| 번호 | 청구항 |
|---|---|
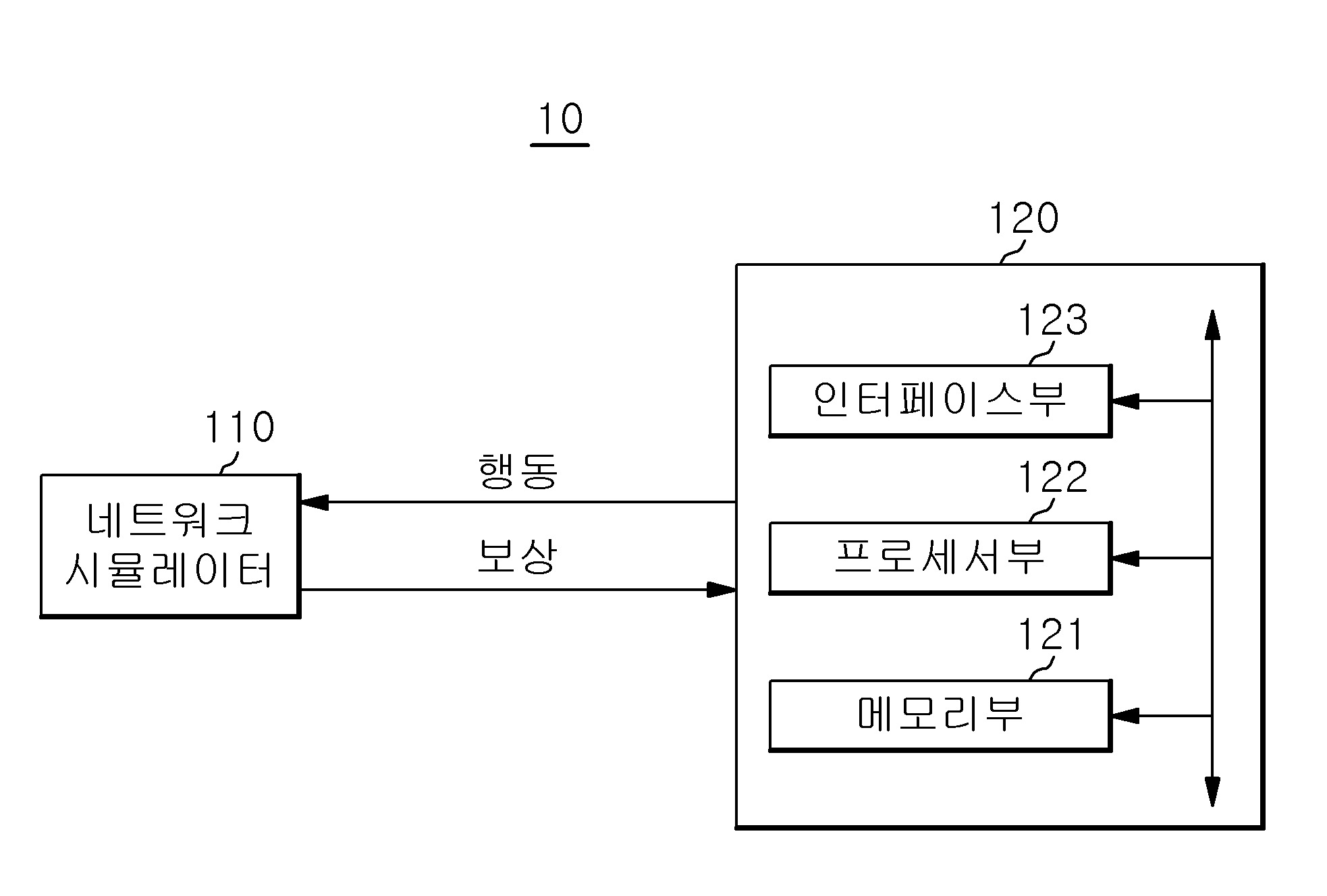
| 1 | 컴퓨터 장치가 수행하는 지리적 애드혹 라우팅 강화학습 방법으로서,복수의 이동체에 대한 지리적 애드혹 라우팅의 네트워크 시뮬레이팅 환경으로부터 라우팅에 있어서 현재 시점 판단의 주체가 되는 제 1 노드를 의미하는 관찰(observation) 값을 획득하는 단계와,상기 획득된 관찰 값을 기반으로 상기 네트워크 시뮬레이팅 환경의 상기 복수의 이동체에 대한 시간 축에 따른 사전 이동성을 고려한 라우팅 경로에서 다음 라우트인 제 2 노드를 선택하는 행동(action)을 판단하여 상기 네트워크 시뮬레이팅 환경으로 전달하는 단계와,상기 행동을 기반으로 한 보상(reward)을 상기 네트워크 시뮬레이팅 환경으로부터 획득하는 단계를 포함하고,상기 행동을 판단하여 상기 네트워크 시뮬레이팅 환경으로 전달하는 단계에서,처음 observation space와 action space를 상기 네트워크 시뮬레이팅 환경과 동일하게 상기 복수의 이동체에 대응하는 노드의 총 수로 설정하고,Q-learning을 기반으로 학습될 보상의 기대값인 q-value들을 모두 음의 무한대로 설정하며,상기 각 행동에 대한 미래의 보상(q-value)을 갱신할 Q-Table을 상기 시간 축에 대한 정보를 활용해 각 시간 축 단위마다 하나씩 구성하여 여러 Q-Table의 집합을 만들어 사용하고,상기 라우팅 경로에서 제1 노드의 다음 라우트인 제2 노드를 선택하는 행동에 대응하는 상기 q-value를 수학식 1을 통해 갱신하는(수학식 1) (여기서, st는 current node, at는 행동으로 판단된 다음 노드, 보상은 QGeo 알고리즘에 따라 정의된 앞의 서술된 보상 함수(reward function)의 값, st+1은 관찰을 통해 받아온 다음 노드)지리적 애드혹 라우팅 강화학습 방법. |
| 2 | 제 1 항에 있어서,상기 라우팅 경로에서 상기 제 1 노드와 상기 제 2 노드 및 목적지 노드까지의 거리가 가까워질수록 상기 보상이 높게 획득되고, 상기 제 1 노드와 상기 제 2 노드 및 목적지 노드가 가지는 링크 에러(link error) 및 위치 에러(location error)가 작을수록 상기 보상이 높게 획득되는지리적 애드혹 라우팅 강화학습 방법. |
| 3 | 삭제 |
| 4 | 제 1 항에 있어서,상기 Q-learning을 기반으로 학습은, 랜덤한 행동을 실행시켜 상기 Q-Table에 새로운 데이터를 누적하기 위한 exploration과, 학습된 지식을 사용하여 판단을 내리기 위한 exploitation으로 나뉘는지리적 애드혹 라우팅 강화학습 방법. |
| 5 | 제 4 항에 있어서,상기 랜덤한 행동으로서, 일정한 1 미만의 상수 epsilon을 정의하여, 랜덤하게 생성된 1 미만의 수가 상기 상수 epsilon보다 작을 경우, 상기 각 행동에 대하여 무작위의 행동을 선정하고, 상기 선정된 무작위의 행동은 상기 네트워크 시뮬레이팅 환경으로 전달되는지리적 애드혹 라우팅 강화학습 방법. |
| 6 | 제 5 항에 있어서,상기 랜덤하게 생성된 1 미만의 수가 상기 상수 epsilon보다 클 경우, current node에 대응하는 상기 Q-Table에서 가장 기댓값이 높은 index를 검출하고, 상기 검출된 index의 노드를 라우팅에 있어서 선택될 다음 노드로 설정하는지리적 애드혹 라우팅 강화학습 방법. |
| 7 | 삭제 |
| 8 | 적어도 하나의 명령어를 저장하는 메모리부와,프로세서부를 포함하며,상기 프로세서부에 의해 상기 적어도 하나의 명령어가 실행됨으로써,복수의 이동체에 대한 지리적 애드혹 라우팅의 네트워크 시뮬레이팅 환경으로부터 라우팅에 있어서 현재 시점 판단의 주체가 되는 제 1 노드를 의미하는 관찰 값을 획득하고,상기 획득된 관찰 값을 기반으로 상기 네트워크 시뮬레이팅 환경의 상기 복수의 이동체에 대한 시간 축에 따른 사전 이동성을 고려한 라우팅 경로에서 다음 라우트인 제 2 노드를 선택하는 행동을 판단하여 상기 네트워크 시뮬레이팅 환경으로 전달하며,상기 행동을 기반으로 한 보상을 상기 네트워크 시뮬레이팅 환경으로부터 획득하고,상기 행동을 판단하여 상기 네트워크 시뮬레이팅 환경으로 전달할 때에,처음 observation space와 action space를 상기 네트워크 시뮬레이팅 환경과 동일하게 상기 복수의 이동체에 대응하는 노드의 총 수로 설정하고,Q-learning을 기반으로 학습될 보상의 기대값인 q-value들을 모두 음의 무한대로 설정하며,상기 각 행동에 대한 미래의 보상(q-value)을 갱신할 Q-Table을 상기 시간 축에 대한 정보를 활용해 각 시간 축 단위마다 하나씩 구성하여 여러 Q-Table의 집합을 만들어 사용하고,상기 라우팅 경로에서 제1 노드의 다음 라우트인 제2 노드를 선택하는 행동에 대응하는 상기 q-value를 수학식 1을 통해 갱신하는(수학식 1) (여기서, st는 current node, at는 행동으로 판단된 다음 노드, 보상은 QGeo 알고리즘에 따라 정의된 앞의 서술된 보상 함수(reward function)의 값, st+1은 관찰을 통해 받아온 다음 노드)컴퓨터 장치. |
| 9 | 제 8 항에 있어서,상기 라우팅 경로에서 상기 제 1 노드와 상기 제 2 노드 및 목적지 노드까지의 거리가 가까워질수록 상기 보상이 높게 획득되고, 상기 제 1 노드와 상기 제 2 노드 및 목적지 노드가 가지는 링크 에러(link error) 및 위치 에러(location error)가 작을수록 상기 보상이 높게 획득되는컴퓨터 장치. |
| 10 | 삭제 |
| 11 | 제 8 항에 있어서,상기 Q-learning을 기반으로 학습은, 랜덤한 행동을 실행시켜 상기 Q-Table에 새로운 데이터를 누적하기 위한 exploration과, 학습된 지식을 사용하여 판단을 내리기 위한 exploitation으로 나뉘는컴퓨터 장치. |
| 12 | 제 11 항에 있어서,상기 랜덤한 행동으로서, 일정한 1 미만의 상수 epsilon을 정의하여, 랜덤하게 생성된 1 미만의 수가 상기 상수 epsilon보다 작을 경우, 상기 각 행동에 대하여 무작위의 행동을 선정하고, 상기 선정된 무작위의 행동은 상기 네트워크 시뮬레이팅 환경으로 전달되는컴퓨터 장치. |
| 13 | 제 12 항에 있어서,상기 랜덤하게 생성된 1 미만의 수가 상기 상수 epsilon보다 클 경우, current node에 대응하는 상기 Q-Table에서 가장 기댓값이 높은 index를 검출하고, 상기 검출된 index의 노드를 라우팅에 있어서 선택될 다음 노드로 설정하는컴퓨터 장치. |
| 14 | 삭제 |
| 15 | 컴퓨터 프로그램을 저장하고 있는 컴퓨터 판독 가능 기록매체로서,상기 컴퓨터 프로그램은, 프로세서에 의해 실행되면,복수의 이동체에 대한 지리적 애드혹 라우팅의 네트워크 시뮬레이팅 환경으로부터 라우팅에 있어서 현재 시점 판단의 주체가 되는 제 1 노드를 의미하는 관찰 값을 획득하는 단계와,상기 획득된 관찰 값을 기반으로 상기 네트워크 시뮬레이팅 환경의 상기 복수의 이동체에 대한 시간 축에 따른 사전 이동성을 고려한 라우팅 경로에서 다음 라우트인 제 2 노드를 선택하는 행동을 판단하여 상기 네트워크 시뮬레이팅 환경으로 전달하는 단계와,상기 행동을 기반으로 한 보상을 상기 네트워크 시뮬레이팅 환경으로부터 획득하는 단계를 포함하고, 상기 행동을 판단하여 상기 네트워크 시뮬레이팅 환경으로 전달하는 단계에서,처음 observation space와 action space를 상기 네트워크 시뮬레이팅 환경과 동일하게 상기 복수의 이동체에 대응하는 노드의 총 수로 설정하고,Q-learning을 기반으로 학습될 보상의 기대값인 q-value들을 모두 음의 무한대로 설정하며,상기 각 행동에 대한 미래의 보상(q-value)을 갱신할 Q-Table을 상기 시간 축에 대한 정보를 활용해 각 시간 축 단위마다 하나씩 구성하여 여러 Q-Table의 집합을 만들어 사용하고,상기 라우팅 경로에서 제1 노드의 다음 라우트인 제2 노드를 선택하는 행동에 대응하는 상기 q-value를 수학식 1을 통해 갱신하는(수학식 1) (여기서, st는 current node, at는 행동으로 판단된 다음 노드, 보상은 QGeo 알고리즘에 따라 정의된 앞의 서술된 보상 함수(reward function)의 값, st+1은 관찰을 통해 받아온 다음 노드)지리적 애드혹 라우팅 강화학습 방법을 상기 프로세서가 수행하도록 하기 위한 명령어를 포함하는컴퓨터 판독 가능한 기록매체. |
| 16 | 컴퓨터 판독 가능 기록매체에 저장된 컴퓨터 프로그램으로서,상기 컴퓨터 프로그램은, 프로세서에 의해 실행되면,복수의 이동체에 대한 지리적 애드혹 라우팅의 네트워크 시뮬레이팅 환경으로부터 라우팅에 있어서 현재 시점 판단의 주체가 되는 제 1 노드를 의미하는 관찰 값을 획득하는 단계와,상기 획득된 관찰 값을 기반으로 상기 네트워크 시뮬레이팅 환경의 상기 복수의 이동체에 대한 시간 축에 따른 사전 이동성을 고려한 라우팅 경로에서 다음 라우트인 제 2 노드를 선택하는 행동을 판단하여 상기 네트워크 시뮬레이팅 환경으로 전달하는 단계와,상기 행동을 기반으로 한 보상을 상기 네트워크 시뮬레이팅 환경으로부터 획득하는 단계를 포함하고,상기 행동을 판단하여 상기 네트워크 시뮬레이팅 환경으로 전달하는 단계에서,처음 observation space와 action space를 상기 네트워크 시뮬레이팅 환경과 동일하게 상기 복수의 이동체에 대응하는 노드의 총 수로 설정하고,Q-learning을 기반으로 학습될 보상의 기대값인 q-value들을 모두 음의 무한대로 설정하며,상기 각 행동에 대한 미래의 보상(q-value)을 갱신할 Q-Table을 상기 시간 축에 대한 정보를 활용해 각 시간 축 단위마다 하나씩 구성하여 여러 Q-Table의 집합을 만들어 사용하고,상기 라우팅 경로에서 제1 노드의 다음 라우트인 제2 노드를 선택하는 행동에 대응하는 상기 q-value를 수학식 1을 통해 갱신하는(수학식 1) (여기서, st는 current node, at는 행동으로 판단된 다음 노드, 보상은 QGeo 알고리즘에 따라 정의된 앞의 서술된 보상 함수(reward function)의 값, st+1은 관찰을 통해 받아온 다음 노드)지리적 애드혹 라우팅 강화학습 방법을 상기 프로세서가 수행하도록 하기 위한 명령어를 포함하는컴퓨터 프로그램. |