| 번호 | 청구항 |
|---|---|
| 5 | 청구항 4에 있어서,수식 5에 기초하여 전체손실()을 계산하는 연산부를 더 포함하며,상기 연산부는,수식 6 및 경사하강법(gradient descent)에 기초하여 상기 웨이트를 수정하고,상기 피쳐익스트랙터부와 상기 도메인디스크리펜시부와 상기 시멘틱클러스터링부는,수정된 상기 웨이트를 기초로 재학습되는 것을 특징으로 하며,상기 연산부는,기설정된 횟수로 상기 웨이트가 수정됨에도 불구하고 상기 전체손실의 변화가 기설정된 비율보다 작은 경우 상기 피쳐익스트랙터부와 상기 도메인디스크리펜시부와 상기 시멘틱클러스터링부의 학습을 중단시켜 최종 진단 알고리즘을 도출하는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 장치.{수식 5}(상기 은 전체손실, 상기 는 상기 분류손실, 상기 는 상기 도메인적응손실, 상기 는 상기 의미군집화손실, 상기 와 는 사용자가 기설정한 계수들){수식 6}(상기 은 수정된 상기 웨이트, 상기 는 수정전 상기 웨이트, 상기 는 사용자가 기설정한 상수, 상기 는 상기 웨이트에 대한 상기 전체손실의 미분값) |
| 6 | 청구항 5에 있어서,상기 웨이트에 대한 상기 전체손실의 미분값은,역전파 알고리즘(back-propagation algorithm) 및 연쇄법칙(chain rule)에 따라 계산되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 장치. |
| 7 | 청구항 4에 있어서,상기 라벨클래시파이어부는,수식 7 및 경사하강법(gradient descent)에 기초하여 상기 웨이트를 수정하고, 수정된 상기 웨이트를 기초로 재학습되는 것을 특징으로 하며,상기 라벨클래시파이어부는,기설정된 횟수로 상기 웨이트가 수정됨에도 불구하고 상기 분류손실의 변화가 기설정된 비율보다 작은 경우 학습이 중단되어 최종 머신러닝 기반의 상태분류 모델이 도출되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 장치.{수식 7}(상기 은 수정된 상기 웨이트, 상기 는 수정전 상기 웨이트, 상기 는 사용자가 기설정한 상수, 상기 는 상기 웨이트에 대한 상기 분류손실의 미분값) |
| 8 | 청구항 7에 있어서,상기 웨이트에 대한 상기 분류손실의 미분값은,역전파 알고리즘(back-propagation algorithm) 및 연쇄법칙(chain rule)에 따라 계산되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 장치. |
| 9 | 청구항 6에 있어서,상기 최종 진단 알고리즘을 이용하여 진단된 상기 제2시스템의 상태를 출력하는 출력부를 포함하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 장치. |
| 10 | 청구항 6에 있어서,상기 피쳐익스트랙터부는,convolution neural network(CNN)를 사용하며,상기 라벨클래시파이어부는,fully connected layer로 마련되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 장치. |
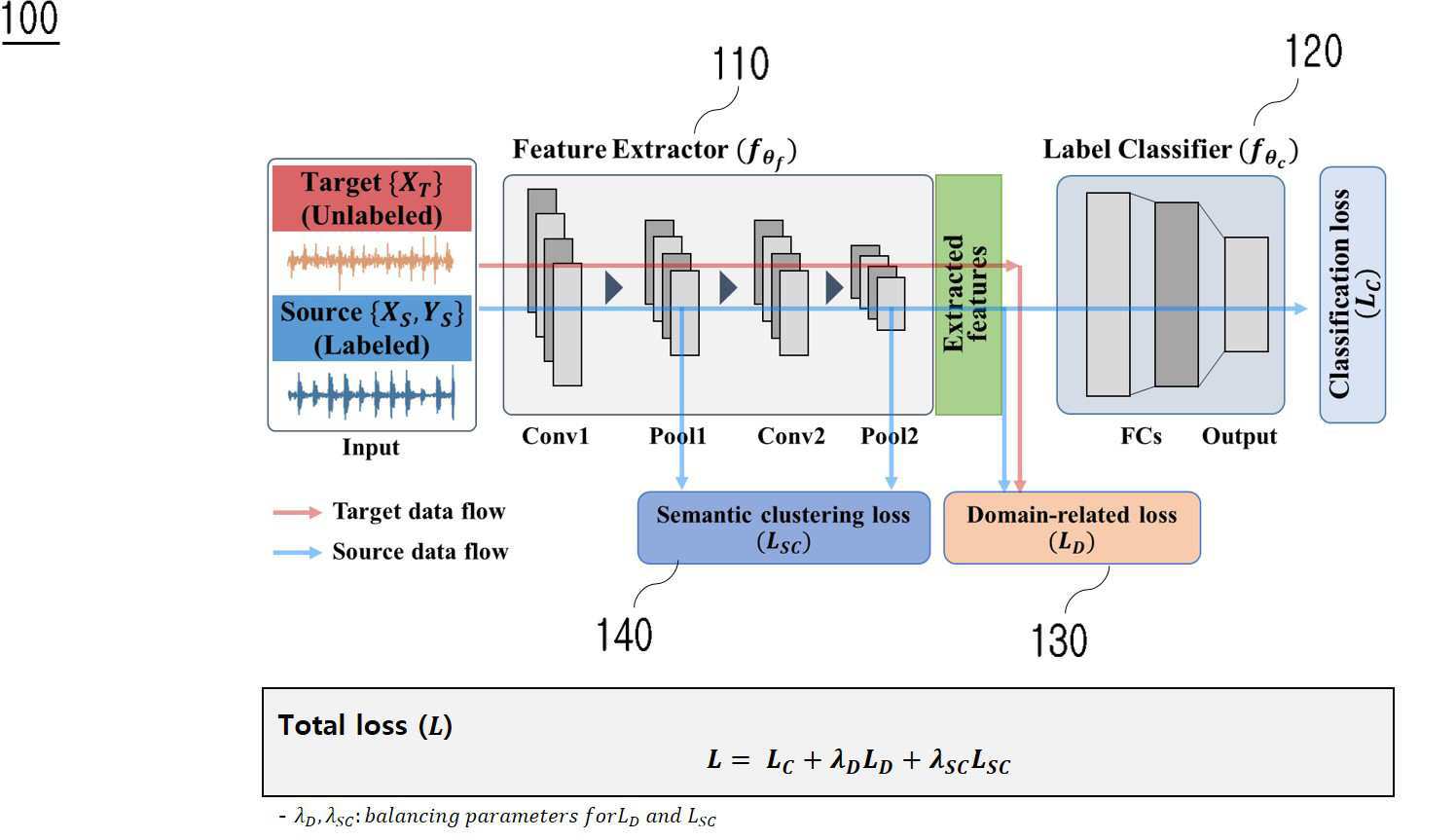
| 11 | 레이블 정보가 부재된 기계 시스템의 상태 진단 시스템에 의해 수행되는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 방법에 있어서,제1시스템에서 측정되어 레이블링된 시계열 신호 데이터를 포함하는 제1데이터셋(dataset)과 제2시스템에서 측정되어 레이블링되지 않은 시계열 신호 데이터를 포함하는 제2데이터셋으로부터 피쳐익스트랙터부가 제1피쳐(feature)와 제2피쳐를 계산하는 머신러닝 기반의 피쳐계산 모델을 학습하는 피쳐익스트랙터단계;상기 제1데이터셋을 이용하여 라벨클래시파이어부가 상기 제1시스템의 상태를 분류하는 머신러닝 기반의 상태분류 모델을 학습하고, 분류손실(classifier loss, LC)을 계산하는 라벨클래시파이어단계;상기 제1데이터셋을 소스 도메인(source domain)으로 설정하고 상기 제2데이터셋을 타겟 도메인(target domain)으로 설정하여 도메인디스크리펜시부가 도메인 어댑테이션(domain adaptation)을 수행하는 머신러닝 기반의 도메인 어댑테이션 모델을 학습하고, 도메인적응손실(domain-related loss, LD)을 계산하는 도메인디스크리펜시단계; 및시멘틱클러스터링부가 상기 제1데이터셋의 레이블에 기초하여 상태별로 클러스터링하는 머신러닝 기반의 클러스터링 모델을 학습하고, 의미군집화손실(semantic clustering loss, LSC)을 계산하는 시멘틱클러스터링단계를 포함하고,상기 분류손실은,수식 1에 기초하여 계산되며,상기 도메인적응손실은,수식 2에 기초하여 계산되며,상기 의미군집화손실은,수식 3에 기초하여 계산되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 방법.{수식 1}(상기 는 상기 분류손실, 상기 C는 상기 제1시스템의 상태의 수, 상기 Y는 라벨 벡터, 상기 는 상기 Y의 k번째 노드의 값, 상기 p는 상기 Y의 k번째 노드에 해당하는 확률벡터){수식 2}(상기 H는 universal RKHS(reproducing kernel Hilbert space), 상기 nS와 상기 nT는 각각 상기 제1데이터셋과 상기 제2데이터셋의 수, 상기 와 상기 는 각각 상기 제1피쳐와 상기 제2피쳐){수식 3}(상기 는 상기 의미군집화손실, 상기 는 상기 시멘틱클러스터링단계의 특성층의 수, 상기 는 k번째 밸런싱 파라미터(balancing parameter), 상기 는 상기 제1데이터셋의 수, 상기 는 k번째 피쳐 레벨에서 번째 상기 제1데이터셋의 피쳐 벡터, 상기 는 번째 데이터셋과 번째 데이터셋이 같은 클래스에 속하면 1이고 다른 클래스라면 0인 행렬 의 값, 상기 d는 서로 다른 상태의 두 데이터셋 사이의 최소 거리를 제어하는 값) |
| 12 | 삭제 |
| 13 | 청구항 11에 있어서,상기 피쳐익스트랙터단계와 상기 도메인디스크리펜시단계와 상기 시멘틱클러스터링단계는,상기 제1데이터셋과 상기 제2데이터셋의 소집단(mini-batch) 단위로 학습되며, 상기 제1데이터셋과 상기 제2데이터셋의 모든 소집단에 대해 학습이 이루어지는 경우 상기 제1데이터셋과 상기 제2데이터셋에서 각각 랜덤하게 소집단이 재추출되어 재학습되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 방법. |
| 14 | 청구항 13에 있어서,상기 피쳐익스트랙터단계는,수식 4에 기초하여 상기 제1피쳐와 상기 제2피쳐를 계산하는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 방법.{수식 4}(상기 는 상기 제1데이터셋 또는 상기 제2데이터셋, 상기 는 상기 으로부터 계산된 상기 제1피쳐 또는 상기 제2피쳐, 상기 는 활성화함수(activation function), 상기 는 웨이트(weight), 상기 bias는 상수) |
| 15 | 청구항 14에 있어서,수식 5에 기초하여 연산부에 의해 전체손실()을 계산하는 연산단계를 더 포함하며,상기 연산단계는,수식 6 및 경사하강법(gradient descent)에 기초하여 상기 웨이트를 수정하고,상기 피쳐익스트랙터단계와 상기 도메인디스크리펜시단계와 상기 시멘틱클러스터링단계는,수정된 상기 웨이트를 기초로 재학습되는 것을 특징으로 하며,상기 연산단계는,기설정된 횟수로 상기 웨이트가 수정됨에도 불구하고 상기 전체손실의 변화가 기설정된 비율보다 작은 경우 상기 피쳐익스트랙터단계와 상기 도메인디스크리펜시단계와 상기 시멘틱클러스터링단계의 학습을 중단시켜 최종 진단 알고리즘을 도출하는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 방법.{수식 5}(상기 은 전체손실, 상기 는 상기 분류손실, 상기 는 상기 도메인적응손실, 상기 는 상기 의미군집화손실, 상기 와 는 사용자가 기설정한 계수들){수식 6}(상기 은 수정된 상기 웨이트, 상기 는 수정전 상기 웨이트, 상기 는 사용자가 기설정한 상수, 상기 는 상기 웨이트에 대한 상기 전체손실의 미분값) |
| 16 | 청구항 15에 있어서,상기 웨이트에 대한 상기 전체손실의 미분값은,역전파 알고리즘(back-propagation algorithm) 및 연쇄법칙(chain rule)에 따라 계산되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 방법. |
| 17 | 청구항 14에 있어서,상기 라벨클래시파이어단계는,수식 7 및 경사하강법(gradient descent)에 기초하여 상기 웨이트를 수정하고, 수정된 상기 웨이트를 기초로 재학습되는 것을 특징으로 하며,상기 라벨클래시파이어단계는,기설정된 횟수로 상기 웨이트가 수정됨에도 불구하고 상기 분류손실의 변화가 기설정된 비율보다 작은 경우 학습이 중단되어 최종 머신러닝 기반의 상태분류 모델이 도출되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 방법.{수식 7}(상기 은 수정된 상기 웨이트, 상기 는 수정전 상기 웨이트, 상기 는 사용자가 기설정한 상수, 상기 는 상기 웨이트에 대한 상기 분류손실의 미분값) |
| 18 | 청구항 17에 있어서,상기 웨이트에 대한 상기 분류손실의 미분값은,역전파 알고리즘(back-propagation algorithm) 및 연쇄법칙(chain rule)에 따라 계산되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 방법. |
| 19 | 청구항 16에 있어서,상기 최종 진단 알고리즘을 이용하여 진단된 상기 제2시스템의 상태가 출력부에 의해 출력하는 출력단계를 포함하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 방법. |
| 20 | 청구항 16에 있어서,상기 피쳐익스트랙터단계는,convolution neural network(CNN)을 사용하며,상기 라벨클래시파이어단계는,fully connected layer로 마련되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 방법. |
| 1 | 레이블 정보가 부재된 기계 시스템의 상태 진단 시스템에 의해 수행되는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 장치에 있어서,제1시스템에서 측정되어 레이블링된 시계열 신호 데이터를 포함하는 제1데이터셋(dataset)과 제2시스템에서 측정되어 레이블링되지 않은 시계열 신호 데이터를 포함하는 제2데이터셋으로부터 제1피쳐(feature)와 제2피쳐를 계산하는 머신러닝 기반의 피쳐계산 모델을 학습하는 피쳐익스트랙터부;상기 제1데이터셋을 이용하여 상기 제1시스템의 상태를 분류하는 머신러닝 기반의 상태분류 모델을 학습하고, 분류손실(classifier loss, LC)을 계산하는 라벨클래시파이어부;상기 제1데이터셋을 소스 도메인(source domain)으로 설정하고 상기 제2데이터셋을 타겟 도메인(target domain)으로 설정하여 도메인 어댑테이션(domain adaptation)을 수행하는 머신러닝 기반의 도메인 어댑테이션 모델을 학습하고, 도메인적응손실(domain-related loss, LD)을 계산하는 도메인디스크리펜시부; 및상기 제1데이터셋의 레이블에 기초하여 상태별로 클러스터링하는 머신러닝 기반의 클러스터링 모델을 학습하고, 의미군집화손실(semantic clustering loss, LSC)을 계산하는 시멘틱클러스터링부를 포함하고,상기 분류손실은,수식 1에 기초하여 계산되며,상기 도메인적응손실은,수식 2에 기초하여 계산되며,상기 의미군집화손실은,수식 3에 기초하여 계산되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 장치.{수식 1}(상기 는 상기 분류손실, 상기 C는 상기 제1시스템의 상태의 수, 상기 Y는 라벨 벡터, 상기 는 상기 Y의 k번째 노드의 값, 상기 p는 상기 Y의 k번째 노드에 해당하는 확률벡터){수식 2}(상기 는 상기 도메인적응손실, 상기 H는 universal RKHS(reproducing kernel Hilbert space), 상기 nS와 상기 nT는 각각 상기 제1데이터셋과 상기 제2데이터셋의 수, 상기 와 상기 는 각각 상기 제1피쳐와 상기 제2피쳐){수식 3}(상기 는 상기 의미군집화손실, 상기 는 상기 시멘틱클러스터링부의 특성층의 수, 상기 는 k번째 밸런싱 파라미터(balancing parameter), 상기 는 상기 제1데이터셋의 수, 상기 는 k번째 피쳐 레벨에서 번째 상기 제1데이터셋의 피쳐 벡터, 상기 는 번째 데이터셋과 번째 데이터셋이 같은 클래스에 속하면 1이고 다른 클래스라면 0인 행렬 의 값, 상기 d는 서로 다른 상태의 두 데이터셋 사이의 최소 거리를 제어하는 값) |
| 2 | 삭제 |
| 3 | 청구항 1에 있어서,상기 피쳐익스트랙터부와 상기 도메인디스크리펜시부와 상기 시멘틱클러스터링부는,상기 제1데이터셋과 상기 제2데이터셋의 소집단(mini-batch) 단위로 학습되며, 상기 제1데이터셋과 상기 제2데이터셋의 모든 소집단에 대해 학습이 이루어지는 경우 상기 제1데이터셋과 상기 제2데이터셋에서 각각 랜덤하게 소집단이 재추출되어 재학습되는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 장치. |
| 4 | 청구항 3에 있어서,상기 피쳐익스트랙터부는,수식 4에 기초하여 상기 제1피쳐와 상기 제2피쳐를 계산하는 것을 특징으로 하는 도메인적응 및 의미군집화 알고리즘이 적용된 진단 장치.{수식 4}(상기 는 상기 제1데이터셋 또는 상기 제2데이터셋, 상기 는 상기 으로부터 계산된 상기 제1피쳐 또는 상기 제2피쳐, 상기 는 활성화함수(activation function), 상기 는 웨이트(weight), 상기 bias는 상수) |