownitems로 나눈 값) 연산을 수행하는 제 1 서브 제어 모듈과,제어 모듈에 종속되어 연산을 수행하는 제 2 서브 제어 모듈을 포함하고,여기서, ClassCount는 각 속성별로 Unknown 값(속성값이 기재되어 있지 않거나 지정된 범위를 넘어간 상태)을 제외한 클래스 별 빈도 계산 계수이고, KnownItems는 특성 속성의 값이 기재되어 있지 않은 데이터를 제외한 데이터, n은 특정 속성이 분류되는 종류, N은 데이터의 개수인 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 장치. |
| 4 | 제 1 항에 있어서, 연속형 자료 처리부의 연속형 자료의 처리를 담당하는 모듈들은 연속형 속성의 개수에 따라 확장 또는 축소되는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 장치. |
| 5 | 제 4 항에 있어서, 연속형 자료 처리부가 갖는 연속형 자료 처리 모듈은,학습에 필요한 해당 속성의 데이터를 저장하기 위한 메모리와,연속형 데이터와의 인덱스를 추적하기 위한 포인터를 저장하기 위한 메모리와,특정 기준보다 작은 값 및 큰 값의 가중치 누적합과 기준에 따른 분류 및 클래스에 따른 가중치 누적합을 계산하기 위한 카운터 모듈과,정보량의 이득(Gain) 및 특정 속성을 선택함으로써 얻을 수 있는 정보량(Information) 계산을 수행하는 제어 모듈을 포함하는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 장치. |
| 6 | 제 1 항에 있어서, 클래스 정보 처리부는,각 데이터의 클래스 값을 저장하기 위한 메모리와,각 클래스 값에 따른 가중치 누적합을 계산하기 위한 카운터를 포함하는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 장치. |
| 7 | 제 1 항에 있어서, 데이터 분류부는, 분류 작업을 수행할 때 로컬 변수를 처리하기 위한 스택과,트리 메모리의 노드를 순회하면서 분류를 하고자 하는 데이터에 따라 각 클래스 별로 가중치를 누적시키는 CLASS SUM 모듈을 포함하는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 장치. |
| 8 | 제 1 항에 있어서, 재귀적 호출(Recursive Call)에 의해 실행되는 의사 결정 트리의 학습 과정에서 현재 단계에서 사용하던 각종 변수들이 재귀 호출에서 다시 돌아왔을 때도 참조할 수 있도록 변수들을 스택과 같은 형태로 저장하는 변수 저장부를 더 포함하는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 장치. |
| 9 | 제 1 항에 있어서, 학습 결과 저장부에서의 트리 메모리의 주소 인덱스는 트리 노드의 번호이며,트리를 순회할 수 있도록 자식 노드 및 부모 노드에 대한 참조 주소, 각 노드에서의 분류에 사용되는 속성, 가지 개수, 분류 기준, 노드의 타입, 현재 노드에서의 아이템 개수에 대한 정보를 노드마다 유지하는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 장치. |
| 10 | 의사 결정 트리의 학습과 분류를 위한 장치에서의 학습 과정 제어를 위하여,학습 범위에 있는 이산형 자료 및 연속형 자료에 대한 계수를 수행하는 단계;가장 빈도가 많은 클래스의 아이템 수가 전체 아이템 수와 같거나 일정 수보다 아이템 수가 적은지를 판단하는 단계;이산형 자료 및 연속형 자료에 대한 정보량의 이득(Gain) 및 특정 속성을 선택함으로써 얻을 수 있는 정보량(Info) 계산을 위해 이산형 자료 처리부 및 연속형 자료 처리부를 구동하는 단계;각 속성별로 Gain, Info를 이용해 분류 기준을 선택하는 단계;분류 기준에 따라 트리 노드를 생성하고 학습 데이터를 그룹화하고, 각 그룹별로 가지 노드를 생성하고, 각 그룹별로 재귀 호출하는 단계;모든 가지 노드 별로 재귀 호출 완료 후 현재 노드를 반환하는 단계;를 포함하는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 방법. |
| 11 | 제 10 항에 있어서, 계수를 수행하는 단계에서,이산형 자료 처리부와 연속형 자료 처리부 내부의 메모리, 클래스 메모리, 가중치 저장부의 학습 데이터를 이용하여, 동일한 열(Row)의 데이터를 이용해 해당 데이터와 클래스에 해당하는 카운터에 가중치를 누적하여 더하는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 방법. |
| 12 | 제 10 항에 있어서, 이산형 자료의 정보량의 이득(Gain) 및 특정 속성을 선택함으로써 얻을 수 있는 정보량(Info) 계산을 위하여,상위 모드에서 분류 기준으로 선택되었던 속성인지를 판단하는 단계;KnownItems(특성 속성의 값이 기재되어 있지 않은 데이터를 제외한 데이터) 수를 계산하고, KnownItems이 없을 경우 동작을 중지할지를 결정하는 단계;ThisInfo(특정 속성에서 속성값별로 TotalInfo를 계산하여 누적한 값) 계산을 수행하고, 제 1 서브 모듈로 하여금 BaseInfo(데이터 셋에서 클래스 값 빈도별로 classcountlog(classcount) 를 sum 하여, 이값을 knownitemslog(knownitems)로 부터 뺀 후 knownitems로 나눈 값)를 병렬로 연산하도록 제어하는 단계;제 2 서브 모듈로 하여금 계산을 병렬로 연산하도록 제어하는 단계;ThisInfo와 BaseInfo연산이 끝나면 정보량의 이득(Gain)을 계산하는 단계;를 포함하고,여기서, ClassCount는 각 속성별로 Unknown 값(속성값이 기재되어 있지 않거나 지정된 범위를 넘어간 상태)을 제외한 클래스 별 빈도 계산 계수이고, KnownItems는 특성 속성의 값이 기재되어 있지 않은 데이터를 제외한 데이터, n은 특정 속성이 분류되는 종류, N은 데이터의 개수인 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 방법. |
| 13 | 제 10 항에 있어서, 연속형 자료의 정보량의 이득(Gain) 및 특정 속성을 선택함으로써 얻을 수 있는 정보량(Info) 계산을 위하여,정보량(Info) 계산을 하고자 하는 속성을 기준으로 학습 데이터를 오름차순으로 정렬하고, KnownItems(특성 속성의 값이 기재되어 있지 않은 데이터를 제외한 데이터) , UnknownRate(전체 데이터 중 특성 속성의 값이 기재되어 있지 않은 데이터의 비율), BaseInfo((데이터 셋에서 클래스 값 빈도별로 classcountlog(classcount) 를 sum 하여, 이값을 knownitemslog(knownitems)로 부터 뺀 후 knownitems로 나눈 값)를 계산하는 단계;정보량의 이득(Gain) 연산을 스킵해도 되는 MinSplit(연속형 속성에서 split 지점으로 삼을 수 있는 최소값) 지점을 계산하기 위한 연산을 수행하는 단계;BestSplitGain(연속형 속성에서 각 지점을 split 지점으로 하였을 때의 Gain에서 가장 높은 값)을 계산하고, 저장된 가중치 합을 이용해서 BestInfoGain(Info Gain중에서 가장 높은 값)의 연산을 수행하는 단계;저장된 데이터 값을 이용해 Bar(분류 수행시의 Split의 기준값)를 계산하는 단계;를 포함하고,여기서, ClassCount는 각 속성별로 Unknown 값(속성값이 기재되어 있지 않거나 지정된 범위를 넘어간 상태)을 제외한 클래스 별 빈도 계산 계수인 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 방법. |
| 14 | 제 13 항에 있어서, 각 학습 데이터를 오름차순으로 정렬한 이후, 정보량(Info) 계산을 하고자 하는 속성을 기준으로 작은 값으로부터, 큰 값으로 옮겨가면서 SplitGain(연속형 속성에서 각 지점을 split 지점으로 하였을 때의 gain)을 연산하는 과정을 포함하고,각 SplitGain을 계산하고, 그 값과 BestSplitGain(연속형 속성에서 각 지점을 split 지점으로 하였을 때의 Gain에서 가장 높은 값)과 비교하여 더 클 경우에 마지막에 연산된 값으로 갱신하고,그때의 기준값보다 작은 값의 가중치 누적합과 큰 값의 가중치 누적값을 갱신하고,그때의 값과, 다음 인덱스의 값을 저장하고, BestSplitGain을 선정한 이후에 SplitInfo(연속형 속성에서 각 지점을 split 지점으로 하였을 때의 information) 및 Bar(분류 수행시의 Split의 기준값)의 연산을 수행하는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 방법. |
| 15 | 제 10 항에 있어서, 의사 결정 트리의 학습과 분류를 위한 장치에서의 분류 과정 제어를 위하여,최상위 노드, 노트 탐색이 끝난 상태인지에 따라 분류 종료 조건을 판단하여, BestClass(분류의 결과 class) 리턴 여부를 결정하는 단계;잎 노드를 참조할 경우, 가중치(Weight)를 통해 ClassSum(BestClass 계산시 비교를 위해 Weight를 축적한 값)을 갱신하고, 노드 포인터를 변경하고 스택 포인터를 감소시키는 단계;잎 노드를 참조하지 않을 경우, 현재 참조 값이 Unknown(특정 속성의 값이 기재되어 있지 않은 데이터)인지에 따라, 아이템을 통해 가중치(Weight)를 갱신할지를 결정하여 스택에 가중치를 저장하고, 스택 포인터를 증가시키는 단계;분류 기준에 따라 다음 노드를 판단하여 노드의 포인터를 변경하고, 다시 상기 최상위 노드이며 노드 탐색이 끝난 상태인지를 판단하는 단계;를 포함하는 것을 특징으로 하는 의사 결정 트리의 학습과 분류를 위한 방법. |