| 번호 | 청구항 |
|---|---|
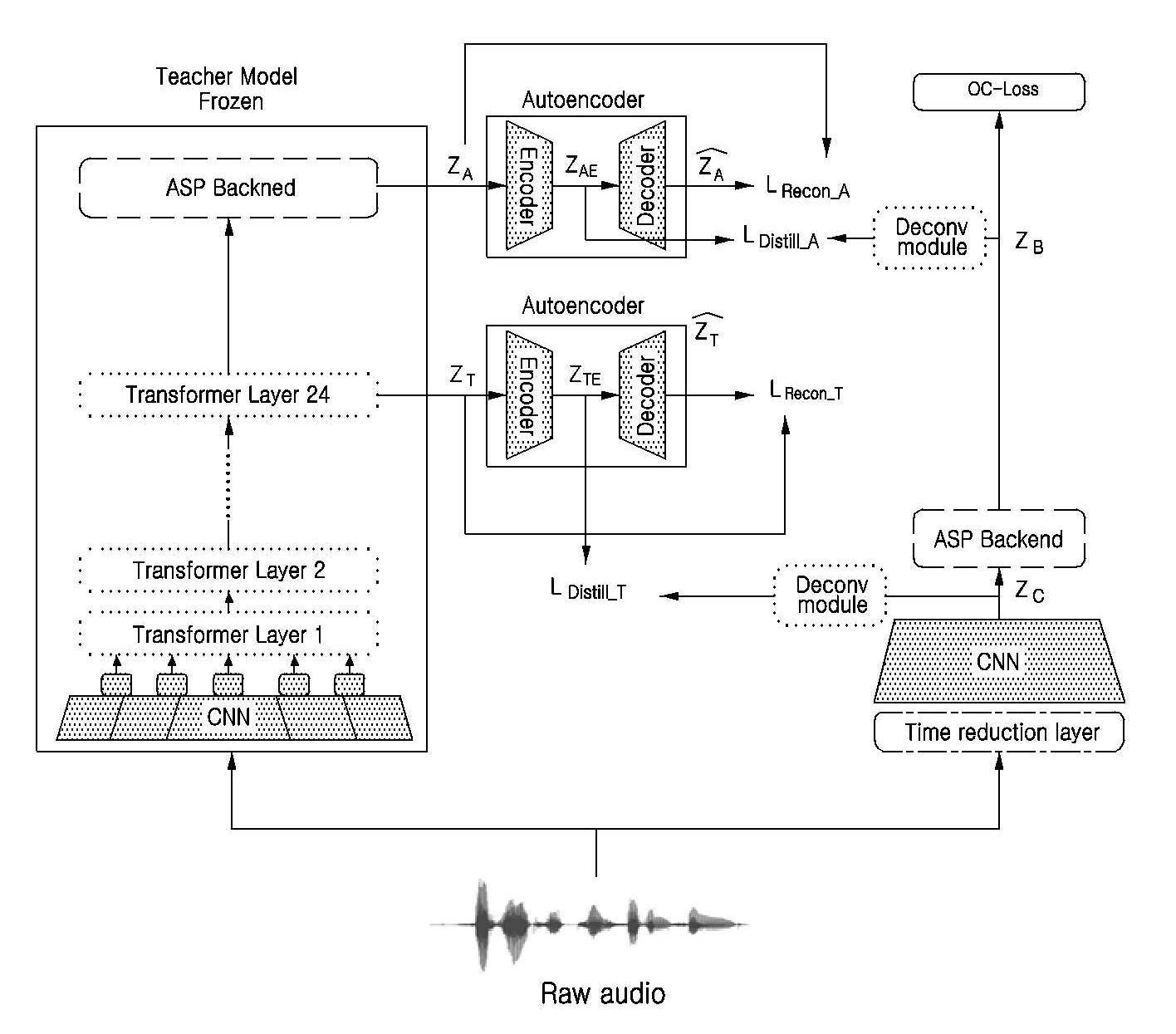
| 1 | 합성음성 탐지 시스템에 의해 수행되는 합성음성 탐지 방법에 있어서,음성 데이터를 이용하여 실제 음성과 합성 음성이 구분되도록 교사 모델(Teacher)을 학습하는 단계; 지식 증류(Knowledge Distillation) 기법에 기초하여 상기 학습된 교사 모델의 지식 정보를 학생 모델에게 전달하는 단계; 및 상기 전달받은 교사 모델의 지식 정보를 이용하여 경량화된 학생 모델을 구축하는 단계를 포함하고,상기 구축된 경량화된 학생 모델은, 온디바이스(on-device) 환경에서 사용자로부터 입력된 음성 신호로부터 합성 음성을 탐지하는 것 을 포함하는 합성음성 탐지 방법. |
| 2 | 제1항에 있어서,상기 교사 모델(Teacher)은, 특징 추출기 및 분류기로 구성되고, 상기 분류기는, ASP(Attentive statistics pooling) 레이어를 사용하고,상기 특징 추출기는, 상기 음성 데이터를 이용하여 합성 음성과 구분되는 실제 음성의 특징 정보를 학습하고, 상기 학습을 통해 실제 음성이 공유하고 있는 공통의 특징 정보를 추출하는 것을 포함하고,상기 분류기는, 상기 추출된 공통의 특징 정보를 이용하여 실제 음성과 합성 음성이 구분되는 특징 정보가 나타나는 시간 단위를 강조하는 것을 특징으로 하는 합성음성 탐지 방법. |
| 3 | 제2항에 있어서,상기 분류기는, 인코더를 통해 음성 데이터로부터 복수 개의 프레임을 갖는 특징 벡터를 추출하고,상기 추출된 특징 벡터에 대해 평균과 표준편차를 계산하고,어텐션 메커니즘을 통해 상기 계산된 평균과 표준편차를 이용하여 실제 음성과 합성 음성의 특징 정보를 파악하는데 더 중요한 시간 프레임에 어텐션 스코어(score)을 부여하고,상기 부여된 어텐션 스코어의 값을 각 프레임에 곱하여 가중 평균 벡터를 도출하고,상기 도출된 가중 평균 벡터에 대해 가중 표준 편차를 계산하고,상기 도출된 가중 평균 벡터와 상기 계산된 가중 표준 편차를 이용하여 상기 음성 데이터로부터 표현 벡터를 획득하는 것을 특징으로 하는 합성음성 탐지 방법. |
| 4 | 제1항에 있어서,상기 교사 모델의 손실함수는, 단일 클래스 분류 기법을 사용하여 구성된 것이고,상기 단일 클래스 분류 기법은, 실제 음성의 데이터 분포를 학습함에 따라 상기 실제 음성을 대표하는 중심 벡터를 정의하고, 상기 정의된 중심 벡터를 중심으로 설정된 경계선에 기초하여 경계선 밖의 데이터 분포를 가지는 샘플에 대하여 합성 음성으로 간주하는 것을 특징으로 하는 합성음성 탐지 방법. |
| 5 | 제4항에 있어서,상기 교사 모델은,적응형 중심체 이동(Adaptive Centroid Shift, ACS) 기법을 사용하여 실제 음성의 샘플이 미니 배치 내에 존재하는 경우에만 상기 실제 음성의 샘플의 가중 평균에 의해 중심 벡터를 지속적으로 업데이트하고,실제 음성 클래스 임베딩을 상기 업데이트를 통해 정의된 중심 벡터에 가깝게, 합성 음성 클래스 임베딩을 상기 업데이트를 통해 정의된 중심 벡터에 멀어지도록 설정하는 것을 특징으로 하는 합성음성 탐지 방법. |
| 6 | 제1항에 있어서,상기 학생 모델은, 시간 단축(time reduction) 레이어, 특징 추출기, 분류기로 구성되고,상기 시간 단축 레이어를 통해 상기 학습 모델의 프레임의 수를 1/2 감소시키고, 상기 특징 추출기는, CNN 레이어를 포함하고,상기 분류기는, ASP(Attentive statistics pooling) 레이어를 포함하는 것을 특징으로 하는 합성음성 탐지 방법. |
| 7 | 제1항에 있어서,상기 전달하는 단계는,디컨볼루션 모듈을 통해 상기 교사 모델과 동일한 시간축을 가질 수 있도록 상기 학생 모델의 시간축을 조정하는 단계 를 포함하는 합성음성 탐지 방법. |
| 8 | 제1항에 있어서,상기 전달하는 단계는,오토인코더를 통해 상기 학생 모델의 채널축을 상기 교사 모델의 채널축과 동일하게 조정한 후, 상기 교사 모델에 구성된 특징 추출기의 지식 정보를 상기 학생 모델에 구성된 특징 추출기로 전달하는 단계를 포함하는 합성음성 탐지 방법. |
| 9 | 제1항에 있어서,상기 전달하는 단계는,디컨볼루션 모듈을 통해 상기 학생 모델의 시간축을 상기 교사 모델의 시간축으로 복원하고, 상기 교사 모델에서 오토인코더를 통해 기 설정된 값 이하의 차원 정보를 보존하여 상기 교사 모델에 구성된 분류기의 지식 정보를 상기 학생 모델에 구성된 분류기로 전달하는 단계것을 특징으로 하는 합성음성 탐지 방법. |
| 10 | 제1항에 있어서,상기 전달하는 단계는,상기 교사 모델의 중심 벡터를 상기 학생 모델의 초기 중심 벡터로 사용한 후, 적응형 중심체 이동 기법을 사용하여 중심 벡터를 지속적으로 업데이트하는 단계를 포함하는 합성음성 탐지 방법. |
| 11 | 제1항에 있어서,상기 음성 데이터를 증강하는 단계를 더 포함하고, 상기 증강하는 단계는,다중 대역 필터링(multi-band filtering)과 해머스타인 시스템(Hammerstein systems)의 조합을 통해 선형 및 비선형 컨볼루션 노이즈가 반영된 음성 데이터를 증강하는 단계를 포함하는 합성음성 탐지 방법. |
| 12 | 제11항에 있어서,상기 증강하는 단계는,임펄스 신호 의존 부가 잡음(Impulsive signal-dependent additive noise)을 통해 음성 데이터를 증강하는 단계를 포함하는 합성음성 탐지 방법. |
| 13 | 제11항에 있어서,상기 증강하는 단계는,정상 신호 독립적 부가 잡음(Stationary signal-independent additive noise)을 통해 음성 데이터를 증강하는 단계를 포함하는 합성음성 탐지 방법. |
| 14 | 합성음성 탐지 시스템에 의해 수행되는 합성음성 탐지 방법을 실행시키기 위해 컴퓨터 판독 가능한 저장매체에 저장된 컴퓨터 프로그램에 있어서,상기 합성음성 탐지 방법은, 음성 데이터를 이용하여 실제 음성과 합성 음성이 구분되도록 교사 모델(Teacher)을 학습하는 단계; 지식 증류(Knowledge Distillation) 기법에 기초하여 상기 학습된 교사 모델의 지식 정보를 학생 모델에게 전달하는 단계; 및상기 전달받은 교사 모델의 지식 정보를 이용하여 경량화된 학생 모델을 구축하는 단계를 포함하고,상기 구축된 경량화된 학생 모델은, 온디바이스(on-device) 환경에서 사용자로부터 입력된 음성 신호로부터 합성 음성을 탐지하는 것 을 실행하는 컴퓨터 판독 가능한 저장매체에 저장된 컴퓨터 프로그램. |
| 15 | 합성음성 탐지 시스템에 있어서,음성 데이터를 이용하여 실제 음성과 합성 음성이 구분되도록 교사 모델(Teacher)을 학습하는 교사 모델 학습부; 지식 증류(Knowledge Distillation) 기법에 기초하여 상기 학습된 교사 모델의 지식 정보를 학생 모델에게 전달하는 지식 정보 전달부; 및상기 전달받은 교사 모델의 지식 정보를 이용하여 경량화된 학생 모델을 구축하는 학생 모델 구축부를 포함하고,상기 구축된 경량화된 학생 모델은, 온디바이스(on-device) 환경에서 사용자로부터 입력된 음성 신호로부터 합성 음성을 탐지하는 것 을 포함하는 합성음성 탐지 시스템. |