| 번호 | 청구항 |
|---|---|
| 4 | 삭제 |
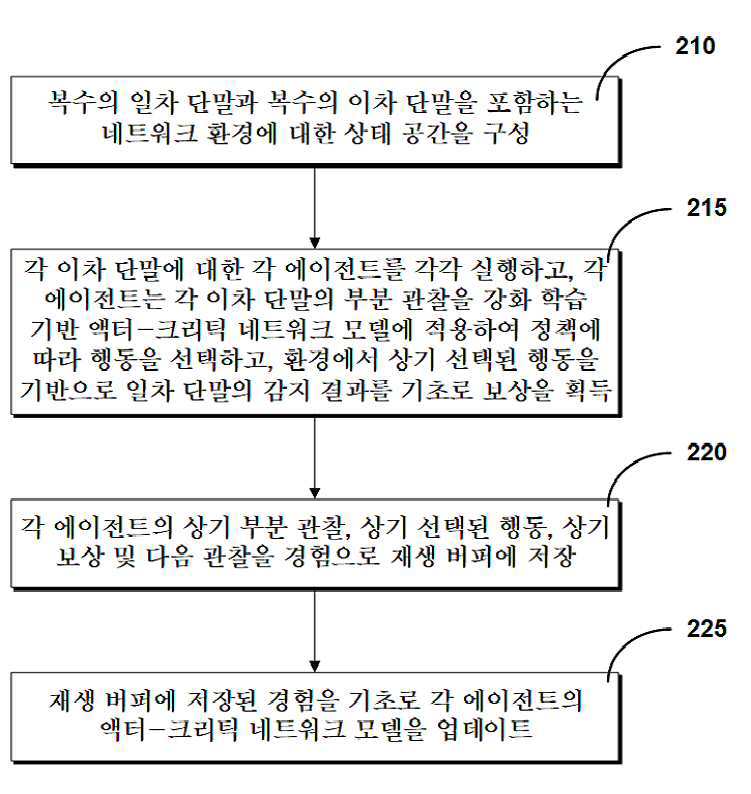
| 1 | (a) 복수의 일차 단말과 복수의 이차 단말을 포함하는 네트워크 환경에 대한 상태 공간을 구성하는 단계-상기 상태 공간은 상기 일차 단말의 점유 여부에 대한 각 상태를 포함함;(b) 에이전트는 각 이차 단말의 부분 관찰을 강화 학습 기반 액터-크리틱 네트워크 모델에 적용하여 정책에 따라 행동을 선택하고, 환경에서 상기 선택된 행동을 기반으로 일차 단말의 감지 결과를 기초로 보상을 계산하는 단계-상기 행동은 감지 임계값임;(c) 상기 부분 관찰, 상기 선택된 행동, 상기 보상 및 다음 관찰을 경험으로 재생 버퍼에 저장하는 단계; 및(d) 상기 재생 버퍼에 저장된 경험을 기초로 상기 액터-크리틱 네트워크 모델을 업데이트하는 단계를 포함하되,상기 정책은 하기 수학식으로 공식화되는 것을 특징으로 하는 분산 인지 무선 네트워크에서 다중 에이전트 강화 학습 기반 최적의 에너지 감지 임계값 제어 방법.여기서, 는 i번째 이차 단말이 선택한 시간 단계 t에서의 특정 채널과 섹터에 대한 검출 임계값을 나타내고, 는 일차 단말이 소유한 직교 채널을 나타내고, 는 i번째 이차 단말의 섹터를 나타내고, K는 직교 채널 개수를 나타내고, L은 섹터 개수를 나타내며, 는 시간 단계 t까지의 일차 단말의 누적 검출 확률을 나타내며, 는 시간 단계 t까지의 누적 오경보 확률을 나타내고, 는 이차 단말의 인덱스를 나타냄. |
| 2 | 제1 항에 있어서, 훈련 단계에서 상기 재생 버퍼는 다른 에이전트의 경험도 저장되되, 상기 (d) 단계에서, 각 에이전트는 다른 에이전트의 경험을 공유받아 각 에이전트의 액터-크리틱 네트워크 모델을 중앙집중식으로 학습시키고, 실행 단계에서 상기 (d) 단계는, 각 에이전트는 각 에이전트의 로컬 경험만 이용하여 각 에이전트의 액터-크리틱 네트워크 모델을 업데이트시키는 것을 특징으로 하는 분산 인지 무선 네트워크에서 다중 에이전트 강화 학습 기반 최적의 에너지 감지 임계값 제어 방법. |
| 3 | 제1 항에 있어서, 상기 정책은 상기 일차 단말을 올바르게 검출할 확률은 최대화하고 시간 단계 t까지의 누적 오경보 확률이 최소인 감지 임계값을 결정하는 것인 것을 특징으로 하는 분산 인지 무선 네트워크에서 다중 에이전트 강화 학습 기반 최적의 에너지 감지 임계값 제어 방법. |
| 5 | 제1 항에 있어서, 상기 보상은 상기 환경에서 상기 선택된 행동을 기반으로 일차 단말을 감지 결과와 실제 상태가 동일한 경우 제로(0)를 부과하고, 상기 환경에서 상기 선택된 행동을 기반으로 일차 단말을 감지 결과와 실제 상태가 다른 경우 패널티를 부과하되,상기 실제 상태는 일차 단말의 채널 점유 및 미점유 중 어느 하나인 것을 특징으로 하는 분산 인지 무선 네트워크에서 다중 에이전트 강화 학습 기반 최적의 에너지 감지 임계값 제어 방법. |
| 6 | 제1 항 내지 제3항, 제5 항 중 어느 하나의 항에 따른 방법을 수행하기 위한 프로그램 코드를 기록한 컴퓨터로 판독 가능한 기록 매체. |
| 7 | 적어도 하나의 명령어를 저장하는 메모리; 및상기 메모리에 저장된 명령어를 실행하는 프로세서를 포함하되,상기 프로세서에 의해 실행된 명령어는 각각, (a) 복수의 일차 단말과 복수의 이차 단말을 포함하는 네트워크 환경에 대한 상태 공간을 구성하는 단계-상기 상태 공간은 상기 일차 단말의 점유 여부에 대한 각 상태를 포함함;(b) 각 이차 단말에 대한 각 에이전트를 각각 실행하고, 각 에이전트는 각 이차 단말의 부분 관찰을 강화 학습 기반 액터-크리틱 네트워크 모델에 적용하여 정책에 따라 행동을 선택하고, 환경에서 상기 선택된 행동을 기반으로 일차 단말의 감지 결과를 기초로 보상을 계산하는 단계-상기 행동은 감지 임계값임;(c) 상기 각 에이전트의 상기 부분 관찰, 상기 선택된 행동, 상기 보상 및 다음 관찰을 경험으로 재생 버퍼에 저장하는 단계; 및(d) 상기 재생 버퍼에 저장된 경험을 기초로 각 에이전트의 상기 액터-크리틱 네트워크 모델을 업데이트하는 단계를 수행하되,상기 정책은 하기 수학식으로 공식화되는 것을 특징으로 하는 컴퓨팅 장치.여기서, 는 i번째 이차 단말이 선택한 시간 단계 t에서의 특정 채널과 섹터에 대한 검출 임계값을 나타내고, 는 일차 단말이 소유한 직교 채널을 나타내고, 는 i번째 이차 단말의 섹터를 나타내고, K는 직교 채널 개수를 나타내고, L은 섹터 개수를 나타내며, 는 시간 단계 t까지의 일차 단말의 누적 검출 확률을 나타내며, 는 시간 단계 t까지의 누적 오경보 확률을 나타내고, 는 이차 단말의 인덱스를 나타냄. |
| 8 | 제7 항에 있어서, 훈련 단계에서 상기 재생 버퍼는 다른 에이전트의 경험도 저장되되, 상기 (d) 단계에서, 각 에이전트는 다른 에이전트의 경험을 공유받아 각 에이전트의 액터-크리틱 네트워크 모델을 중앙집중식으로 학습시키고, 실행 단계에서 상기 (d) 단계는, 각 에이전트는 각 에이전트의 로컬 경험만 이용하여 각 에이전트의 액터-크리틱 네트워크 모델을 업데이트시키는 것을 특징으로 하는 컴퓨팅 장치. |
| 9 | 제7 항에 있어서, 상기 정책은 상기 일차 단말을 올바르게 검출할 확률은 최대화하고 시간 단계 t까지의 누적 오경보 확률이 최소인 감지 임계값을 결정하는 것인 것을 특징으로 하는 컴퓨팅 장치. |
| 10 | 삭제 |
| 11 | 제7 항에 있어서, 상기 보상은 상기 환경에서 상기 선택된 행동을 기반으로 일차 단말을 감지 결과와 실제 상태가 동일한 경우 제로(0)를 부과하고, 상기 환경에서 상기 선택된 행동을 기반으로 일차 단말을 감지 결과와 실제 상태가 다른 경우 패널티를 부과하되,상기 실제 상태는 일차 단말의 채널 점유 및 미점유 중 어느 하나인 것을 특징으로 하는 컴퓨팅 장치. |
| 12 | 복수의 일차 단말; 및복수의 이차 단말을 포함하되,상기 복수의 이차 단말은 각각, 복수의 일차 단말과 복수의 이차 단말을 포함하는 네트워크 환경에 대한 상태 공간을 구성하는 단계-상기 상태 공간은 상기 일차 단말의 점유 여부에 대한 각 상태를 포함함;에이전트는 각 이차 단말의 부분 관찰을 강화 학습 기반 액터-크리틱 네트워크 모델에 적용하여 정책에 따라 행동을 선택하고, 환경에서 상기 선택된 행동을 기반으로 일차 단말의 감지 결과를 기초로 보상을 계산하는 단계-상기 행동은 감지 임계값임;상기 부분 관찰, 상기 선택된 행동, 상기 보상 및 다음 관찰을 경험으로 재생 버퍼에 저장하는 단계; 및상기 재생 버퍼에 저장된 경험을 기초로 상기 액터-크리틱 네트워크 모델을 업데이트하는 단계를 포함하되,상기 정책은 하기 수학식으로 공식화되는 것을 특징으로 하는 시스템.여기서, 는 i번째 이차 단말이 선택한 시간 단계 t에서의 특정 채널과 섹터에 대한 검출 임계값을 나타내고, 는 일차 단말이 소유한 직교 채널을 나타내고, 는 i번째 이차 단말의 섹터를 나타내고, K는 직교 채널 개수를 나타내고, L은 섹터 개수를 나타내며, 는 시간 단계 t까지의 일차 단말의 누적 검출 확률을 나타내며, 는 시간 단계 t까지의 누적 오경보 확률을 나타내고, 는 이차 단말의 인덱스를 나타냄. |