| 번호 | 청구항 |
|---|---|
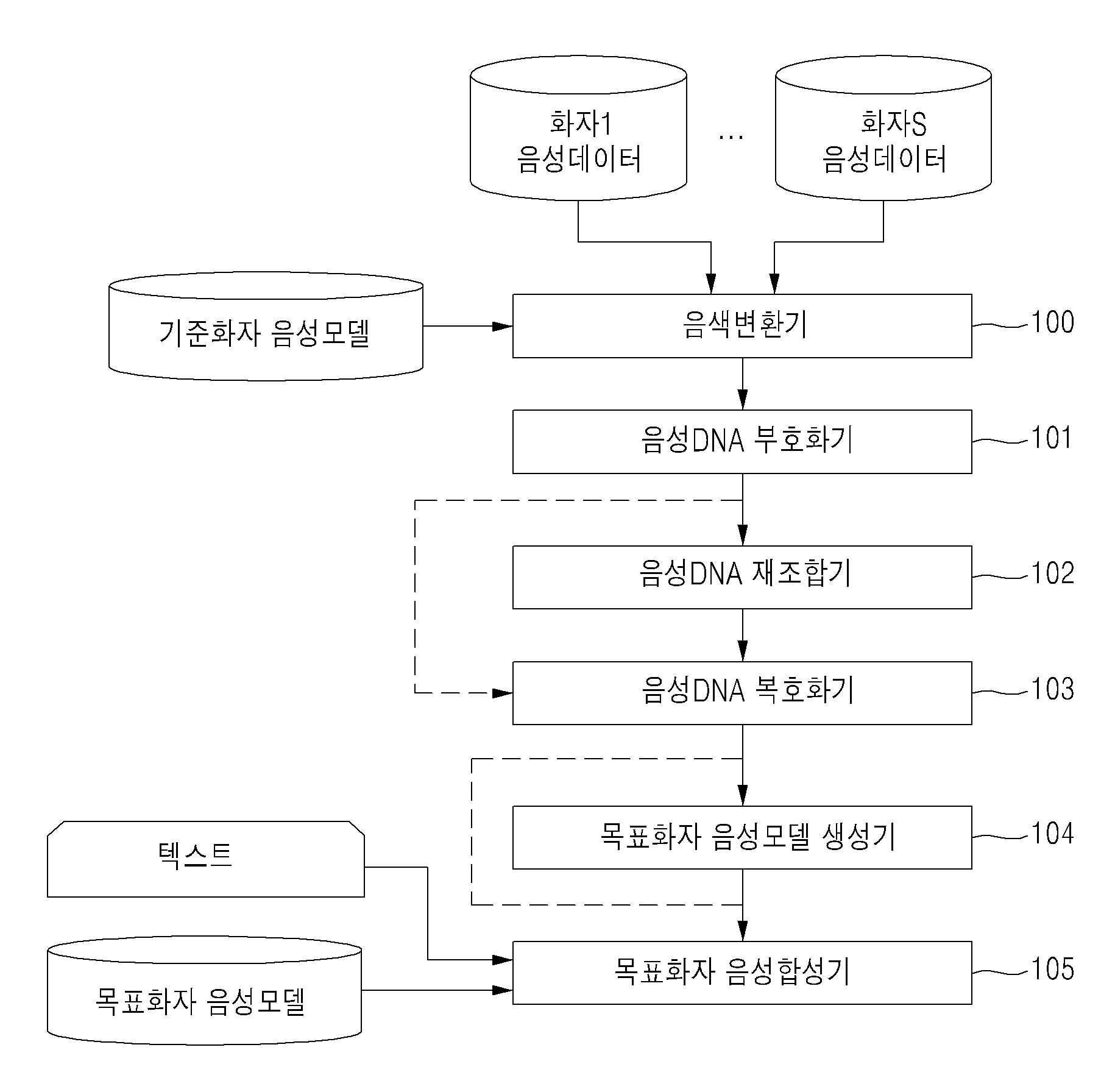
| 1 | 기준화자 음색의 음성합성을 위한 음성모델에 특정화자의 음성데이터와 화자적응 기법을 적용하여 특정화자 음성모델을 생성하는 음색변환기; 상기 음색변환기를 사용하여 특정화자의 음색을 나타내도록 음성모델을 변환시키는 음색변환정보 또는 변환된 특정화자 음성모델을 음성DNA 정보로 부호화하는 음성DNA 부호화기;상기 음성DNA 부호화기로부터 생성된 복수의 화자들의 음성DNA 정보를 기설정된 비율로 재조합하여 목표화자 음성DNA 정보를 합성하는 음성DNA 재조합기;상기 음성DNA 부호화기나 상기 음성DNA 재조합기를 사용하여 획득된 음성DNA 정보를 복호화하는 음성DNA 복호화기;상기 음성DNA 복호화기를 사용하여 복원된 목표화자의 음색변환정보를 활용하여 상기 기준화자 음성모델로부터 목표화자 음성모델을 생성하는 목표화자 음성모델 생성기; 및상기 음성DNA 복호화기나 상기 목표화자 음성모델 생성기를 사용하여 복원된 목표화자 음성모델에 기초하여 입력된 텍스트에 해당하는 음성파형을 합성하는 목표화자 음성합성기를 포함하는 음성합성 장치. |
| 2 | 제1항에 있어서,상기 음색변환기는,사용자들로부터 수집된 화자적응 음성데이터에 대해 기설정된 길이의 프레임들로 이동하면서 반복적으로 분할하여 음성 프레임열을 형성한 후, 상기 음성 프레임열에 대하여 상기 음성합성을 위한 음성모델링에 따른 특징벡터의 추출을 반복하여 특징 파라메터열을 추출함으로써 획득한 음성특징데이터를 최대우도선형회귀 화자적응 기법, 최대사후 화자적응 기법 또는 i-vector 화자적응 기법 중 적어도 하나의 기법을 적용하여 특정화자의 음성모델로 음색변환시키는것을 특징으로 하는 음성합성 장치. |
| 3 | 제1항에 있어서,상기 음성DNA 부호화기는, 상기 음색변환기에 의해 특정화자의 음색으로 변환된 음성모델인 HMM의 평균벡터, 공분산행렬, 혼합계수나, 최대우도선형회귀 기법이나 i-vector 기법에 의해 획득된 음색변환정보인 행렬이나 벡터 자체를 디지털 음성DNA 정보로 부호화 또는 상기 획득된 음색변환정보인 행렬이나 벡터 자체에 압축 부호화 알고리즘을 적용하여 디지털 음성DNA 정보로 부호화하는것을 특징으로 하는 음성합성 장치. |
| 4 | 제1항에 있어서,상기 음성DNA 재조합기는,상기 화자들로부터 획득된 상기 음성DNA 정보를 읽고, 상기 복수의 화자들의 음성DNA 정보를 조건을 만족하는 기설정된 비율로 서로 재조합하여 가상의 목표화자에 대한 음성DNA 정보를 합성하는것을 특징으로 하는 음성합성 장치. |
| 5 | 제1항에 있어서,상기 음성DNA 복호화기는,상기 부호화된 음성DNA 정보를 읽고, 상기 음성DNA 부호화기에서 선택적으로 적용한 압축 부호화 알고리즘에 대응하는 복호화 알고리즘을 적용하여 음성DNA 정보를 음성모델정보로 복원하거나 음색변환정보로 복원하는것을 특징으로 하는 음성합성 장치. |
| 6 | 제1항에 있어서,상기 목표화자 음성모델 생성기는,상기 복호화된 음성DNA 정보가 상기 음색변환정보일 경우에, 음색변환정보와 상기 기준화자 음성모델을 읽고, 음색변환정보를 변환 파라메터로 활용하여 최대우도선형회귀 기법이나 i-vector 기법으로 상기 기준화자 음성모델을 상기 목표화자 음성모델로 변환하는것을 특징으로 하는 음성합성 장치. |
| 7 | 제1항에 있어서,상기 목표화자 음성합성기는,상기 목표화자 음성모델을 읽고, 합성할 텍스트 정보를 입력받아 해당 음성파형을 HMM 기반 합성 기법에 의해 합성하는것을 특징으로 하는 음성합성 장치. |
| 8 | 기준화자 음성모델에 특정화자가 발성한 음성데이터를 사용하는 화자적응 기법을 적용하여 특정화자의 음색으로 음성모델을 변환하는 음색변환 단계;상기 음색변환 단계에서 변환된 특정화자의 음성모델이나 특정화자의 음색을 나타내도록 음성모델을 변환시키는 정보를 음성DNA 정보로 부호화하는 음성DNA 부호화 단계;상기 부호화된 복수의 화자들의 음성DNA 정보를 기설정된 비율로 재조합하여 목표화자 음성DNA 정보를 합성하는 음성DNA 재조합 단계;상기 음성DNA 부호화 단계에서 획득된 특정화자 음성DNA 정보나 상기 음성DNA 재조합 단계에서 획득된 목표화자 음성DNA 정보를 복호화하여 음색변환정보나 음성모델을 복원하는 음성DNA 복호화 단계;상기 복원된 특정화자 음색변환정보를 활용하는 화자적응 기법을 기준화자 음성모델에 적용하여 목표화자 음성모델을 생성하는 목표화자 음성모델 생성 단계; 및임의의 텍스트 입력에 대해 상기 목표화자 음성모델 생성 단계로부터 획득된 목표화자 음성모델을 활용하여 목표화자 음색의 음성파형을 합성하는 목표화자 음성합성 단계를 포함하는 음성합성 방법. |
| 9 | 제8항에 있어서,상기 음색변환 단계는,사용자들로부터 수집된 화자적응 음성데이터에 대해 일정 길이의 프레임으로 일정 간격만큼 이동하면서 반복적으로 분할하여 음성 프레임열을 추출하는 단계;상기 음성 프레임열에 대하여 상기 음성합성을 위한 음성모델링에 따른 특징벡터의 추출을 반복하여 특징 파라메터열을 추출하는 단계;음성특징데이터에 대하여 최대우도선형회귀 화자적응 기법을 적용하여 특정화자의 음성모델로 음색변환시키는 단계;상기 음성특징데이터에 대하여 최대사후 화자적응 기법을 적용하여 특정화자의 음성모델로 음색변환하는 단계; 및상기 음성특징데이터에 대하여 i-vector 화자적응 기법을 적용하여 특정화자의 음성모델로 음색변환하는 단계를 포함하는 음성합성 방법. |
| 10 | 제8항에 있어서,상기 음성DNA 부호화 단계는, 음색변환기에 의해 특정화자의 음색으로 변환된 음성모델인 HMM의 평균벡터, 공분산행렬, 혼합계수나, 최대우도선형회귀 기법이나 i-vector 기법에 의해 획득된 음색변환정보인 행렬이나 벡터 자체를 디지털 음성DNA 정보로 부호화 또는 상기 획득된 음색변환정보인 행렬이나 벡터 자체에 압축 부호화 알고리즘을 적용하여 디지털 음성DNA 정보로 부호화하는 단계를 포함하는 음성합성 방법. |
| 11 | 제8항에 있어서,상기 음성DNA 재조합 단계는,상기 화자들로부터 상기 음성DNA 부호화 단계에서 획득된 상기 음성DNA 정보를 읽는 단계; 및상기 화자들의 음성DNA 정보를 조건을 만족하는 기설정된 비율로 서로 재조합하여 목표화자 음성DNA 정보를 합성하는 단계를 포함하는 음성합성 방법. |
| 12 | 제8항에 있어서,상기 음성DNA 복호화 단계는,상기 부호화된 음성DNA 정보를 읽는 단계;상기 음성DNA 부호화 단계에서 적용한 압축 부호화 알고리즘에 대응하는 복호화 알고리즘을 선택적으로 적용하여 음성DNA 정보가 음성모델정보일 경우에 해당 음성모델정보를 복원하는 단계; 및상기 음성DNA 부호화 단계에서 적용한 압축 부호화 알고리즘에 대응하는 복호화 알고리즘을 선택적으로 적용하여 음성DNA 정보가 음색변환정보일 경우 해당 음색변환정보를 복원하는 단계를 포함하는 음성합성 방법. |
| 13 | 제8항에 있어서,상기 목표화자 음성모델 생성 단계는,상기 복호화된 음성DNA 정보가 상기 음색변환정보일 경우에, 음색변환정보와 상기 기준화자 음성모델을 읽는 단계;상기 음색변환정보를 변환 파라메터로 활용하여 최대우도선형회귀 기법을 적용하여 기준화자 음성모델을 목표화자 음성모델로 변환하는 단계; 및상기 음색변환정보를 변환 파라메터로 활용하여 i-vector 기법으로 기준화자 음성모델을 목표화자 음성모델로 변환하는 단계를 포함하는 음성합성 방법. |
| 14 | 제8항에 있어서,상기 목표화자 음성합성 단계는,상기 목표화자 음성모델을 읽고, 임의의 텍스트 정보를 입력받는 단계; 및상기 텍스트에 해당하는 음성파형을 HMM 기반 합성 기법에 의해 합성하는 단계를 포함하는 음성합성 방법 |
| 15 | 컴퓨터 시스템이 음성을 합성하도록 제어하는 명령(instruction)을 포함하는 컴퓨터 판독가능 매체로서, 상기 명령은, 기준화자 음성모델에 특정화자가 발성한 음성데이터를 사용하는 화자적응 기법을 적용하여 특정화자의 음색으로 음성모델을 변환하는 음색변환 단계;상기 음색변환 단계에서 변환된 특정화자의 음성모델이나 특정화자의 음색을 나타내도록 음성모델을 변환시키는 정보를 음성DNA 정보로 부호화하는 음성DNA 부호화 단계;상기 부호화된 복수의 화자들의 음성DNA 정보를 기설정된 비율로 재조합하여 목표화자 음성DNA 정보를 합성하는 음성DNA 재조합 단계;상기 음성DNA 부호화 단계에서 획득된 특정화자 음성DNA 정보나 상기 음성DNA 재조합 단계에서 획득된 목표화자 음성DNA 정보를 복호화하여 음색변환정보나 음성모델을 복원하는 음성DNA 복호화 단계;상기 복원된 특정화자 음색변환정보를 활용하는 화자적응 기법을 기준화자 음성모델에 적용하여 목표화자 음성모델을 생성하는 목표화자 음성모델 생성 단계; 및임의의 텍스트 입력에 대해 상기 목표화자 음성모델 생성 단계로부터 획득된 목표화자 음성모델을 활용하여 목표화자 음색의 음성파형을 합성하는 목표화자 음성합성 단계를 포함하는 방법에 의하여 상기 컴퓨터 시스템을 제어하는, 컴퓨터 판독가능 저장 매체. |