| 번호 | 청구항 |
|---|---|
| 9 | 제6항에 있어서,상기 설정된 프롬프트의 길이는 상기 태스크 프롬프트의 길이인, 언어 모델의 추론 방법. |
| 10 | 제6항에 있어서,상기 태스크 프롬프트는, 모든 입력 인스턴스에 동일하게 덧붙여지는 임베딩인 태스크만을 학습해 구해진, 언어 모델의 추론 방법. |
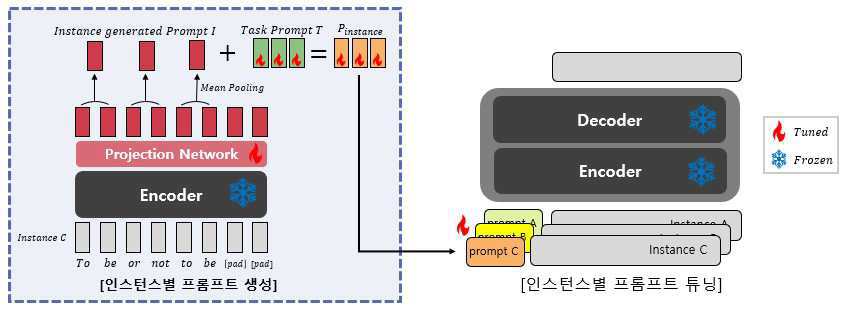
| 1 | 사전 학습된 인코더-디코더 기반 언어모델의 파라미터들을 모두 고정한 채, 상기 인코더를 통해 입력된 인스턴스를 임베딩하여 임베딩 벡터를 구하는 제1 단계;상기 임베딩 벡터를 프롬프트의 벡터 공간에 프로젝션하여 태스크 프롬프트의 벡터 공간과 상기 임베딩 벡터의 벡터 공간을 맞추는 제2 단계;상기 제2 단계에서 프로젝션된 임베딩 벡터를 설정된 프롬프트의 길이에 맞추기 위해 풀링(pooling) 연산하는 제3 단계; 그리고,상기 제3 단계를 통해 만들어진 상기 입력된 인스턴스의 프롬프트에 상기 태스크 프롬프트를 더해 인스턴스별 프롬프트를 생성하는 제4 단계; 를 포함하는, 태스크가 반영된 인스턴스별 프롬프트 튜닝 방법. |
| 2 | 제1항에 있어서,상기 프로젝션은 병목 구조를 갖는 프로젝션 레이어를 통해 이뤄지는, 태스크가 반영된 인스턴스별 프롬프트 튜닝 방법. |
| 3 | 제1항에 있어서,상기 프로젝션 레이어는를 만족하고, WO 와 Wu는 프로젝션 레이어의 가중치 행렬이고, ReLU는 활성화 함수인, 태스크가 반영된 인스턴스별 프롬프트 튜닝 방법. |
| 4 | 제1항에 있어서,상기 설정된 프롬프트의 길이는 상기 태스크 프롬프트의 길이인, 태스크가 반영된 인스턴스별 프롬프트 튜닝 방법. |
| 5 | 제1항에 있어서,상기 태스크 프롬프트는, 모든 입력 인스턴스에 동일하게 덧붙여지는 임베딩인 태스크만을 학습해 구해진, 태스크가 반영된 인스턴스별 프롬프트 튜닝 방법. |
| 6 | 사전 학습된 인코더-디코더 기반 언어 모델이 인스턴스별로 프롬프트를 튜닝하도록 학습하는 (A) 단계; 그리고,상기 (A) 단계를 통해 학습된 언어 모델이 입력된 인스턴스에 대해 사전 학습된 바에 따라 입력된 인스턴스의 프롬프트를 예측해 결과를 추론하는 (B) 단계;를 포함하고,상기 (A) 단계는, 사전 학습된 인코더-디코더 기반 언어모델의 파라미터들을 모두 고정한 채, 상기 인코더를 통해 입력된 인스턴스를 임베딩하여 임베딩 벡터를 구하는 제1 단계;상기 임베딩 벡터를 프롬프트의 벡터 공간에 프로젝션하여 태스크 프롬프트의 벡터 공간과 상기 임베딩 벡터의 벡터 공간을 맞추는 제2 단계;상기 제2 단계에서 프로젝션된 임베딩 벡터를 설정된 프롬프트의 길이에 맞추기 위해 풀링(pooling) 연산하는 제3 단계; 그리고,상기 제3 단계를 통해 만들어진 상기 입력된 인스턴스의 프롬프트에 상기 태스크 프롬프트를 더해 인스턴스별 프롬프트를 생성하는 제4 단계; 를 포함하는, 언어 모델의 추론 방법. |
| 7 | 제6항에 있어서,상기 프로젝션은 병목 구조를 갖는 프로젝션 레이어를 통해 이뤄지는, 언어 모델의 추론 방법. |
| 8 | 제6항에 있어서,상기 프로젝션 레이어는 를 만족하고, WO 와 Wu는 프로젝션 레이어의 가중치 행렬이고, ReLU는 활성화 함수인, 언어 모델의 추론 방법. |
| 11 | 제1 항 내지 제5항 중 어느 한 항에 기재된 태스크가 반영된 인스턴스별 프롬프트 튜닝 방법을 컴퓨터가 읽을 수 있도록 코딩된 프로그램을 기록한 기록 매체. |
| 12 | 태스크가 반영된 인스턴스별 프롬프트 튜닝 방법을 컴퓨터가 읽을 수 있도록 코딩된 프로그램을 저장하는 메모리; 및상기 프로그램을 실행하는 프로세서;를 포함하고,상기 태스크가 반영된 인스턴스별 프롬프트 튜닝 방법은,사전 학습된 인코더-디코더 기반 언어모델의 파라미터들을 모두 고정한 채, 상기 인코더를 통해 입력된 인스턴스를 임베딩하여 임베딩 벡터를 구하는 제1 단계;상기 임베딩 벡터를 프롬프트의 벡터 공간에 프로젝션하여 태스크 프롬프트의 벡터 공간과 상기 임베딩 벡터의 벡터 공간을 맞추는 제2 단계;상기 제2 단계에서 프로젝션된 임베딩 벡터를 설정된 프롬프트의 길이에 맞추기 위해 풀링(pooling) 연산하는 제3 단계; 그리고,상기 제3 단계를 통해 만들어진 상기 입력된 인스턴스의 프롬프트에 상기 태스크 프롬프트를 더해 인스턴스별 프롬프트를 생성하는 제4 단계; 를 포함하는 연산 장치. |
| 13 | 제12항에 있어서,상기 프로젝션은 병목 구조를 갖는 프로젝션 레이어를 통해 이뤄지는, 연산 장치. |
| 14 | 제12항에 있어서,상기 프로젝션 레이어는 를 만족하고, WO 와 Wu는 프로젝션 레이어의 가중치 행렬이고, ReLU는 활성화 함수인, 연산 장치. |
| 15 | 제12항에 있어서,상기 설정된 프롬프트의 길이는 상기 태스크 프롬프트의 길이인, 연산 장치. |
| 16 | 제12항에 있어서,상기 태스크 프롬프트는, 모든 입력 인스턴스에 동일하게 덧붙여지는 임베딩인 태스크만을 학습해 구해진, 연산 장치. |