| 번호 | 청구항 |
|---|---|
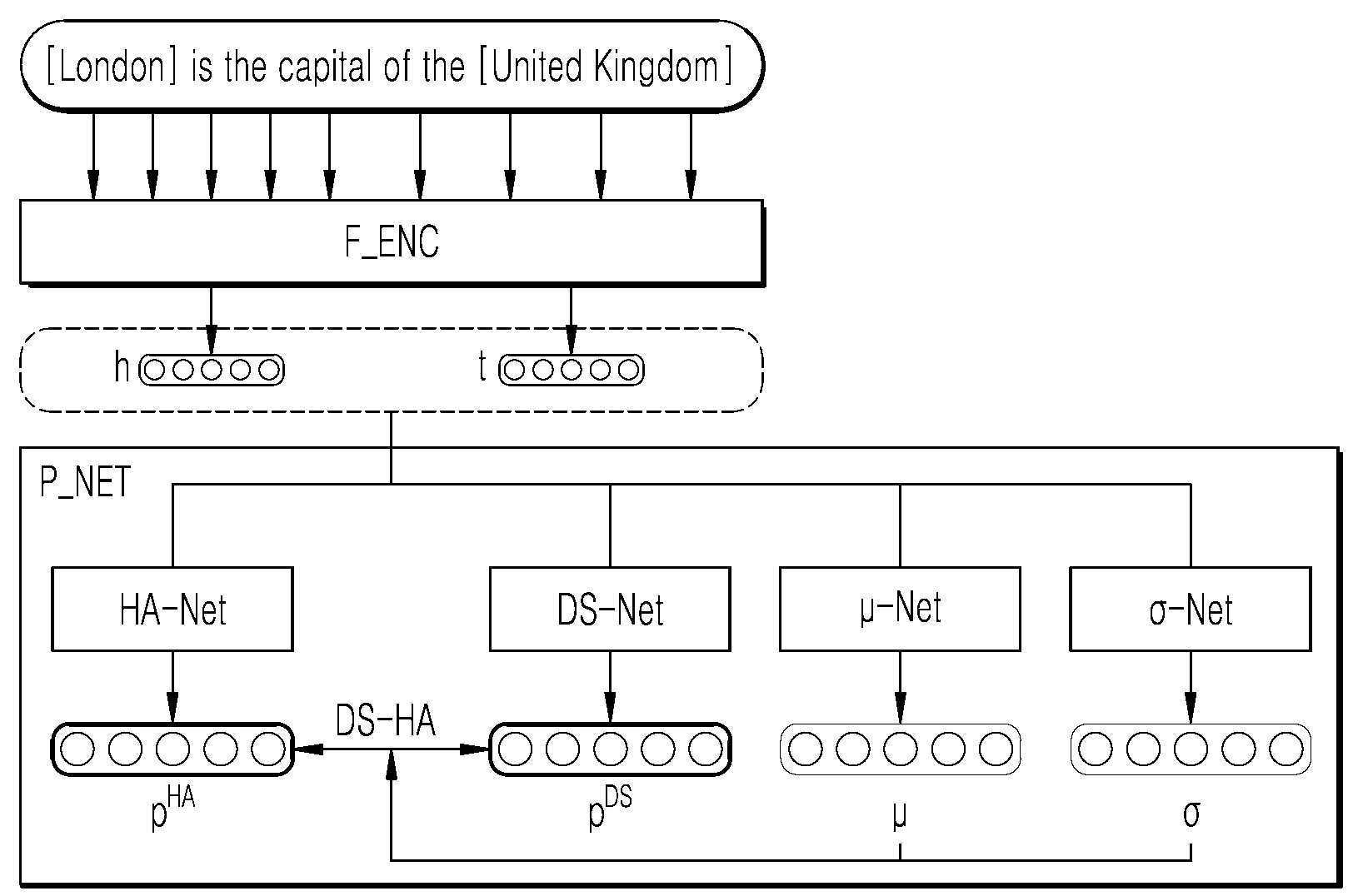
| 1 | 텍스트 기반 관계 추출(Relation Extraction; RE) 방법으로서,텍스트 기반 관계 추출 장치가 사전정의된 관계 정보에 대한 제 1 레이블 세트에 기반하여, 제 1 관계 예측 네트워크에 의해, 입력 텍스트의 엔티티 쌍(entity pair)에 내재된 제 1 관계 정보를 예측하는 단계;상기 텍스트 기반 관계 추출 장치가 상기 사전정의된 관계 정보에 대한 레이블링 바이어스(labeling bias)를 포함한 제 2 레이블 세트에 기반하여, 제 2 관계 예측 네트워크에 의해, 상기 입력 텍스트의 엔티티 쌍에 내재된 제 2 관계 정보를 예측하는 단계;상기 텍스트 기반 관계 추출 장치가 관계 정보의 차이 확률 분포(disagreement probability distribution)에 대한 적어도 하나의 차이 추정 네트워크에 의해, 상기 제 1 관계 정보 및 상기 제2 관계 정보 간의 차이 정보를 추정하는 단계; 및상기 텍스트 기반 관계 추출 장치가 상기 차이 정보에 기반한 손실 함수를 이용하여 상기 제 1 관계 예측 네트워크, 상기 제 2 관계 예측 네트워크 및 상기 적어도 하나의 차이 추정 네트워크를 훈련하는 단계를 포함하는,텍스트 기반 관계 추출 방법. |
| 2 | 제 1 항에 있어서,상기 입력 텍스트의 엔티티 쌍은 헤드 엔티티(head entity) 및 테일 엔티티(tail entity)의 조합에 대응하고,상기 텍스트 기반 관계 추출 장치가, 피처 인코더(feature encoder)를 실행하여, 상기 입력 텍스트의 일련의 단어 중에서 상기 헤드 엔티티에 대응하는 단어 및 상기 테일 엔티티에 대응하는 단어를 결정하는 단계를 더 포함하는,텍스트 기반 관계 추출 방법. |
| 3 | 제 2 항에 있어서,상기 헤드 엔티티 및 상기 테일 엔티티는 각각에 대응하는 단어의 특성 벡터(feature vector)로 표현되는,텍스트 기반 관계 추출 방법. |
| 4 | 제 1 항에 있어서,상기 제 1 레이블 세트는 사람이 붙인 레이블(Human Annotated Label)을 포함하고,상기 제 2 레이블 세트는 원격 지도 레이블(Distantly Supervised Label)을 포함하는,텍스트 기반 관계 추출 방법. |
| 5 | 제 1 항에 있어서,상기 제 1 관계 예측 네트워크 및 상기 제 2 관계 예측 네트워크는 서로 초기 가중치를 공유하도록 구성되는,텍스트 기반 관계 추출 방법. |
| 6 | 제 1 항에 있어서,상기 손실 함수는 상기 차이 정보에 대한 손실 항을 포함하고,상기 차이 정보에 대한 손실 항은 상기 제 1 관계 정보 및 상기 제 2 관계 정보의 비율 및 상기 차이 정보에 기반한 함수인,텍스트 기반 관계 추출 방법. |
| 7 | 제 1 항에 있어서,상기 훈련하는 단계는,상기 텍스트 기반 관계 추출 장치가, 상기 입력 텍스트의 엔티티 쌍에 내재된 관계 정보에 대한 레이블의 유형에 기반하여, 상기 손실 함수를 결정하는 단계를 포함하는,텍스트 기반 관계 추출 방법. |
| 8 | 제 1 항에 있어서,상기 차이 확률 분포는 상기 제 1 관계 정보 및 상기 제 2 관계 정보의 비율에 대한 로그 정규 분포(lognormal distribution)이고,상기 적어도 하나의 차이 추정 네트워크는, 상기 로그 정규 분포의 평균에 대한 제 1 차이 추정 네트워크 및 상기 로그 정규 분포의 표준편차에 대한 제 2 차이 추정 네트워크를 포함하는,텍스트 기반 관계 추출 방법. |
| 9 | 제 1 항에 있어서,상기 텍스트 기반 관계 추출 장치가, 상기 훈련하는 단계에 의해 훈련된 상기 제 1 관계 예측 네트워크에 의해 제 2 입력 텍스트의 엔티티 쌍에 내재된 관계 정보를 추정하는 단계를 더 포함하는,텍스트 기반 관계 추출 방법. |
| 10 | 텍스트 기반 관계 추출 장치로서,프로세서; 및상기 프로세서와 동작 가능하게 연결되고, 상기 프로세서에서 수행되는 적어도 하나의 코드를 저장하는 메모리를 포함하고,상기 메모리는 상기 프로세서를 통해 실행될 때, 상기 프로세서로 하여금,사전정의된 관계 정보에 대한 제 1 레이블 세트에 기반하여, 제 1 관계 예측 네트워크에 의해, 입력 텍스트의 엔티티 쌍에 내재된 제 1 관계 정보를 예측하고,상기 사전정의된 관계 정보에 대한 레이블링 바이어스를 포함한 제 2 레이블 세트에 기반하여, 제 2 관계 예측 네트워크에 의해, 상기 입력 텍스트의 엔티티 쌍에 내재된 제 2 관계 정보를 예측하고,관계 정보의 차이 확률 분포에 대한 적어도 하나의 차이 추정 네트워크에 의해, 상기 제 1 관계 정보 및 상기 제2 관계 정보 간의 차이 정보를 추정하고,상기 차이 정보에 기반한 손실 함수를 이용하여 상기 제 1 관계 예측 네트워크, 상기 제 2 관계 예측 네트워크 및 상기 적어도 하나의 차이 추정 네트워크를 훈련하도록 구성된 코드를 저장하는,텍스트 기반 관계 추출 장치. |
| 11 | 제 10 항에 있어서,상기 입력 텍스트의 엔티티 쌍은 헤드 엔티티 및 테일 엔티티의 조합에 대응하고,상기 메모리는 상기 프로세서를 통해 실행될 때, 상기 프로세서로 하여금,피처 인코더를 실행하여, 상기 입력 텍스트의 일련의 단어 중에서 상기 헤드 엔티티에 대응하는 단어 및 상기 테일 엔티티에 대응하는 단어를 결정하도록 구성된 코드를 저장하는,텍스트 기반 관계 추출 장치. |
| 12 | 제 10 항에 있어서,상기 제 1 레이블 세트는 사람이 붙인 레이블을 포함하고,상기 제 2 레이블 세트는 원격 지도 레이블을 포함하는,텍스트 기반 관계 추출 장치. |
| 13 | 제 10 항에 있어서,상기 손실 함수는 상기 차이 정보에 대한 손실 항을 포함하고,상기 차이 정보에 대한 손실 항은 상기 제 1 관계 정보 및 상기 제 2 관계 정보의 비율 및 상기 차이 정보에 기반한 함수인,텍스트 기반 관계 추출 장치. |
| 14 | 제 10 항에 있어서,상기 메모리는 상기 프로세서를 통해 실행될 때, 상기 프로세서로 하여금,상기 입력 텍스트의 엔티티 쌍에 내재된 관계 정보에 대한 레이블의 유형에 기반하여, 상기 손실 함수를 결정하도록 구성된 코드를 저장하는,텍스트 기반 관계 추출 장치. |
| 15 | 제 10 항에 있어서,상기 차이 확률 분포는 상기 제 1 관계 정보 및 상기 제 2 관계 정보의 비율에 대한 로그 정규 분포이고,상기 적어도 하나의 차이 차이 추정 네트워크는, 상기 로그 정규 분포의 평균에 대한 제 1 차이 추정 네트워크 및 상기 로그 정규 분포의 표준편차에 대한 제 2 차이 추정 네트워크를 포함하는,텍스트 기반 관계 추출 장치. |
| 16 | 제 11 항에 있어서,상기 메모리는 상기 프로세서를 통해 실행될 때, 상기 프로세서로 하여금,훈련된 상기 제 1 관계 예측 네트워크에 의해 제 2 입력 텍스트의 엔티티 쌍에 내재된 관계 정보를 추정하도록 구성된 코드를 저장하는,텍스트 기반 관계 추출 장치. |
| 17 | 제 1 항 내지 제 9 항 중 어느 한 항에 따른 텍스트 기반 관계 추출 방법을 컴퓨터에 의해 실행하도록 구성된 적어도 하나의 명령어를 포함한 컴퓨터 프로그램을 저장한 컴퓨터 판독가능한 비일시적 기록 매체. |