| 번호 | 청구항 |
|---|---|
| 1 | 삭제 |
| 2 | 삭제 |
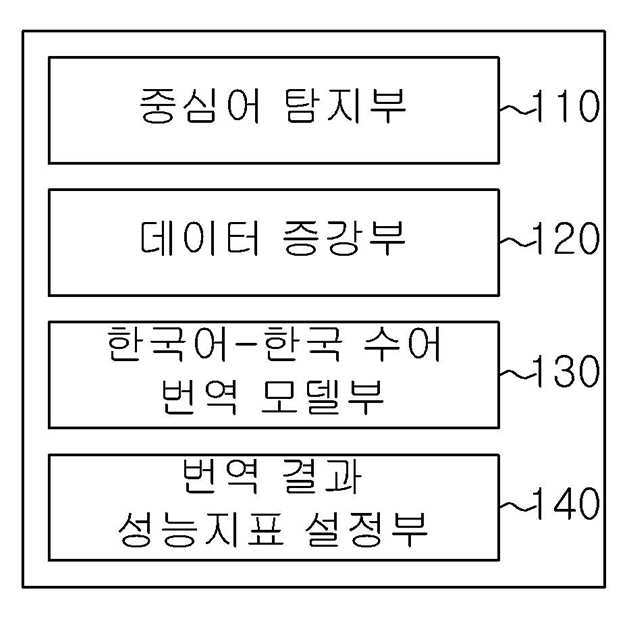
| 3 | 한국어 문장과 한국 수어 문장이 일대일 대응을 이루는 말뭉치 데이터셋에 대해서, 한국어 문장과 한국 수어 문장을 매칭하여 똑같은 단어를 찾는 중심어 탐지부; 상기 중심어 탐지부를 통해 찾아진 똑같은 단어를 기반으로 한국어 문장-한국 수어 문장 말뭉치 데이터셋을 데이터 증강시키는 데이터 증강부; 및상기 데이터 증강부를 통해서 증강된 한국어 문장-한국 수어 문장 말뭉치 데이터셋을 활용해서 딥러닝 기반 기계 번역 모델을 학습 및 검증하는 한국어-한국 수어 번역 모델부를 포함하고, 상기 중심어 탐지부는, 한국어 문장과 한국 수어 문장이 일대일 대응을 이루는 말뭉치 데이터셋에 대해서, 입력된 한국어 문장을 품사 기반으로 토큰화시켜 한국어 문장 토큰으로 변경하고, 입력된 한국 수어 문장은 띄어쓰기 기반으로 토큰화를 시켜 한국 수어 문장 토큰으로 변경하고,상기 중심어 탐지부는, 상기 한국어 문장 토큰과 한국 수어 문장 토큰을 각각 순서대로 윈도우를 기반으로 검색하여, 완전 동일한 토큰일 경우에는 정답을 1로 매핑하고, 비슷한 형태의 토큰일 경우에는 정답을 2로 매핑하고, 나머지 다른 형태의 토큰일 경우에는 정답을 0으로 맵핑하는 것을 특징으로 하는 한국어-한국 수어 번역 데이터 증강 및 평가 장치. |
| 4 | 제3항에 있어서,상기 한국어-한국 수어 번역 모델부를 통해서 나온 번역 결과에 대해 한국어-한국 수어 번역 결과 성능지표를 설정하는 번역 결과 성능지표 설정부를 더 포함하고,상기 한국어-한국 수어 번역 결과 성능지표는,(A는 기계번역으로 번역된 문장의 토큰들, B는 번역 정답 문장의 토큰들)로 정의되는 것을 특징으로 하는 한국어-한국 수어 번역 데이터 증강 및 평가 장치. |
| 5 | 삭제 |
| 6 | 삭제 |
| 7 | 삭제 |
| 8 | 제3항에 있어서, 상기 윈도우를 기반으로 검색하는 공식은, , 에 의해 정의되고, 상기 검색 마진은 한국어 문장 토큰 길이를 한국 수어 문장 토큰 길이로 나눈 값에 해당 토큰 번호를 곱한 값으로 실제 한국어 문장 토큰 길이와 한국 수어 문장 토큰 길이가 다를 경우에 검색 마진을 윈도우 크기에 더하고 빼주면서 검색 범위를 설정하고 검색을 시작하는 것을 특징으로 하는 한국어-한국 수어 번역 데이터 증강 및 평가 장치. |
| 9 | 제3항에 있어서, 상기 중심어 탐지부는, 상기 비슷한 형태의 토큰일 경우에 정답을 2로 매핑하되, 공개된 한국어 문장 토큰 데이터셋과 한국어 문장 토큰-한국 수어 문장 토큰 말뭉치를 포함해서 Word2vec 모델로 유사도를 계산하여 특정 임계값 이상의 유사도에 대해서는 그대로 비슷한 형태의 토큰일 경우로 판단하여 정답을 2로 매핑하고, 임계값 미만의 유사도에 대해서는 다른 형태의 토큰이라고 판단하고 정답을 0으로 매핑하는 것을 특징으로 하는 한국어-한국 수어 번역 데이터 증강 및 평가 장치. |
| 10 | 제3항에 있어서, 상기 중심어 탐지부는,한국어 문장 토큰이 숫자 또는 외래어일 경우에는 숫자 또는 외래어라는 특정 태그로 변환 후 정답을 2로 매핑하는 것을 특징으로 하는 한국어-한국 수어 번역 데이터 증강 및 평가 장치. |
| 11 | 제3항 또는 제9항에 있어서,상기 중심어 탐지부는, 중심어가 매핑된 새로운 데이터셋을 기반으로, 한국어 문장 토큰-중심어가 매핑된 한국어 문장 토큰-한국 수어 문장 토큰의 3가지 타입이 엮인 말뭉치 데이터셋을 만들고, 상기 말뭉치 데이터셋를 입력과 정답의 말뭉치로 변환하여 딥러닝 기반 중심어 탐지 모델로 학습하여 결과를 도출하는 것을 특징으로 하는 한국어-한국 수어 번역 데이터 증강 및 평가 장치. |
| 12 | 제9항에 있어서,상기 데이터 증강부는, 상기 중심어 탐지부 또는 딥러닝 기반 중심어 탐지 모델 결과를 통해서 중심어가 매핑된 새로운 데이터셋을 얻고, 상기 완전 동일한 토큰일 경우에는 정답이 1로 매핑된 토큰을 기준으로 문장을 쪼개서 데이터 증강을 하는 것을 특징으로 하는 한국어-한국 수어 번역 데이터 증강 및 평가 장치. |
| 13 | 제12항에 있어서, 상기 한국어-한국 수어 번역 모델부는, 상기 데이터 증강부를 통해서 증강된 쪼개진 한국어 문장 토큰-한국 수어 문장 토큰의 말뭉치를 기반으로, 학습시에는 쪼개진 한국어 문장 토큰-한국 수어 문장 토큰 말뭉치를 입력 데이터로 딥러닝 기반 기계 번역 모델을 통해 학습하여 번역 모델의 성능을 높이는 것을 특징으로 하는 한국어-한국 수어 번역 데이터 증강 및 평가 장치. |
| 14 | 제12항에 있어서, 상기 한국어-한국 수어 번역 모델부는, 상기 데이터 증강부를 통해서 증강된 쪼개진 한국어 문장 토큰-한국 수어 문장 토큰의 말뭉치를 기반으로, 테스트시에는 쪼개진 한국어 문장 토큰-한국 수어 문장 토큰 말뭉치를 쪼개진 갯수만큼 사전 학습된 딥러닝 기반 기계 번역 모델을 매칭하여 번역을 하는 것을 특징으로 하는 한국어-한국 수어 번역 데이터 증강 및 평가 장치. |