| 번호 | 청구항 |
|---|---|
| 10 | 제 9 항에 있어서, 상기 소정 임계값은, 0 보다 크고 1보다 작은 값인 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 시스템. |
| 11 | 삭제 |
| 12 | 다종 웹 서버 간 유사 사용자 추출 방법에 있어서, (a) 사용자 프로필 벡터 생성부(100)가 태그 데이터를 수집하여, 각 태그의 중요도를 표준화 계산하고, 계산된 표준화 정보를 바탕으로 각 사용자에 관한 프로필 벡터를 생성하는 과정; (b) 사용자 유사도 계산부(200)가 상기 사용자 프로필 벡터 생성부(100)를 통해 생성된 각 사용자의 프로필 벡터를 이용하여, 사용자 유사도를 계산하는 과정; (c) 상기 유사 사용자 추출부(300)가 상기 사용자 유사도 계산부(200)를 통해 계산된 특정 두 사용자의 유사도 값이 소정 임계값 이상인지 여부를 판단하는 과정; 및 (d) 상기 (c) 과정의 판단결과, 소정 임계값 이상일 경우 상기 유사 사용자 추출부(300)가 두 사용자를 유사 사용자로 판단하여 추출하는 과정; 을 포함하되, 상기 (a) 과정은, (a-1) 상기 사용자 프로필 벡터 생성부(100)가 각종 웹 서버의 서비스들에 대한 개인 사용자들이 사용한 태그 데이터를 수집하는 단계; (a-2) 상기 사용자 프로필 벡터 생성부(100)가 사용자 각 개인이 태그를 사용한 횟수를 표준화함으로써 표준화 제수를 계산하는 단계; (a-3) 상기 사용자 프로필 벡터 생성부(100)가 각 태그가 사용된 횟수와, 표준화 제수의 비로서, 각 태그의 표준화된 사용횟수를 계산하는 단계; 및 (a-4) 상기 사용자 프로필 벡터 생성부(100)가 상기 (a-3) 단계를 통해 계산된 각 태그의 표준화된 사용횟수를 바탕으로, 사용자 프로필 벡터를 생성하는 단계;를 포함하는 것을 특징으로 하되, 상기 태그 데이터는, 웹 서비스에서 사용자가 음악, 일기, 북마크, 사진, 동영상을 포함하는 각종 컨텐츠를 만드는데 사용한 데이터로서, 해당 태그와 태그의 사용횟수가 기록되는 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 방법. |
| 13 | 삭제 |
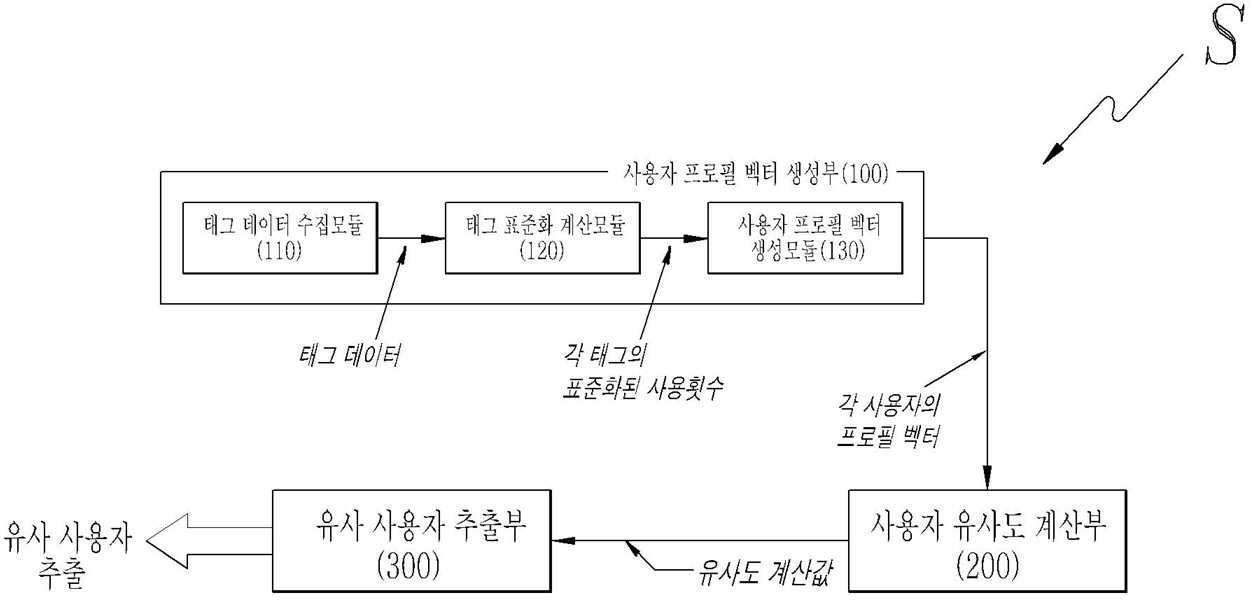
| 1 | 다종 웹 서버 간 유사 사용자 추출 시스템(S)에 있어서, 태그 데이터를 수집하여, 각 태그의 중요도를 표준화 계산하고, 계산된 표준화 정보를 바탕으로, 각 사용자에 관한 프로필 벡터를 생성하는 사용자 프로필 벡터 생성부(100); 상기 사용자 프로필 벡터 생성부(100)를 통해 생성된 각 사용자의 프로필 벡터를 이용하여, 사용자 유사도를 계산하는 사용자 유사도 계산부(200); 및 상기 사용자 유사도 계산부(200)를 통해 계산된 사용자 유사도 값을 이용하여, 유사 사용자를 추출하는 유사 사용자 추출부(300); 를 포함하되, 상기 태그 데이터는, 웹 서비스에서 사용자가 음악, 일기, 북마크, 사진, 동영상을 포함하는 각종 컨텐츠를 만드는데 사용한 데이터로서, 해당 태그와 태그의 사용횟수가 기록되는 것을 특징으로 하며, 상기 사용자 프로필 벡터는, 사용자가 사용한 태그의 종류의 수와 같은 차원을 갖는 값으로서, 각 태그의 표준화된 사용횟수를 각 요소로 갖는 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 시스템. |
| 2 | 제 1 항에 있어서, 상기 사용자 프로필 벡터 생성부(100)는, 각종 웹 서버와 연동되어, 상기 웹 서버의 서비스 상에서 개인 사용자들이 사용한 태그 데이터를 수집하는 태그 데이터 수집모듈(110); 상기 태그 데이터 수집모듈(110)을 통해 수집한 태그 데이터를 이용하여, 사용자 각 개인이 태그를 사용한 횟수를 표준화하고, 각 태그의 표준화된 사용횟수를 계산하는 태그 표준화 계산모듈(120); 및 상기 태그 표준화 계산모듈(120)을 통해 계산된 각 태그의 표준화된 사용횟수를 바탕으로, 사용자 프로필 벡터를 생성하는 사용자 프로필 벡터 생성모듈(130); 을 포함하는 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 시스템. |
| 3 | 제 2 항에 있어서, 상기 태그 표준화 계산모듈(120)은, 사용자 U1 이 태그 T1, T2, T3 를 사용한 경우, 상기 사용자 U1 이 태그를 사용한 횟수를, 하기의 [수식 1] 을 통해 표준화 계산하는 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 시스템. [수식 1] |
| 4 | 제 2 항에 있어서, 상기 태그 표준화 계산모듈(120)은, 사용자 U1 이 태그 T1, T2, T3 를 사용한 경우, 상기 사용자 U1 이 갖는 태그 T1 에 대한 표준화 사용횟수를, 하기의 [수식 2] 를 통해 계산하는 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 시스템. [수식 2] |
| 5 | 삭제 |
| 6 | 제 2 항에 있어서, 상기 사용자 프로필 벡터 생성모듈(130)은, 사용자 U1 이 태그 T1, T2, T3 를 사용한 경우, 상기 사용자 U1 의 프로필 벡터를, 하기의 [수식 3] 을 통해 계산하는 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 시스템. [수식 3] |
| 7 | 제 1 항에 있어서, 상기 사용자 유사도 계산부(200)는, 두 사용자의 사용자 프로필 벡터의 코사인 벡터 곱인 하기의 [수식 4] 를 통해 사용자 유사도를 계산하는 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 시스템. [수식 4] |
| 8 | 제 7 항에 있어서, 상기 사용자 유사도 계산부(200)는, 두 사용자 유사도 값을, 두 사용자간 겹치는 태그가 없으면 0 으로, 두 사용자간 사용자 프로필 벡터가 일치하면 1 로 계산하는 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 시스템. |
| 9 | 제 1 항에 있어서, 상기 유사 사용자 추출부(300)는, 상기 사용자 유사도 계산부(200)를 통해 계산된 특정 두 사용자의 유사도 값이 소정 임계값 이상인지 여부를 판단하여, 소정 임계값 이상일 경우, 두 사용자를 유사 사용자로 판단하여 추출하는 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 시스템. |
| 14 | 제 12 항에 있어서, (d-1) 상기 (c) 과정의 판단결과, 소정 임계값 이상이 아닐 경우 상기 유사 사용자 추출부(300)가 프로세스를 종료하는 단계; 를 더 포함하는 것을 특징으로 하는 다종 웹 서버 간 유사 사용자 추출 방법. |