| 번호 | 청구항 |
|---|---|
| 10 | 제1항에 있어서, 상기 제1 워프로부터 상기 제2 워프로 상기 튜플 프로세싱 트리 상의 노드 중 적어도 일부를 재분배하는 단계는, 복수개의 워프들을 포함하는 워프 그룹 내에 적어도 하나 이상의 휴지 상태의 워프가 존재하는 지를 나타내는 비트를 참조하여 휴지 상태의 워프를 검출하는 단계;를 포함하는, GPU 기반 질의 처리 가속 방법. |
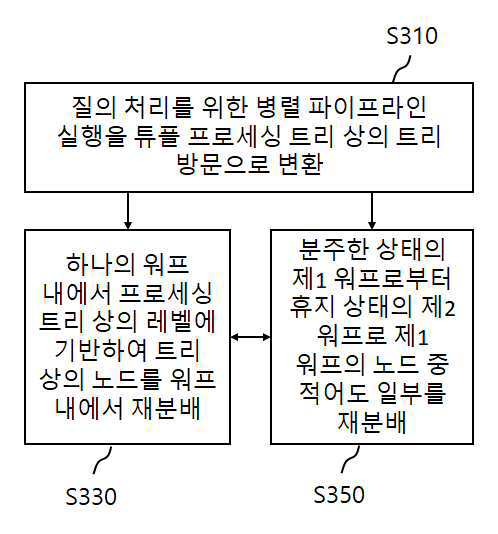
| 1 | GPU 기반 질의 처리 가속 방법으로서, 질의를 처리하기 위한 GPU 상의 병렬적인 파이프라인 실행을 튜플 프로세싱 트리 상의 트리 방문(Tree Traversal)으로 변환하는 단계; 상기 질의를 처리하기 위하여 GPU 상에서 설정되는 하나의 워프(warp) 내에서 상기 튜플 프로세싱 트리 상의 레벨에 기반하여 상기 튜플 프로세싱 트리 상의 노드를 워프 내의 레인에 재분배하는 단계; 및 상기 질의를 처리하기 위한 복수개의 워프들이 분배되는 GPU 상에서, 분주한(busy) 상태의 제1 워프로부터 휴지(idle) 상태의 제2 워프로 상기 제1 워프의 상기 튜플 프로세싱 트리 상의 노드 중 적어도 일부를 재분배하는 단계; 를 포함하고, 상기 파이프라인 실행을 상기 튜플 프로세싱 트리 상의 트리 방문으로 변환하는 단계는, 복수개의 연산자에 대응하는 태스크를 상기 튜플 프로세싱 트리 상의 노드로 배치하는 단계;를 포함하며, 상기 튜플 프로세싱 트리 상의 노드는, 상기 태스크가 실행됨에 따라서 방문 완료된 노드(ENode), 방문 예정으로 식별된 노드(INode), 및 식별되지 않은 노드(UNode)로 구분되는, GPU 기반 질의 처리 가속 방법. |
| 2 | 제1항에 있어서, GPU는 클라우드 컴퓨팅 기법에 의하여 구현되는, GPU 기반 질의 처리 가속 방법. |
| 3 | 제1항에 있어서, 상기 튜플 프로세싱 트리 상의 노드에 대한 구성 정보는 상기 워프 각각에 대응하는 레지스터 파일에 분산적으로 저장되는, GPU 기반 질의 처리 가속 방법. |
| 4 | 제1항에 있어서, 상기 파이프라인 실행을 상기 튜플 프로세싱 트리 상의 트리 방문으로 변환하는 단계는, 상기 질의를 처리하기 위하여 순차적으로 실행되는 상기 복수개의 연산자의 종류에 대응하여 상기 튜플 프로세싱 트리의 레벨을 설정하는 단계; 를 더 포함하는, GPU 기반 질의 처리 가속 방법. |
| 5 | 삭제 |
| 6 | 제1항에 있어서, 상기 튜플 프로세싱 트리 상의 노드를 워프 내의 레인에 재분배하는 단계는, 상기 튜플 프로세싱 트리의 상기 워프에 대응하는 영역 내에서 워프 크기 이상의 개수의 식별된 노드로서 루트 노드로부터 가장 먼 레벨의 제1 식별된 노드를 선택하는 단계; 및 상기 제1 식별된 노드의 적어도 일부를 상기 워프 내의 레인에 재분배하는 단계;를 포함하는, GPU 기반 질의 처리 가속 방법. |
| 7 | 제6항에 있어서, 상기 튜플 프로세싱 트리 상의 노드를 워프 내의 레인에 재분배하는 단계는, 상기 튜플 프로세싱 트리의 상기 워프에 대응하는 영역 내에서 상기 제1 식별된 노드가 발견되지 않으면, 적어도 하나 이상의 식별된 노드로서 루트 노드로부터 가장 가까운 레벨의 제2 식별된 노드를 선택하는 단계; 및 상기 제2 식별된 노드의 적어도 일부를 상기 워프 내의 레인에 재분배하는 단계;를 포함하는, GPU 기반 질의 처리 가속 방법. |
| 8 | 제1항에 있어서, 상기 튜플 프로세싱 트리 상의 노드를 워프 내의 레인에 재분배하는 단계는, 상기 튜플 프로세싱 트리의 상기 워프에 대응하는 영역 내에서 선택된 제1 식별된 노드의 적어도 일부를 상기 튜플 프로세싱 트리의 상기 워프에 대응하는 영역 내의 비어 있는 레인으로 재분배함으로써 상기 레인을 채우는 단계;를 포함하는, GPU 기반 질의 처리 가속 방법. |
| 9 | 제1항에 있어서, 상기 제1 워프로부터 상기 제2 워프로 상기 튜플 프로세싱 트리 상의 노드 중 적어도 일부를 재분배하는 단계는, 전역적으로 휴지 상태의 적어도 하나 이상의 워프 중 하나를 상기 제2 워프로 선택하는 단계; 및 분주한 상태의 상기 제1 워프 내의 노드들 중 루트 노드로부터 가장 가까운 레벨의 노드들 중 적어도 일부를 상기 제2 워프로 재분배하는 단계;를 포함하는, GPU 기반 질의 처리 가속 방법. |
| 11 | 제1항에 있어서, 상기 튜플 프로세싱 트리 상의 노드를 워프 내의 레인에 재분배하는 단계 및 상기 제1 워프로부터 상기 제2 워프로 상기 튜플 프로세싱 트리 상의 노드 중 적어도 일부를 재분배하는 단계는, GPU 내의 공유 메모리 대신 전역 메모리 및 레지스터 파일에 저장되고 업데이트되는 워프 상태 정보를 이용하여 수행되는, GPU 기반 질의 처리 가속 방법. |
| 12 | 제1항에 있어서, 상기 튜플 프로세싱 트리 상의 노드를 워프 내의 레인에 재분배하는 단계 및 상기 제1 워프로부터 상기 제2 워프로 상기 튜플 프로세싱 트리 상의 노드 중 적어도 일부를 재분배하는 단계는, 상기 튜플 프로세싱 트리 상의 노드의 속성 값 대신 상기 노드의 속성이 저장되는 위치만을 참조하여 수행되는, GPU 기반 질의 처리 가속 방법. |
| 13 | GPU 기반 질의 처리 가속이 가능한 컴퓨팅 시스템으로서, GPU 내의 스트리밍 멀티프로세서 내에서 질의를 처리하기 위한 하나씩의 워프(warp)가 할당되는 복수개의 프로세싱 블록들;을 포함하고, 상기 복수개의 프로세싱 블록들은 상기 할당되는 워프 내의 쓰레드를 처리하는 복수개의 프로세서 코어들;을 포함하고, 상기 질의를 처리하기 위한 GPU 상의 병렬적인 파이프라인 실행이 튜플 프로세싱 트리 상의 트리 방문(Tree Traversal)으로 변환되고, 상기 복수개의 프로세싱 블록들 내의 상기 할당되는 워프 내에서 상기 튜플 프로세싱 트리 상의 레벨에 기반하여 상기 튜플 프로세싱 트리 상의 노드가 분주한(busy) 상태의 제1 프로세싱 블록으로부터 휴지(idle) 상태의 제2 프로세싱 블록으로 재분배되고, 상기 복수개의 프로세싱 블록들 각각 내에서 상기 튜플 프로세싱 트리 상의 레벨에 기반하여 상기 튜플 프로세싱 트리 상의 노드가 상기 프로세싱 블록 각각 내의 상기 복수 개의 프로세서 코어들 간에 재분배되고,상기 파이프라인 실행이 상기 튜플 프로세싱 트리 상의 트리 방문으로 변환될 때 복수개의 연산자에 대응하는 태스크가 상기 튜플 프로세싱 트리 상의 노드로 배치되며, 상기 튜플 프로세싱 트리 상의 노드는, 상기 태스크가 실행됨에 따라서 방문 완료된 노드(ENode), 방문 예정으로 식별된 노드(INode), 및 식별되지 않은 노드(UNode)로 구분되는, GPU 기반 질의 처리 가속이 가능한 컴퓨팅 시스템. |
| 14 | 제13항에 있어서, GPU는 클라우드 컴퓨팅 기법에 의하여 구현되는, GPU 기반 질의 처리 가속이 가능한 컴퓨팅 시스템. |
| 15 | 제13항에 있어서, 상기 튜플 프로세싱 트리 상의 노드에 대한 구성 정보는 상기 복수개의 프로세싱 블록들 각각에 대응하는 레지스터 파일에 분산적으로 저장되는, GPU 기반 질의 처리 가속이 가능한 컴퓨팅 시스템. |
| 16 | 삭제 |
| 17 | 제13항에 있어서, 상기 복수개의 프로세싱 블록들 각각 내에서, 상기 튜플 프로세싱 트리의 상기 워프에 대응하는 영역 내에서 워프 크기 이상의 개수의 식별된 노드로서 루트 노드로부터 가장 먼 레벨의 제1 식별된 노드가 선택되고, 상기 제1 식별된 노드의 적어도 일부가 상기 프로세싱 블록 내의 상기 복수 개의 프로세서 코어들 간에 재분배되는, GPU 기반 질의 처리 가속이 가능한 컴퓨팅 시스템. |
| 18 | 제17항에 있어서, 상기 복수개의 프로세싱 블록들 각각 내에서, 상기 튜플 프로세싱 트리의 상기 워프에 대응하는 영역 내에서 상기 제1 식별된 노드가 발견되지 않으면, 적어도 하나 이상의 식별된 노드로서 루트 노드로부터 가장 가까운 레벨의 제2 식별된 노드가 선택되고, 상기 제2 식별된 노드의 적어도 일부가 상기 프로세싱 블록 내의 상기 복수 개의 프로세서 코어들 간에 재분배되는, GPU 기반 질의 처리 가속이 가능한 컴퓨팅 시스템. |
| 19 | 제13항에 있어서, 상기 복수개의 프로세싱 블록들 각각 내에서, 상기 튜플 프로세싱 트리의 상기 워프에 대응하는 영역 내에서 선택된 식별된 노드의 적어도 일부가 상기 복수개의 프로세싱 블록들 각각 내의 비어 있는 프로세서 코어로 재분배됨으로써 상기 프로세서 코어에 대응하는 레인이 채워지는, GPU 기반 질의 처리 가속이 가능한 컴퓨팅 시스템. |
| 20 | 제13항에 있어서, 전역적으로 휴지 상태의 적어도 하나 이상의 워프 중 하나가 상기 제2 프로세싱 블록에 대응하는 제2 워프로 선택되고, 분주한 상태의 상기 제1 프로세싱 블록에 대응하는 제1 워프 내의 노드들 중 루트 노드로부터 가장 가까운 레벨의 노드들 중 적어도 일부가 상기 제2 워프로서 상기 제2 프로세싱 블록에 재분배되는, GPU 기반 질의 처리 가속이 가능한 컴퓨팅 시스템. |