| 번호 | 청구항 |
|---|---|
| 1 | 프로세서;를 포함하고,상기 프로세서는,사용자로부터 입력 받은 자연어 질의 문장을 소정의 모델에 입력하여 생성될 구조화된 질의를 구성하는 토큰들을 선택할 예측 확률을 계산하고, 상기 계산된 예측 확률을 기반으로 상기 구조화된 질의를 생성하고,상기 토큰들의 예측 확률들에 기반하여 얻어지는 대표 확률값이 소정의 기준치 이하인 경우 상기 생성된 구조화된 질의에 오류가 있다고 판단하고, 그리고상기 생성된 구조화된 질의에 오류가 있다고 판단한 경우, 상기 구조화된 질의에 오류가 있을 가능성이 표시된 자연어 문장을 생성하는,구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 장치. |
| 2 | 제1항에 있어서, 상기 프로세서가 상기 자연어 질의 문장을 상기 소정의 모델에 입력하기 이전에, 상기 프로세서는 상기 자연어 질의 문장을 구성하는 토큰들에 대한 제1 세트의 임베딩 벡터들을 생성하는,구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 장치. |
| 3 | 제2항에 있어서, 상기 오류가 있다고 판단한 경우, 상기 프로세서는,상기 제1 세트의 임베딩 벡터들, 상기 소정의 모델이 출력하는 예측 확률들에 따라 결정된 상기 생성된 구조화된 질의를 구성하는 토큰들에 대한 제2 세트의 임베딩 벡터들, 그리고 상기 소정의 모델의 내부 파라미터를 입력 받아 상기 자연어 질의 문장을 구성하는 토큰들 중 하나 이상의 어느 토큰에 오류 가능성이 있는지 판단하는, 구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 장치. |
| 4 | 제3항에 있어서, 상기 프로세서는 상기 자연어 문장을 생성할 때, 상기 자연어 질의 문장의 상기 오류 가능성이 있다고 판단된 하나 이상의 토큰에 미리 정해진 표시가 된 상기 자연어 질의 문장을 더 생성하는, 구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 장치. |
| 5 | 제3항에 있어서, 상기 프로세서가 상기 하나 이상의 어느 토큰에 오류 가능성이 있는지 판단할 때, 상기 프로세서는,미리 결정된 임베딩 벡터에서 상기 제1 세트의 임베딩 벡터들 중 임의의 임베딩 벡터로 이동하는 그래디언트 값을 상기 제1 세트의 임베딩 벡터들 중 상기 임의의 임베딩 벡터, 상기 제2 세트의 임베딩 벡터들, 및 상기 내부 파라미터들 간의 조합마다 계산하고, 상기 계산된 모든 조합의 그래디언트 값들을 기반으로 상기 제1 세트의 임베딩 벡터들 중 상기 임의의 임베딩 벡터에 대한 스코어를 생성하고,상기 제1 세트의 임베딩 벡터들 각각에 대한 스코어가 생성되면, 상기 생성된 스코어들 중 가장 큰 스코어와 쌍을 이루는 임베딩 벡터를 결정하고, 그리고 상기 결정된 임베딩 벡터에 대응하는 토큰에 오류 가능성이 있다고 판단하는, 구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 장치. |
| 6 | 제1항에 있어서, 상기 대표 확률값은 상기 토큰들의 예측 확률들 중 가장 큰 확률인, 구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 장치. |
| 7 | 제1항에 있어서, 상기 예측 확률은 상기 생성될 구조화된 질의의 임의의 위치에 미리 결정된 토큰들이 배치될 예측 확률이며, 상기 프로세서는, 상기 구조화된 질의의 모든 위치에 있어서, 상기 모든 위치 중 임의의 위치에 배치될 토큰을 상기 예측 확률들 중 가장 큰 확률을 갖는 토큰으로 결정하고, 그리고상기 모든 위치에서 결정된 단어들을 나열하여 상기 구조화된 질의를 생성하는, 구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 장치. |
| 8 | 사용자로부터 입력 받은 자연어 질의 문장을 소정의 모델에 입력하여 생성될 구조화된 질의를 구성하는 토큰들을 선택할 예측 확률을 계산하는 단계; 상기 계산된 예측 확률을 기반으로 상기 구조화된 질의를 생성하는 단계;상기 토큰들의 예측 확률들 중 가장 큰 확률들에 기반하여 얻어지는 대표 확률값이 소정의 기준치 이하인 경우 상기 생성된 구조화된 질의에 오류가 있다고 판단하는 단계; 및상기 생성된 구조화된 질의에 오류가 있다고 판단한 경우, 상기 구조화된 질의에 오류가 있음을 의미하는 자연어 문장을 생성하는 단계;를 포함하는,구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 방법. |
| 9 | 제8항에 있어서, 상기 오류가 있다고 판단한 경우, 상기 자연어 질의 문장을 구성하는 토큰들에 대한 제1 세트의 임베딩 벡터들, 상기 소정의 모델이 출력하는 예측 확률들에 따라 결정된 상기 생성된 구조화된 질의를 구성하는 토큰들에 대한 제2 세트의 임베딩 벡터들, 그리고 상기 소정의 모델의 내부 파라미터를 입력 받아 상기 자연어 질의 문장을 구성하는 토큰들 중 하나 이상의 어느 토큰에 오류 가능성이 있는지 판단하는 단계를 더 포함하는, 구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 방법. |
| 10 | 제9항에 있어서, 상기 자연어 문장을 생성하는 단계는, 상기 자연어 질의 문장의 상기 오류 가능성이 있다고 판단된 하나 이상의 토큰에 미리 정해진 표시가 된 상기 자연어 질의 문장을 더 생성하는 단계인, 구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 방법. |
| 11 | 제9항에 있어서, 상기 하나 이상의 어느 토큰에 오류 가능성이 있는지 판단하는 단계는,미리 결정된 임베딩 벡터에서 상기 제1 세트의 임베딩 벡터들 중 임의의 임베딩 벡터로 이동하는 그래디언트 값을 상기 제1 세트의 임베딩 벡터들 중 상기 임의의 임베딩 벡터, 상기 제2 세트의 임베딩 벡터들, 및 상기 내부 파라미터들 간의 조합마다 계산하는 단계; 상기 계산된 모든 조합의 그래디언트 값들을 기반으로 상기 제1 세트의 임베딩 벡터들 중 상기 임의의 임베딩 벡터에 대한 스코어를 생성하는 단계; 및상기 제1 세트의 임베딩 벡터들 각각에 대한 스코어가 생성되면, 상기 생성된 스코어들 중 가장 큰 스코어와 쌍을 이루는 임베딩 벡터를 결정하는 단계; 및상기 결정된 임베딩 벡터에 대응하는 토큰에 오류 가능성이 있다고 판단하는 단계;를 포함하는,구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 방법. |
| 12 | 제8항에 있어서, 상기 대표 확률값은 상기 토큰들의 예측 확률들 중 가장 큰 확률인, 구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 방법. |
| 13 | 제8항에 있어서, 상기 예측 확률은 상기 생성될 구조화된 질의의 임의의 위치에 미리 결정된 토큰들이 배치될 예측 확률이며, 상기 예측 확률을 기반으로 상기 구조화된 질의를 생성하는 단계는, 상기 구조화된 질의의 모든 위치에 있어서, 상기 모든 위치 중 임의의 위치에 배치될 토큰을 상기 예측 확률들 중 가장 큰 확률을 갖는 토큰으로 결정하는 단계; 및상기 모든 위치에서 결정된 단어들을 나열하여 상기 구조화된 질의를 생성하는 단계;를 포함하는,구조화된 질의 및 구조화된 질의의 정확도 예측 정보 생성 방법. |
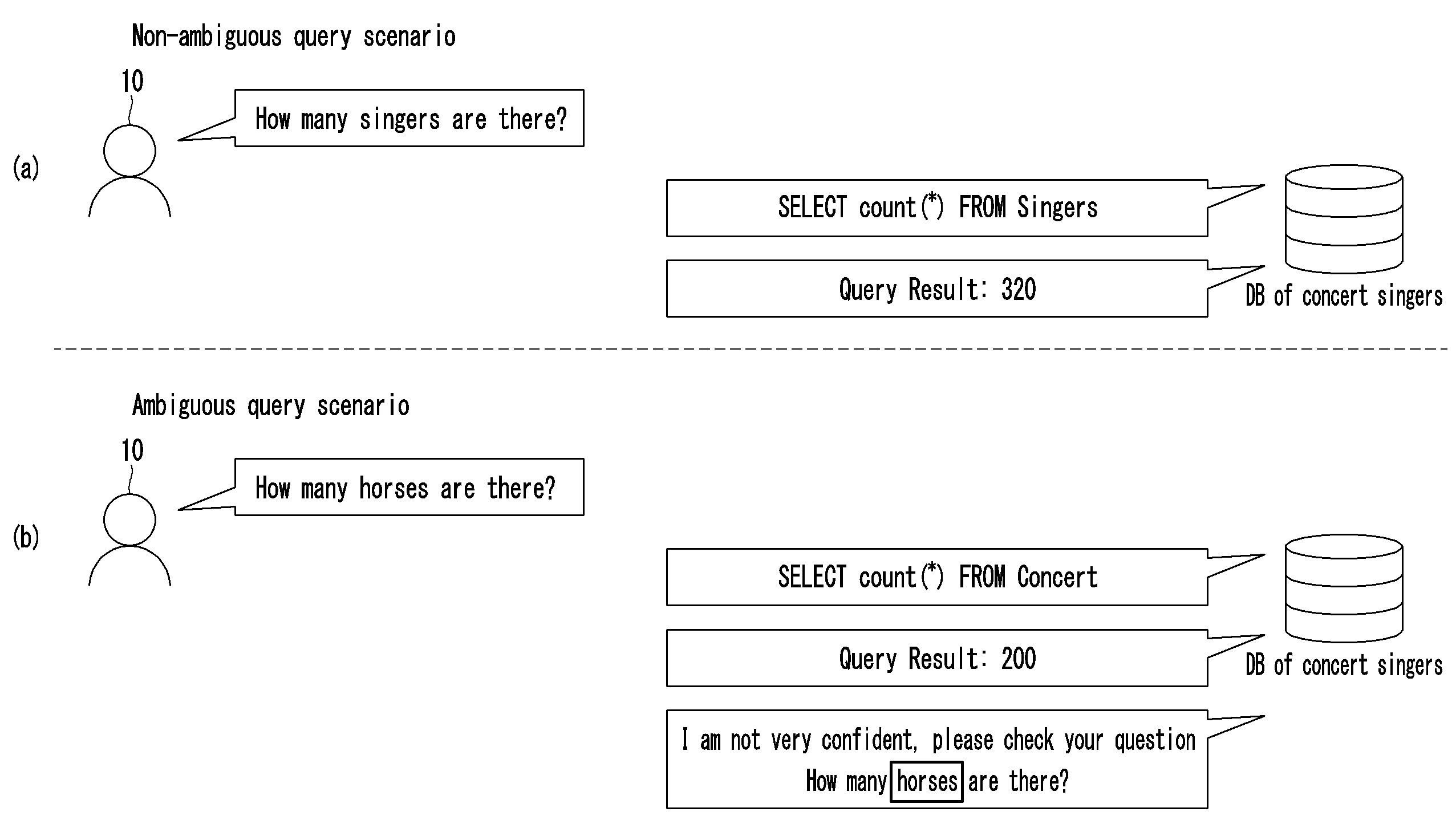
| 14 | 프로세서;를 포함하고,상기 프로세서는,사용자에 의하여 입력된 자연어 질의 문장을 수신하고,상기 자연어 질의 문장을 소정의 모델에 입력하여 생성될 구조화된 질의를 구성하는 토큰들을 선택할 예측 확률을 계산하고, 상기 계산된 예측 확률을 기반으로 상기 구조화된 질의를 생성하고,상기 구조화된 질의에 대응하는 데이터베이스에 상기 구조화된 질의를 검색하여 검색 결과를 획득하고, 상기 토큰들의 예측 확률들에 기반하여 얻어지는 대표 확률값이 소정의 기준치 이하인 경우 상기 생성된 구조화된 질의에 오류가 있다고 판단하고, 상기 생성된 구조화된 질의에 오류가 있다고 판단한 경우, 상기 구조화된 질의에 오류가 있음을 의미하는 자연어 문장을 생성하고, 그리고상기 검색 결과, 및 상기 생성된 자연어 문장을 제공하는,대화형 인터페이스 장치. |
| 15 | 제14항에 있어서, 상기 프로세서가 상기 자연어 질의 문장을 상기 소정의 모델에 입력하기 이전에, 상기 프로세서는 상기 자연어 질의 문장을 구성하는 토큰들에 대한 제1 세트의 임베딩 벡터들을 생성하는,대화형 인터페이스 장치. |
| 16 | 제15항에 있어서, 상기 오류가 있다고 판단한 경우, 상기 프로세서는,상기 제1 세트의 임베딩 벡터들, 상기 소정의 모델이 출력하는 예측 확률들에 따라 결정된 상기 생성된 구조화된 질의를 구성하는 토큰들에 대한 제2 세트의 임베딩 벡터들, 그리고 상기 소정의 모델의 내부 파라미터를 입력 받아 상기 자연어 질의 문장을 구성하는 토큰들 중 하나 이상의 어느 토큰에 오류 가능성이 있는지 판단하는,대화형 인터페이스 장치. |
| 17 | 제16항에 있어서, 상기 프로세서는 상기 오류가 있음을 의미하는 자연어 문장을 생성할 때, 상기 자연어 질의 문장의 상기 오류 가능성이 있다고 판단된 하나 이상의 토큰에 미리 정해진 표시가 된 상기 자연어 질의 문장을 더 생성하여 제공하는, 대화형 인터페이스 장치. |
| 18 | 제16항에 있어서, 상기 프로세서가 상기 하나 이상의 어느 토큰에 오류 가능성이 있는지 판단할 때, 상기 프로세서는,미리 결정된 임베딩 벡터에서 상기 제1 세트의 임베딩 벡터들 중 임의의 임베딩 벡터로 이동하는 그래디언트 값을 상기 제1 세트의 임베딩 벡터들 중 상기 임의의 임베딩 벡터, 상기 제2 세트의 임베딩 벡터들, 및 상기 내부 파라미터들 간의 조합마다 계산하고, 상기 계산된 모든 조합의 그래디언트 값들을 기반으로 상기 제1 세트의 임베딩 벡터들 중 상기 임의의 임베딩 벡터에 대한 스코어를 생성하고,상기 제1 세트의 임베딩 벡터들 각각에 대한 스코어가 생성되면, 상기 생성된 스코어들 중 가장 큰 스코어와 쌍을 이루는 임베딩 벡터를 결정하고, 그리고 상기 결정된 임베딩 벡터에 대응하는 토큰에 오류 가능성이 있다고 판단하는, 대화형 인터페이스 장치. |
| 19 | 제14항에 있어서, 상기 대표 확률값은 상기 토큰들의 예측 확률들 중 가장 큰 확률인, 대화형 인터페이스 장치. |
| 20 | 제14항에 있어서, 상기 예측 확률은 상기 생성될 구조화된 질의의 임의의 위치에 미리 결정된 토큰들이 배치될 예측 확률이며, 상기 프로세서는, 상기 구조화된 질의의 모든 위치에 있어서, 상기 모든 위치 중 임의의 위치에 배치될 토큰을 상기 예측 확률들 중 가장 큰 확률을 갖는 토큰으로 결정하고, 그리고상기 모든 위치에서 결정된 단어들을 나열하여 상기 구조화된 질의를 생성하는,대화형 인터페이스 장치. |